










无监督学习的核心思想是构建出一个与待测样本最相近的“模板”与之比较,根据像素或特征的差异性实现缺陷得到检出与定位,根据维度不同,分为两种方法:
(1)基于图像相似度的方法
该方法在图像像素层面进行比较,核心思想是重建出与输入样本最相近的正常图像,二者仅在缺陷区域有差别。生成图与输入图之间的差异可以表示缺陷存在的概率,既可以判断图像是否异常,也可以选取阈值实现缺陷分割。
常使用:自编码器、变分自编码器、生成对抗模型,常用AE和GAN结合
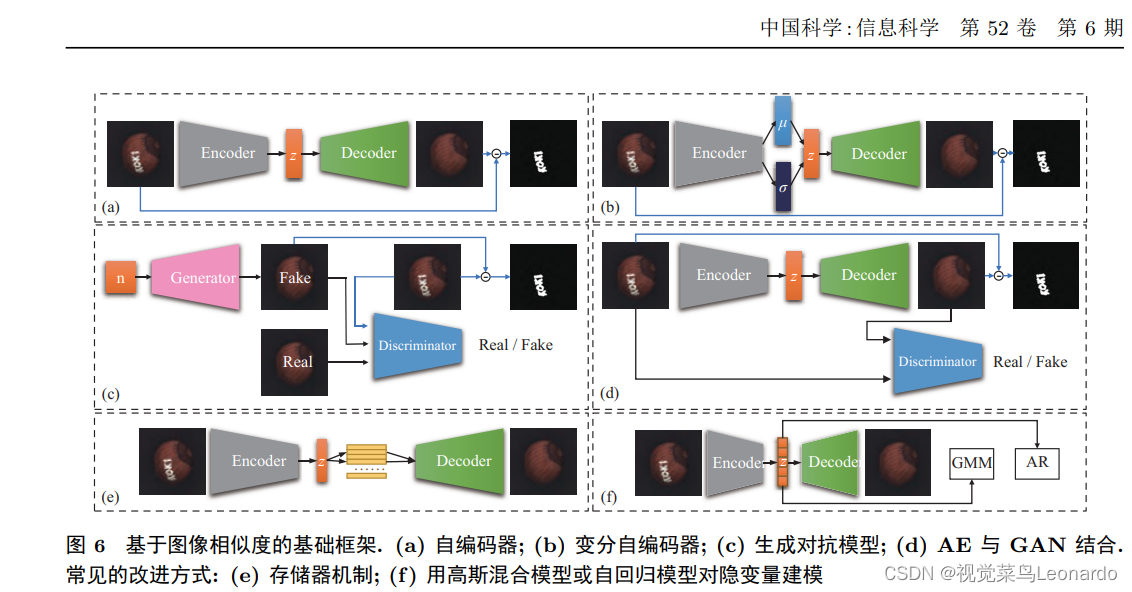
其中根据模型优化目标不同,可以分为基于图像重建和基于图像恢复
(i)基于图像重建的方法:由于模型的参数只通过正常样本训练得到,模型只能较好的重建正常样本,在非正常样本的缺陷区域会产生较大的重建误差,因此重建图像的质量对缺陷检测性能影响巨大。思路:提升重建质量,使得重建图像与输入图像的像素仅在缺陷区域存在明显差异,而在正常区域几乎一致。
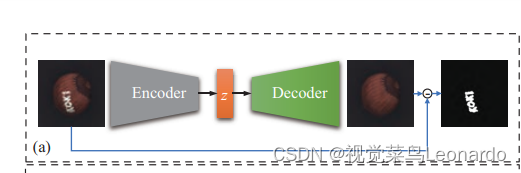
AE采用编码器-解码器结构,编码器将图像编码为z,解码器利用z重建图像,根据误差即可实现缺陷定位,但是在重建时存在模糊现象,因此在计算重建误差时,容易造成正常像素点的误检。(重建后的图像,除了缺陷部位都完成重建与原图相同,缺陷部位未能完成重建,差异部分为缺陷)
提升重建图像质量:MS-FCAE 和 DFR 针对多尺度特征信息进行了相 关设计, 为图像的重建提供了不同粒度的上下文信息, 使得重建图像更加准确清晰.
利用去模糊效应,将输入图像风格化:在 AE 的基础上 引入了风格蒸馏分支, 该网络模拟了 AE 的模糊效应, 将原始图像转换为与重建图像具有同样风格的 图像, 以达到对齐的目的.
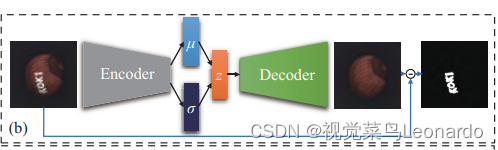
VAE通过编码器将正常图像映射到隐空间的先验分布,从对应分布中随机采样得到变量z,再利用解码器将z映射回图像空间。但是VAE难以获得清晰且一致的重建图像
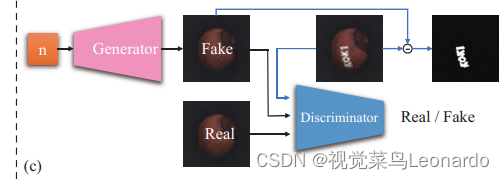
GAN可以声场更加清晰的高质量图像,由生成器和判别器组成,生成器-判别器的对抗训练机制是GAN生成清晰图像的关键。AnoGAN是首个将 GAN 引入缺陷检测的方法。
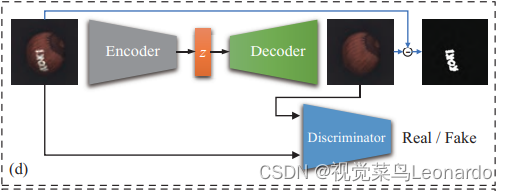
AE或VAE与GAN结合逐渐流行,推理阶段根据生成图像和输入图像的重构误差以及两者的编码误差来进行缺陷检测。
但是,基于图像重建的方法假设并不完全可靠,即使在正常样本上训练,模型仍可能将未见过的缺陷完整重建。可能有以下原因:AE 等模型具有较大的容量; 缺陷与正常区域的 特征差别不明显。

基于内存(Memory)的改进旨在利用额外的空间开销来保证模型能够重建出正常图像,在编码器后引入Memory存储正常训练样本的特征,推理时将待测图像的样本特征与Memory中的特征进行匹配并重建。
MemoryAE:编码器提取输入图像的特征 z 后, 在 Memory 中检索若干项与 z 最相关内存项, 并根据相似度进行重组后得到 zˆ, 将 zˆ 送入解码器中进行重建。
为了防止异常样本的特征存储到Memory中,TrustMAE体处理一种基于信任区间的Memory更新机制:设定一个阈值r作为每一个存储项的信任区间, 只有当提取的特征与存储项的距离小于 r 时, 才将提取的特征存入Memory中, 当训练集中混入了少量异常样本时, TrustMAE 的缺陷 检测性能远远优于 MemoryAE.
总结:基于图像重建的方法简单直观,不需要对训练集数据进行复杂的预处理,但是存在以下问题:
①输入与输出难以保持对齐,例如图像风格不一致或者存在偏移,且对噪声鲁棒性不佳,在计算输出与输入的差异时,很容易造成像素级别的误检
②AE等模型仍然可能泛化到缺陷,甚至退化成恒等映射,即输入和输出趋于一致,此时不具备异常检测能力。Memory减少了这种情况,但通常会存储大量的正常样本特征,消耗大量内存和时间。
(ii)基于图像恢复的方法:此方法将缺陷视为噪声,将图像恢复视作去噪过程。核心思想是在正常图像加入缺陷后,训练网络模型将其恢复为对应的原始图像,常用的模型包括AE和UNet,模型具有根据上下文消除缺陷的能力,测试阶段利用恢复图像和输入图像的重建误差进行缺陷分割,此类方法能在一定程度上避免恒等映射问题。
比较常用的方法是直接在原图上叠加掩膜,训练网络恢复被掩膜覆盖的内容。Haselmann等 给 正常样本随机添加矩形的掩膜以模拟真实缺陷, 但是该方法容易使模型过拟合到矩形缺陷上, 当测试集合中出现其他形状的缺陷时, 模型可能无法将其消除。为了防止模型过拟合到训练阶段添加的缺陷上, Li等随机选择图像的超像素作为掩膜用于训练模型。在推理阶段, 将超像素逐个遮住, 然后 利用模型将其一一还原. 然而, 一幅图像中可能存在数以万计的超像素点, 因而模型要进行数万次的前向传播, 计算量极高.
多尺度的常规样式掩膜,使用图像金字塔结构, 将图像放缩到 3 个不同的尺 度并随机加噪之后, 输入到对应的 AE 中进行恢复, 测试阶段将 3 个尺度的分割结果融合得到最终的 缺陷分割图;另一种方法将图像划分为多个正方形区域,并随机将其划分为多个子集,从而得到多个包含随机正方形掩膜的图像。
总结:基于图像恢复的方法将缺陷还原成正常像素,可以促进模型更好地学习图像的上下文信息,有助于检测结构缺陷,但是对人工缺陷的设计具有较高的要求,否则容易过拟合到特定的缺陷形态上,且效率低,计算复杂,难以落地。
(2)基于特征相似度的方法
基于图像相似度的方法简单直观,但是很难实现理想的重建效果。通过高维特征实现更加鲁棒的检测,借助深度神经网络的特征提取能力,核心是找到具有区分性的特征嵌入,减少无关特征的干扰。CNN包含了局部感受野的信息,并不需要严格的空间对齐。
(i)深度一类分类
利用深度神经网络构造质量更高的特征空间,然后构造分类界面:
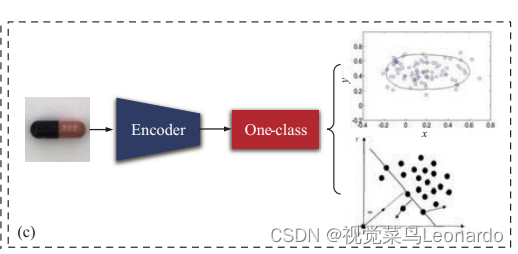
训练时通过神经网络提取正常图像的特征,并让提取出的正常图像的特征向量尽可能的分布紧凑,测试时模型提取待测样本的特征并映射到上述特征空间,根据分类洁面判断测试样本是否异常。
问题是需要大量内存!!!!!
早期的混合式方法分两阶段进行,首先利用自编码网络学习正常样本特征,第二阶段固定自编码器参数,再用OC-SVM等方法对特征编码构建分界面。
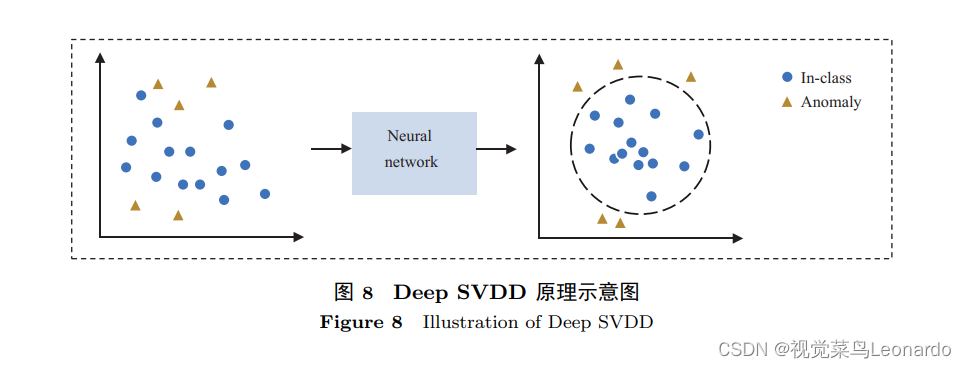
(ii)特征距离度量
深度一类分类方法需要找到合适的子空间与分界面,但是对于复杂数据是困难的。特征距离度量的方法无需优化分界面,而是在特征空间匹配相应的“正常模板”,直接与待测样本的特征比较。单纯使用正样本训练的特征提取器虽然可以 学到正常样本的共性特征, 但是却无法学到缺陷的特征, 导致模型不具区分性。适用于训练模型来描述图像的特征,通过在大型数据集上进行预训练。度量形式主要有两种:基于向量的距离、基于分布的距离。
最好的方法是匹配到与待测图像最相近的正常模板进行比较。
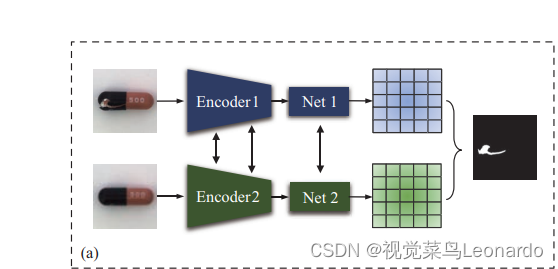
使用参数相同的具有区分力的特征提取网络将多个输入图像映射到特征空间,特征仅在缺陷区域差别明显。
SPADE基于k最近邻,首先在ImageNet上预训练的CNN模型提取训练集的特征向量来构建正常样本数据库,然后使用KNN法检索与待测样本予以最相似的k个正常样本,最后采用特征金字塔匹配进行多处对特征对齐,特别适用于固定机位的工业检测场景。但是时间长、计算复杂。
基于深度统计模型的方法对正常样本的特征进行概率分布建模,从而无需建立庞大的正常样本库。
另一种方法是将同一张测试图像按照不同的方式映射到特征空间,对缺陷区域的映射结果差别很大。
教师-学生框架,使用知识蒸馏将大型预训练网络的表征能力迁移到轻量的教师网络中,仅在正常数据集上训练多个随机初始化的学生网络,使他们对正常样本的表达与教师网络相同。学生和教师网络对缺陷的表达具有较大的回归误差。
现在开始进行完全无监督设置,训练集混杂了正常与缺陷样本,并且没有任何标注,提高对异常样本的鲁棒性
完全无监督:Tan D S, Chen Y C, Chen T P C, et al. TrustMAE: a noise-resilient defect classification framework using memoryaugmented auto-encoders with trust regions. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021. 276–285
Li T, Wang Z, Liu S, et al. Deep unsupervised anomaly detection. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021. 3636–3645















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









