









1. 决策树概述
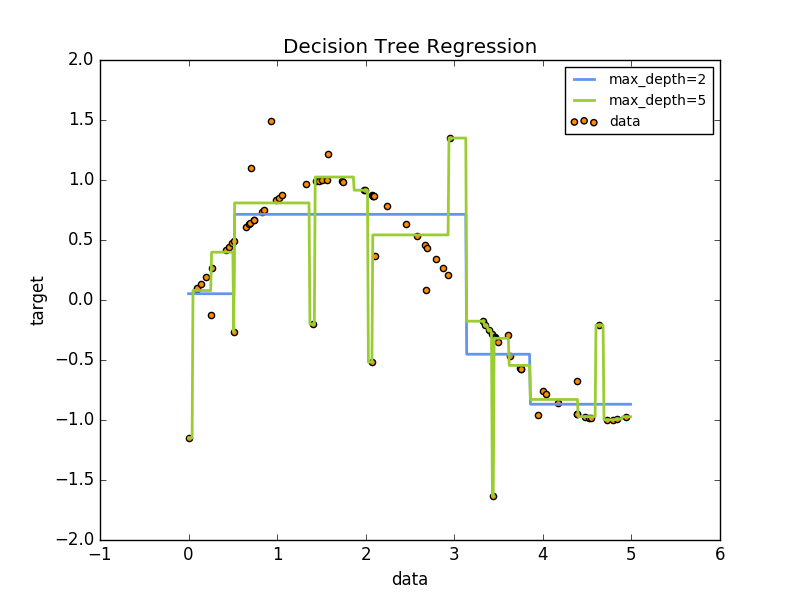
决策树是一个非参数的监督式学习方法,主要用于分类和回归。算法的目标是通过推断数据特征,学习决策规则从而创建一个预测目标变量的模型。如下图所示,决策树通过一系列if-then-else 决策规则 近似估计一个正弦曲线。
1.1 决策树的优势
决策树具有以下优势:
- 简单易懂,原理清晰,决策树可以实现可视化;
- 数据准备简单。其他的方法需要实现数据归一化,创建虚拟变量,删除空白变量;
- 使用决策树的代价是数据点的对数级别;
- 能够处理数值和分类数据;
- 能够处理多路输出问题;
- 使用白盒子模型(内部结构可以直接观测的模型)。一个给定的情况是可以观测的,那么就可以用布尔逻辑解释这个结果。相反,如果在一个黑盒模型(ANN),结果可能很难解释;
- 可以通过统计学检验验证模型。这也使得模型的可靠性计算变得可能;
1.2 决策树的劣势
- 可能会建立过于复杂的规则,即过拟合。为避免这个问题,剪枝、设置叶节点的最小样本数量、设置决策树的最大深度有时候是必要的;
- 决策树有时候是不稳定的,因为数据微小的变动,可能生成完全不同的决策树。 可以通过总体平均(ensemble)减缓这个问题。应该指的是多次实验;
- 学习最优决策树是一个NP完全问题。所以,实际决策树学习算法是基于试探性算法,例如在每个节点实现局部最优值的贪心算法。这样的算法是无法保证返回一个全局最优的决策树。可以通过随机选择特征和样本训练多个决策树来缓解这个问题;
- 有些问题学习起来非常难,因为决策树很难表达。如:异或问题、奇偶校验或多路复用器问题;
- 如果有些因素占据支配地位,决策树是有偏的。因此建议在拟合决策树之前先平衡数据的影响因子。
2. 决策树分类
DecisionTreeClassifier 能够实现多类别的分类。输入两个向量:向量X,大小为[n_samples,n_features],用于记录训练样本;向量Y,大小为[n_samples],用于存储训练样本的类标签。
>>> from sklearn import tree
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, Y)
>>> clf.predict([[2., 2.]])
>>> clf.predict_proba([[2., 2.]]) #计算属于每个类的概率能够实现二进制分类和多分类。使用Isis数据集:
>>> from sklearn.datasets import load_iris
>>> from sklearn import tree
>>> iris = load_iris()
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(iris.data, iris.target)
# export the tree in Graphviz format using the export_graphviz exporter
>>> with open("iris.dot", 'w') as f:
>>> f = tree.export_graphviz(clf, out_file=f)
# predict the class of samples
>>> clf.predict(iris.data[:1, :])
# the probability of each class
>>> clf.predict_proba(iris.data[:1, :])安装Graphviz将其添加到环境变量,使用dot创建一个PDF文件。dot -Tpdf iris.dot -o iris.pdf
# 删除dot文件
>>> import os
>>> os.unlink('iris.dot')如果安装了pydotplus,也可以在Python中直接生成:
>>> import pydotplus
>>> dot_data = tree.export_graphviz(clf, out_file=None)
>>> graph = pydotplus.graph_from_dot_data(dot_data)
>>> graph.write_pdf("iris.pdf")可以根据不同的类别输出不同的颜色,也可以指定类别名字:
>>> from IPython.display import Image
>>> dot_data = tree.export_graphviz(clf, out_file=None,
>>> feature_names=iris.feature_names,
>>> class_names=iris.target_names,
>>> filled=True, rounded=True,
>>> special_characters=True)
>>> graph = pydotplus.graph_from_dot_data(dot_data)
>>> Image(graph.create_png())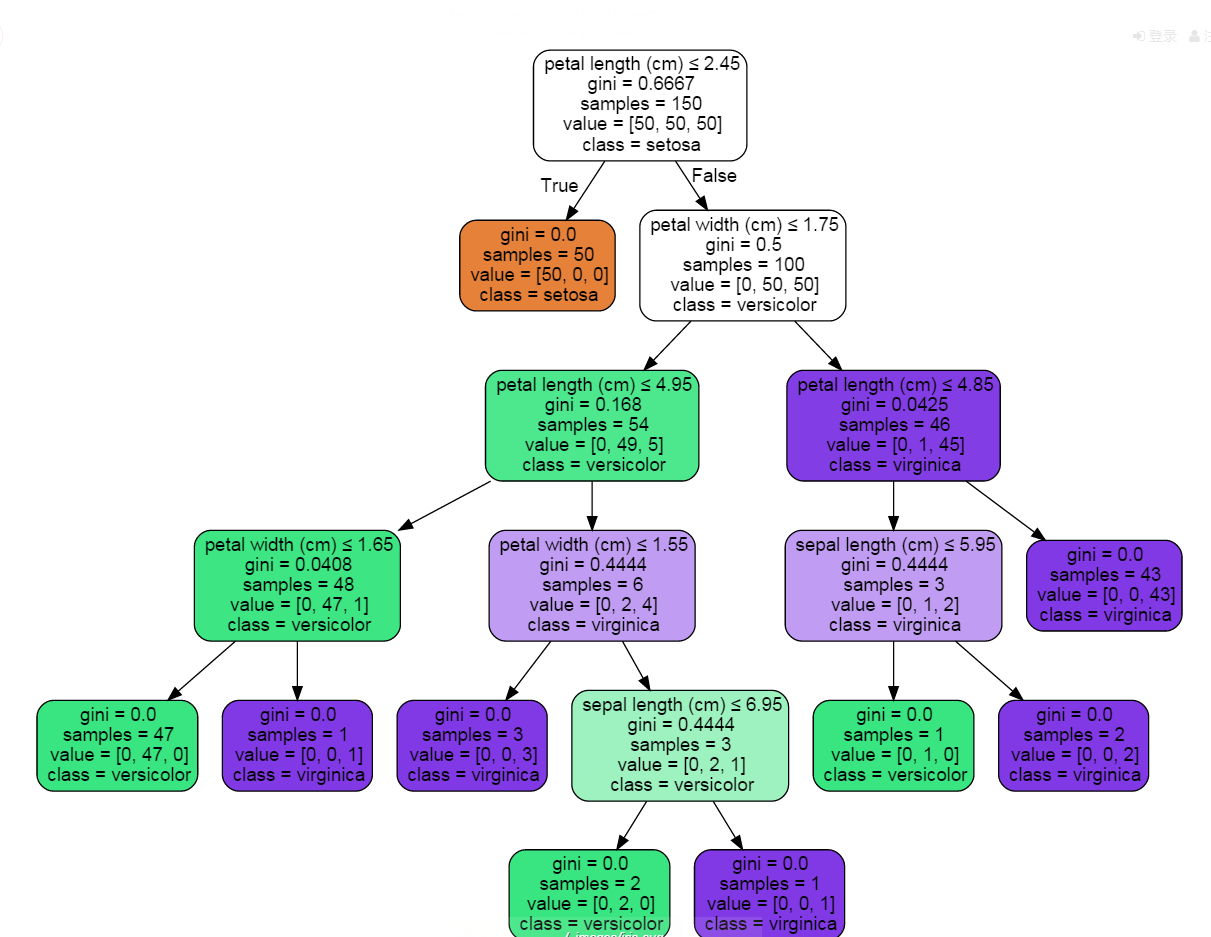
3. 决策树回归
和分类不同的是向量y可以是浮点数:
>>> from sklearn import tree
>>> X = [[0, 0], [2, 2]]
>>> y = [0.5, 2.5]
>>> clf = tree.DecisionTreeRegressor()
>>> clf = clf.fit(X, y)
>>> clf.predict([[1, 1]])本文前面提到的例子:
# Import the necessary modules and libraries
>>> import numpy as np
>>> from sklearn.tree import DecisionTreeRegressor
>>> import matplotlib.pyplot as plt
# Create a random dataset
>>> rng = np.random.RandomState(1)
>>> X = np.sort(5 * rng.rand(80, 1), axis=0)
>>> y = np.sin(X).ravel()
>>> y[::5] += 3 * (0.5 - rng.rand(16))
>>> # Fit regression model
>>> regr_1 = DecisionTreeRegressor(max_depth=2)
>>> regr_2 = DecisionTreeRegressor(max_depth=5)
>>> regr_1.fit(X, y)
>>> regr_2.fit(X, y)
# Predict
>>> X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
>>> y_1 = regr_1.predict(X_test)
>>> y_2 = regr_2.predict(X_test)
# Plot the results
>>> plt.figure()
>>> plt.scatter(X, y, c="darkorange", label="data")
>>> plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
>>> plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
>>> plt.xlabel("data")
>>> plt.ylabel("target")
>>> plt.title("Decision Tree Regression")
>>> plt.legend()
>>> plt.show()4. 多输出问题
多输出问题时需要预测多个输出的监督式学习问题。即Y是一个2d的向量,大小为[n_samples, n_outputs]。
当输出之间不相关时,一个简单的解决办法是建立n个独立模型。对于每一个输出,使用这些模型独立预测这每个输出。由于输出是和相同的输入相关的,所以一个更好的办法是建立一个能够持续预测所有输出的单一模型。首先,系统需要的训练时间更少了,因为只建立了一个模型。其次准确性也会得到提高。
决策树的策略需要修改以支持多分类问题:
- 叶子上存储n个输出变量;
- 使用不同的标准计算所有n输出的平均减少。
这一节是关于 DecisionTreeClassifier 和DecisionTreeRegressor的一些知识点。如果一个决策树的输出向量Y大小为[n_samples, n_outputs],预测量有:
- predict:输出n个预测值
- predict_proba:输出有n个输出的向量组成的列表















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









