







 操作系统中的CPU调度是通过在进程之间切换提高系统吞吐率。调度算法包括非抢占的先到先服务(FCFS)、最短作业优先(SJF)、抢占式优先级调度和轮转法(RR)。多级队列调度结合不同类型的进程需求,多级反馈队列调度允许进程在队列间移动以应对不同CPU需求。多处理器调度则涉及负载平衡和处理器亲和性。线程调度则分为用户线程和内核线程,调度策略包括进程竞争范围(PCS)和系统竞争范围(SCS)。
操作系统中的CPU调度是通过在进程之间切换提高系统吞吐率。调度算法包括非抢占的先到先服务(FCFS)、最短作业优先(SJF)、抢占式优先级调度和轮转法(RR)。多级队列调度结合不同类型的进程需求,多级反馈队列调度允许进程在队列间移动以应对不同CPU需求。多处理器调度则涉及负载平衡和处理器亲和性。线程调度则分为用户线程和内核线程,调度策略包括进程竞争范围(PCS)和系统竞争范围(SCS)。
CPU调度
基本概念
多道程序操作系统的基础。通过在进程之间切换CPU,操作系统可以提高计算机的吞吐率。
对于单处理器系统,每次只允许一个进程运行:任何其他进程必须等待,直到CPU空闲能被调度为止。
CPU-I/O 区间周期
CPU的成功调度依赖于进程的如下属性:
进程执行由CPU执行周期和I/O等待周期组成。进程在这两个状态之间切换(CPU burst—I/O bust)。
进程执行从CPU区间(CPU burst)开始,在这之后是I/O区间(I/O burst)。接着另外一个CPU区间,然后是另外一个I/O区间,如此进行下去,最终,最后的CPU区间通过系统请求中止执行。
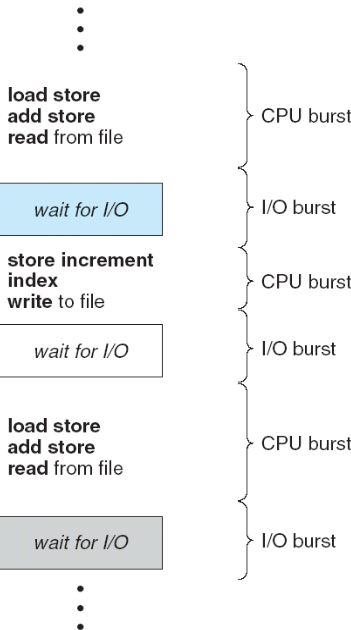
经过大量CPU区间的长度的测试。发现具有大量短CPU区间和少量长CPU区间。I/O约束程序通常具有很多短CPU区间。CPU约束程序可能有少量的长CPU区间。这种分布有助于选择合适的CPU调度算法。
CPU程序调度
每当CPU空闲时,操作系统就必须从就绪队列中选择一个进程来执行。进程选择由短期调度程序(short-term scheduler)或CPU调度程序执行。调度程序从内存中选择一个能够执行的进程,并为之分配CPU。
就绪队列不必是先进先出(FIFO)队列,也可为优先队列、树或简单的无序链表。不过队列中所有的进程都要排队以等待在CPU上运行。队列中的记录通常为进程控制块(PCB)。
抢占调度
CPU调度决策可在如下4种情况环境下发生:
(1)当一个进程从运行切换到等待状态(如:I/O请求,或者调用wait等待一个子进程的终止)
(2)当一个进程从运行状态切换到就绪状态(如:出现中断)
(3)当一个进程从等待状态切换到就绪状态(如:I/O完成)
(4)当一个进程终止时
对于第1和4两种情况,没有选择而只有调度。一个新进程(如果就绪队列中已有一个进程存在)必须被选择执行。对于第2和第3两种情况,可以进行选择。
当调度只能发生在第1和4两种情况下时,称调度是非抢占的(nonpreemptive)或协作的(cooperative);否则,称调度方案为抢占的(preemptive)。采用非抢占调度,一旦CPU分配给一个进程,那么该进程会一直使用CPU直到进程终止或切换到等待状态。
抢占调度对访问共享数据是有代价(如加锁)的,有可能产生错误,需要新的机制(如,同步)来协调对共享数据的访问。
抢占对于操作系统内核的设计也有影响。在处理系统调用时,内核可能忙于进程活动。这些活动可能涉及要改变重要内核数据(如I/O队列)。
因为根据定义中断能随时发生,而且不能总是被内核所忽视,所以受中断影响的代码段必须加以保护以避免同时访问。操作系统需要在任何时候都能够接收中断,否则输入会丢失或输出会被改写。为了这些代码段不被多个进程同时访问,在进入时就要禁止中断,而在退出时要重新允许中断。
分派程序
分派程序(dispatch)是一个模块,用来将CPU的控制交给由短期调度程序选择的进程。
其功能包括:
- 切换上下文
- 切换到用户模式
- 跳转到用户程序的合适位置,以重新启动程序。
分派程序停止一个进程而启动另一个所花的时间成为分派延迟。
Dispatch latency – time it takes for the dispatcher to stop one process and start another running.
调度准则
为了比较CPU调度算法所提出的准则:
- CPU使用率 : 需要使CPU尽可能忙
- 吞吐量 : 指一个时间单元内所完成进程的数量
- 周转时间 :从进程提交到进程完成的时间段称为周转时间,周转时间是所有时间段之和,包括等待进入内存、在就绪队列中等待、在CPU上执行和I/O执行
- 等待时间 : 在就绪队列中等待所花费时间之和
- 响应时间 : 从提交请求到产生第一响应的时间
需要使CPU使用率和吞吐量最大化,而使周转时间、等待时间和响应时间最小化。绝大多数情况下需要优化平均值,有时需要优化最大值或最小值,而不是平均值。
调度算法
先到先服务调度(First-Come,First-Served scheduling)
最简单的CPU调度算法是先到先服务算法(First-Come,First-Served scheduling):先请求CPU的进程先分配到CPU。FCFS策略可以用FIFO队列来容易实现。当一个进程进入就绪队列,其PCB链接到队列的尾部。当CPU空闲时,CPU分配给位于队列头的进程,接着运行进程从队列中删除。
FCFS策略的代码编写简单且容易理解,不过采用FCFS策略的平均等待时间通常比较长。当进程CPU区间时间变化很大,平均等待时间会变化很大。
比如以下例子
| 进程 | 区间时间 |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
如果按照 P1P2P3 顺序到达,Gantt图如下:

平均等待时间: 0+24+273=17
如果按 P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3520
3520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









