





 Staple算法结合了模板和直方图分数,通过在线最小二乘优化实现模型自适应,对颜色变化和形变具有鲁棒性,能在80FPS以上运行速度下超越其他先进跟踪器。它通过独立解决两个岭回归问题,将两种模型的分数结合,以提高精度,避免模型漂移。在VOT和OTB基准测试中表现出色,优于包括深度学习在内的多种跟踪方法。
Staple算法结合了模板和直方图分数,通过在线最小二乘优化实现模型自适应,对颜色变化和形变具有鲁棒性,能在80FPS以上运行速度下超越其他先进跟踪器。它通过独立解决两个岭回归问题,将两种模型的分数结合,以提高精度,避免模型漂移。在VOT和OTB基准测试中表现出色,优于包括深度学习在内的多种跟踪方法。
作者:
YaqiLYU
链接:https://www.zhihu.com/question/26493945/answer/156025576
来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。VOT2016竟然发生了乌龙事件,Staple在论文中是80FPS,怎么EFO在这里只有11?幸好公开代码有Staple和STAPLE+,有兴趣您可以去实测下,虽然我电脑不如Luca Bertinetto大牛,但Staple我也能跑60-70FPS,而更可笑的是,STAPLE+比Staple慢了大约7-8倍,竟然EFO高出4倍,到底怎么回事呢?首先看Staple的代码,如果您直接下载Staple并设置params.visualization = 1来跑,Staple调用Computer Vision System Toolbox来显示序列图像,而恰好如果您没有这个工具箱,默认每帧都会用imshow(im)来显示图像所以非常非常慢,而设置params.visualization = 0就跑的飞快(作者你是孙猴子派来的逗逼吗),建议您将显示图像部分代码替换成DSST中对应部分代码就可以正常跑和显示了。再来看STAPLE+的代码,改进包括额外从颜色概率图中提取HOG特征,特征增加到56通道(Staple是28通道),平移检测额外加入了大位移光流运动估计的响应,所以才会这么慢,而且肯定会这么慢。所以很大可能是VOT举办方把Staple和STAPLE+的EFO弄反了,VOT2016的实时推荐算法应该是排第5的Staple,相关滤波结合颜色方法,没有深度特征更没有CNN,跑80FPS还能排在第五,这就是接下来主要介绍的,2016年最NIUBILITY的目标跟踪算法之一Staple(让排在后面的一众深度学习算法汗颜,怀疑人生)。
图1:有时候颜色分布不足以区分目标与背景。相反,模板模型(如HOG)取决于对象的空间结构,并且在快速变化时表现得很差。我们的追踪器Staple可以结合模板和颜色模型的优势。例如DSST [10],其性能不受非区别性颜色的影响(上图)。例如DAT [33],它对于快速变形是鲁棒的(下图)。
摘要
基于相关滤波跟踪器的算法最近取得了出色的表现,显示出对具有运动模糊和光照变化的挑战性场景的极大鲁棒性。然而,由于他们学习的模型在很大程度上取决于跟踪对象的空间布局,所以它们对变形极其敏感。基于颜色统计的模型具有互补的特征:它们适应形状的变化,但是当整个序列中的光照不连续时会受到影响。此外,单独的色彩分布可能不足以区分。在本文中,我们展示了一个简单的跟踪器,在岭回归(ridge regression)框架中结合互补的线索,可以运行快于80FPS,胜过不仅流行的VOT14竞赛中的所有条目,而且还有最近的和更加复杂的跟踪器,根据多个基准测试。
介绍
我们考虑广泛采用的短期单目标跟踪场景,其中目标仅在第一帧中指定(使用矩形)。短期意味着不需要重新检测。在视频中跟踪不熟悉的对象的关键挑战是对其外观的变化是鲁棒的。跟踪不熟悉的对象的任务(对于这些对象而言,提前不提供训练样例)是有趣的,因为在许多情况下,获取这样的数据集是不可行的。对于在如机器人,监控,视频处理和增强现实等计算密集型应用上的算法的实时执行是有利的。
由于对象的外观在视频中可能会发生显著的变化,所以从第一帧单独估计其模型,并且使用该单个固定模型来在所有其他帧中定位对象通常是无效的。因此,大多数最先进的算法使用模型自适应来利用后期帧中存在的信息。最简单,最广泛的方法是将跟踪器在新帧中的预测视为用于更新模型的训练数据。从预测中学习的危险是小误差可能会累积并导致模型漂移。当对象的外观改变时,这尤其可能会发生。
在本文中,我们提出Staple(Sum of Template And Pixel-wise LEarners),一个跟踪器结合了两个对互补因素敏感的图像块表示方法,以学习一个对颜色变化和变形本身都鲁棒的模型。为了保持实时速度,我们解决了两个独立的岭回归问题,利用每个表示方法的固有结构。与其他融合多个模型预测的算法相比,我们的跟踪器将*密集翻译搜索(dense translation search)*中的两个模型的分数相结合,从而实现更高的精准度。两种模型的关键性质在于它们的分数在量级上是相似的,并且表明它们的可靠性,从而使预测由更加置信来决定。我们给出了令人惊讶的结果,即使以超过80 FPS的速度运行,相关滤波器(使用HOG特征)和全局颜色直方图的简单组合在多个基准测试中胜过更多复杂的跟踪器。
Related Work
Online learning and Correlation Filters:在线学习+相关滤波
现代的自适应跟踪方法通常使用一种在线版本的对象检测算法。一种实现强大结果[39]并具有优雅的表达形式的方法是Struck [16],试图最小化结构化输出用于定位[3]。然而,所需的计算限制了特征和训练示例的数量。相关滤波器则相反,最小化正样例的所有循环移位(Cyclic shifts)的最小二乘法损失。尽管这似乎是对真实问题的较弱逼近,但是它能够利用傅立叶域,实时地使用密集采样的示例和高维特征图像。最初被应用于Bolme等人的灰度图像中的自适应跟踪[5],它们扩展到多个特征通道[4,17,22,18],因此HOG特征[7]使得该技术能够在VOT14中达到最先进的性能[24]。比赛的胜利者DSST [8]使用一维相关滤波器包含了一个多尺度模板用于判别型多尺度空间跟踪。相关滤波器的一个缺点是它们被限制从所有的循环移位中学习。最近的几项工作[12,23,9]试图解决这个问题,特别是空间域正则化(SRDCF)[9]的提出表现出良好的跟踪效果。然而,这是以实时操作为代价的。
Robustness to deformation:应对形变
相关滤波器固有地受限于学习刚性模板的问题。当目标在序列过程中经历形状变形时,这是一个问题。也许实现变形鲁棒性的最简单方法是采用对形状变化不敏感的表示法。图像直方图具有此属性,因为它们丢弃每个像素的位置。事实上,直方图可以被认为与相关滤波器正交,因为相关滤波器是从循环移位学习的,而直方图对于循环移位是不变的。然而,只使用直方图通常不足以区分对象与背景。虽然颜色直方图在许多早期的对象跟踪方法中被使用[32,31],但是它们最近才在Distractor-Aware Tracker(DAT)[33]中被证明对于现代基准具有竞争力,它使用了自适应阈值和对于颜色相似的区域的显式抑制。一般来说,直方图可以由任何离散特征构成,包括局部二进制模式(LBP算子)和量化后的颜色。对于提供变形鲁棒性的直方图,该特征必须对所产生的局部变化不敏感。
实现变形鲁棒性的主要替代方法是学习可变形模型。我们认为从单一视频中学习可变形模型是非常有意义的,唯一的监督是第一帧中的位置,因此采用一个简单的边界框。虽然我们的方法在基准测试中胜过近期复杂的基于局部的模型[6,40],但是可变形模型具有更丰富的表示,而这些评估不一定会给予回报。我们的单模板跟踪器可以被认为是构建基于局部的模型的一个组件。
HoughTrack [14]和PixelTrack [11]不是使用可变形模型,而是从每个像素积累投票,然后使用投票获胜位置的像素来估计物体的范围。然而,这些方法尚未证明其具有竞争性的基准表现。
Schemes to reduce model drift:应对漂移问题
模型漂移是从不准确的预测中学习的结果。一些工作旨在通过调整训练策略来防止漂移,而不是改进预测。 TLD [21]和PROST [34]编码规则用于基于光流和传统外观模型的附加监督。其他方法避免或延迟作出艰难的决定。MIL-Track [1]使用多示例学习来训练几包(bag)的正样本。 Supancic和Ramanan [35]引入了自步学习来进行跟踪:他们解决了保持外观模型的最佳轨迹,然后使用最大置信度的帧来更新模型,并且不断重复。 Grabner等人将跟踪视为在线半监督boosting,其中在第一帧中学习的分类器为分配给稍后帧中示例的标签提供锚点。唐等[36]应用共同训练来跟踪,学习使用不同特征的两个独立SVM,然后从组合分数中获得难分样本。在这些方法中,只有MILTrack和TLD在目前的基准中被找到,并没有很强的结果。
Combining multiple estimates:结合多种估计
广泛采用的减轻不准确预测的另一个策略是将方法的综合估计结合起来,以便跟踪器的弱点相互补偿。在[27,28]中,Kwon等利用互补的基本跟踪器,通过组合不同的观察模型和运动模型,然后将其估计结合在一个采样框架中。类似地,[38]使用阶乘HMM组合了五个独立的跟踪器,对时间上的每个跟踪器的对象轨迹和可靠性建模。多专家熵最小化(MEEM)跟踪器[41]不是使用不同类型的跟踪器,而是维护过去模型的集合,并根据熵判据选择一个模型的预测。我们与这些方法有所不同,因为a)我们的两个模型都是在一个共同的框架(具体来说是岭回归)中学习,b)这使我们能够在密集搜索中直接组合两个模型的分数。
Long-term tracking with re-detection:长期跟踪及重复检测
最近的几个工作已经使用相关滤波器来解决长期跟踪问题,通过其中的重新检测对象的能力将大大提高算法的性能。长期相关跟踪器(LCT)[30]增强了一个标准的相关过滤器跟踪器,其中包括用于置信估计的附加相关滤波器和用于重新检测的随机森林,两者仅在置信帧中更新。 多存储跟踪器(MUSTer)[20]维持对象和背景的SIFT关键点的长期存储,使用关键点匹配和MLESAC来定位对象。 长期存储的置信度是使用有效数据数量来估计的,并且可以通过考虑位于矩形内的背景关键点的数量来确定遮挡。 由于我们主要考虑短期基准,而这些长期追踪器是建立在短期跟踪器上的元算法,因此在比较中没有任何价值。 注意TLD [21]和自步学习[35]算法在某些方面是非常适合于长期的跟踪问题。
提出方法
3.1 Formulation and motivation
我们采用跟踪检测范例,其中,在第t帧中,给出图像
X
t
X_t
Xt中的目标位置的矩形框
p
t
p_t
pt是从集合
S
t
S_t
St中选择的分数最大化的:
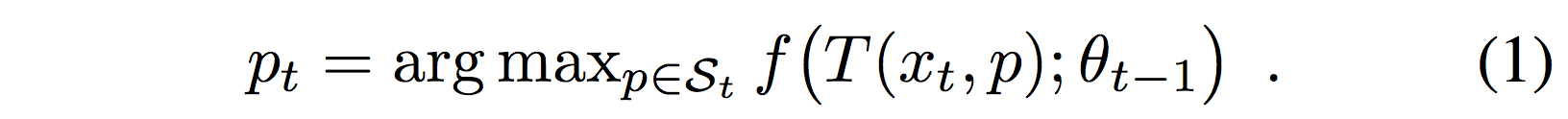
函数
T
T
T是一个图像变换,因此
f
(
T
(
x
,
p
)
;
θ
)
f(T(x,p);θ)
f(T(x,p);θ)是根据模型参数θ对于图像
x
x
x中的矩形窗口
p
p
p赋予的得分。 模型参数应该被选择使得最小化损失函数L(θ;
X
t
X_t
Xt),它取决于之前的图像以及这些图像中目标的位置
X
t
=
(
x
i
,
p
i
)
i
=
1
t
X_t = {(x_i, pi)}^t_{i=1}
Xt=(xi,pi)i=1t:
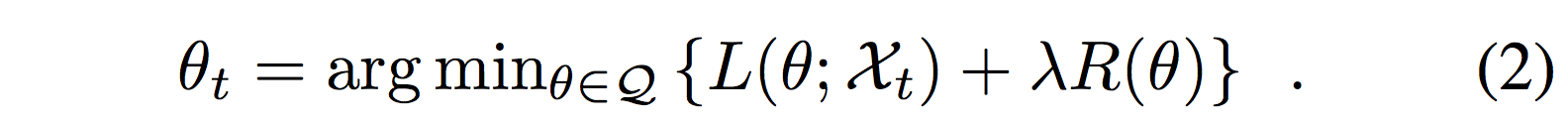
模型参数的空间表示为KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲Q。我们使用带有相对权重λ的正则项
R
(
θ
)
R(θ)
R(θ)来限制模型复杂度并防止过拟合。第一帧中对象的位置
p
1
p_1
p1已给出。为了实现实时性能,选择的函数f和L不仅需要可靠地、准确地定位目标,而且可以有效地解决(1)和(2)中的问题。
我们提出一个得分函数,它是模板和直方图分数的线性组合:
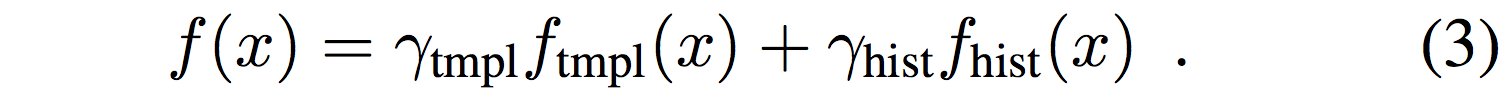
模板分数是一个K通道特征图像
ϕ
x
\phi _x
ϕx的线性函数:KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲{T}→\Bbb {R}^\r…,从
x
x
x获得并定义在有限网格上KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲T ⊂ \Bbb Z ^2:
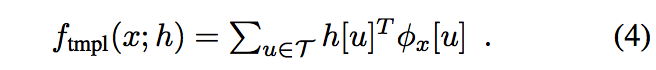
在此,权重向量(或模板)h是另一个K通道图像。直方图得分是从一个M通道特征图像
ψ
x
\psi _x
ψx计算得到的:KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲H→\Bbb R^ \rm M,从x获得并定义在(不同的)有限网格上
H
⊂
Z
2
H⊂\Bbb Z^2
H⊂Z2:
与模板分数不同,直方图得分对于其特征图像的空间排列是不变的,因此对于任何排列矩阵Π,$ g(\psi)= g(Π\psi)$。 我们采用了一个(矢量值)平均特征像素的线性函数
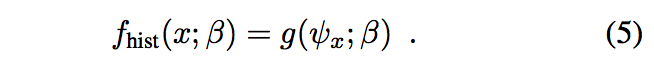
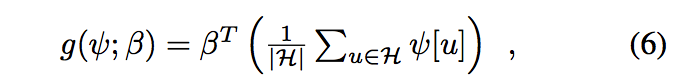
,这也可以解释为标量分数图像的平均值$ ζ_{(β,ψ)}[u] =β^Tψ[u]$
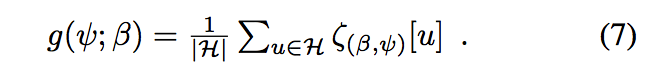
为了有效地评估在密集滑动窗口搜索中的分数函数,非常重要的是两个特征变换与平移具有交换律
ϕ
T
(
x
)
=
T
(
ϕ
x
)
\phi _{T(x)}= T(\phi x)
ϕT(x)=T(ϕx)。这不仅意味着特征计算可以通过重叠窗口共享,而且可以使用用于卷积的快速程序来计算模板分数,并且可以使用单个积分图像获得直方图分数。 如果直方图权重向量
β
β
β或特征像素
ψ
[
u
]
ψ[u]
ψ[u]稀疏,则可以进一步加速。
总体模型的参数为
θ
=
(
h
,
β
)
θ=(h,β)
θ=(h,β),因为系数
γ
t
m
p
l
γ_{tmpl}
γtmpl和
γ
h
i
s
t
γ_{hist}
γhist可以被认为是隐含在
h
h
h和
β
β
β中。将优化选择参数的训练损失假定为每张图像损失的加权线性组合:公式8
理想情况下,每张图像的损失函数应该是如下形式 ,公式9
其中 d ( p , q ) d(p, q) d(p,q)定义当正确矩形为p时选择矩形q的花费。 虽然这个函数是非凸的,但是结构化输出学习可以用来优化目标的约束[3],这是Struck的基础[16]。 然而,优化问题在计算上是昂贵的,限制了可以使用的特征数量和训练样本。 相反,相关滤波器采用简单的最小二乘法损失,但是通过将特征图像的循环移位作为样本,可以从相对大量的使用相当高维度表示的训练样本中进行学习。
图2:模板相关。第t帧,使用HOG特征表示的训练图像块在估计位置 p t p_t pt处被提取,并用于更新(21)中模型 h ^ t \hat h_t h^t的分母 d ^ t \hat d_t d^t和分子 r ^ t \hat r_t r^t,第t + 1帧中,在先前图像 p t p_t pt的位置周围提取测试图像块的特征 ϕ T ( x t + 1 , p t ) \phi _{T(x_{t+1},p_t)} ϕT(xt+1,pt),并且与(4)中的 h ^ t \hat h_t h^t进行卷积以获得密集的模板响应。直方图相关。第t帧,前景和背景区域(相对于估计位置)用于更新(26)中每个色区的频率KaTeX parse error: Undefined control sequence: \cal at position 4: ρt(\̲c̲a̲l̲ ̲O)和KaTeX parse error: Undefined control sequence: \cal at position 4: ρt(\̲c̲a̲l̲ ̲B)。这些频率使我们能够计算更新的权重 β t β_t βt。第t + 1帧中,每像素的得分在以先前图像中的位置为中心的搜索区域中计算,然后被用来有效地计算密集直方图响应,通过一个积分图像(7)。最终响应是用(3)获得的,目标的新位置 p t + 1 p_{t + 1} pt+1被估计在其峰值。最好通过颜色查看。
(这需要特征的变形与平移具有可交换的属性。)这种方法在跟踪基准取得了强大的成果[18,8],同时保持较高的帧率。
可能起初似乎是反直觉的去认为
f
t
m
p
l
f_{tmpl}
ftmpl和
f
h
i
s
t
f_{hist}
fhist不同,实际上,它是
f
t
m
p
l
f_{tmpl}
ftmpl的特殊情况,对于所有的
u
u
u,
h
[
u
]
=
β
h [u] =β
h[u]=β。 然而,由于使用统一模板获得的分数对循环移位是不变的,因此不会从循环移位中学习这样的统一模板。 因此直方图分数可以被理解为来捕获在考虑循环移位时丢失的对象外观的一个方面。
为了保持相关滤波器的速度和有效性,而不忽视由一个排列不变的直方图得分捕获的信息,我们建议通过求解两个独立的岭回归问题来学习我们的模型:
公式10
可以使用相关滤波器公式快速获得参数h。 虽然
β
β
β的维度可能小于
h
h
h,仍然可能需要更大的开销来解决它,因为不能用循环移位来学习,因此需要一般矩阵的转置而不是循环矩阵。 参数β的快速优化将在本节稍后介绍。
最后,我们采用两个分数的凸组合,设置
γ
t
m
p
l
=
1
−
α
γ_{tmpl} = 1-α
γtmpl=1−α和
γ
h
i
s
t
=
α
γ_{hist} =α
γhist=α,其中
α
α
α是在验证集上选择的参数。 我们期望,由于两个分数函数的参数都将被优化,来将分数1分配给对象,0分给其他窗口,分数的大小将是相容的,使线性组合有效。 图2是整体的学习和评估程序的视觉表示。
3.2在线最小二乘优化
采用最小二乘法损失和???二次规律器??的两个优点是可以以封闭形式获得解决方案,并且存储器的需求不随着样本数量而增长。 如果
L
(
θ
;
X
)
L(θ; X)
L(θ;X)是得分
f
(
x
;
θ
)
f(x;θ)
f(x;θ)的凸二次函数,并且
f
(
x
;
θ
)
f(x;θ)
f(x;θ)对于模型参数θ是线性的,以保持凸度,则存在矩阵
A
t
A_t
At和向量
b
t
b_t
bt使得
公式11
并且这些足以确定解决方案
θ
t
=
(
A
t
+
λ
I
)
−
1
b
t
θt ={(A_t +λI)}^{-1} b_t
θt=(At+λI)−1bt,而与
X
t
X_t
Xt的大小无关。 如果我们采用损失函数的递归定义
公式12
具有自适应率
η
η
η,那么我们可以简单地维护
公式13
其中
A
t
′
A'_t
At′ 和
b
t
′
b'_t
bt′决定了每张图片的损失通过
公式14
注意,
A
t
A_t
At表示从帧1到t估计的参数,而
A
t
′
A'_t
At′表示仅从帧t估计的参数。 我们将在这种符号上保持一致。
这些足以获得解决方案的参数通常是经济的来进行计算和存储,如果特征数量(θ的维度)很小或矩阵是冗余的(例如稀疏,低等级或Toeplitz)。Bolme等人开创了这种使用循环矩阵的相关滤波器进行自适应跟踪的技术。[5]。
3.3. Learning the template score学习模板分数
在最小二乘相关滤波器公式中,每张图像损失为
公式15
其中
h
k
h^k
hk是多通道图像h的通道k,
ϕ
\phi
ϕ是
ϕ
T
(
x
,
p
)
\phi _{T(x,p)}
ϕT(x,p)的简写,y是期望的响应(通常是在原点处具有极大值1的高斯函数),而
⋆
\star
⋆表示周期性互相关。 这对应于
ϕ
\phi
ϕ 通过δ像素的循环移位到具有二次损失的值y [δ]的线性回归。 使用
x
^
\hat x
x^来表示离散傅里叶变换
F
x
Fx
Fx,得到正则化目标
l
t
m
p
l
(
x
,
p
,
h
)
+
λ
∣
∣
h
∣
∣
2
l_{tmpl}(x,p,h)+λ||h||^2
ltmpl(x,p,h)+λ∣∣h∣∣2的最小值[22]
公式16
对于所有KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲u∈T,其中
s
^
[
u
]
\hat s[u]
s^[u]是含有元素
s
^
i
j
[
u
]
ŝ^{ij} [u]
s^ij[u]的
K
×
K
K×K
K×K矩阵,
r
^
[
u
]
\hat r [u]
r^[u]是具有元素
r
^
i
[
u
]
\hat r^i[u]
r^i[u]的K维向量。 将
s
i
j
s^{ij}
sij和
r
i
r^i
ri作为信号进行处理,这些被定义
公式17
或者,在傅里叶域,使用
∗
*
∗来表示共轭和使用
⨀
\bigodot
⨀表示元素乘法,
公式18
在实践中,Hann窗口被应用于信号来最小化学习期间的边界效应。 与计算(16)相反,我们采用DSST代码[8]中的近似值,公式19
其中
d
^
[
u
]
=
t
r
(
s
^
[
u
]
)
\hat d[u] = tr(\hat s[u])
d^[u]=tr(s^[u]) 或者公式20
这使得算法能够以大量的特征通道的同时保持快速,因为不需要对每个像素的矩阵进行因子分解。 在线版本更新是
公式21
其中 d ′ ^ \hat {d'} d′^和 r ′ ^ \hat{r'} r′^分别根据(20)和(18)获得。对于一个KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲m = | T | 像素和 K K K通道的模板,这可以在 O ( K m l o g m ) O(Km log m) O(Kmlogm)时间内执行,足够的统计数据 d ^ \hat d d^和 r ^ \hat r r^需要 O ( K m ) O(Km) O(Km) 的内存。
3.4. Learning the histogram score 学习直方图分数
理想情况下,直方图分数应该从从每个图像取得的一组样本中学习,包括正确位置作为正例。 令W表示的一组对(q, y)的集合,其中(q, y)是矩形窗口q和它们对应的回归目标y∈R,包括正例(p, 1)。 每个图像的损失是
l
h
i
s
t
(
x
,
p
,
β
)
=
l_{hist}(x, p, β)=
lhist(x,p,β)=
公式22
对于M通道的特征变换
ψ
ψ
ψ,通过求解需要
O
(
M
2
)
O(M^2)
O(M2)空间和
O
(
M
3
)
O(M^3)
O(M3)时间的M×M方程组得到解。如果特征的数量庞大,这是不可行的。虽然有矩阵分解的迭代替代,如坐标下降,共轭梯度和双坐标下降,但仍然难以实现高帧率。
相反,我们提出特殊形式
ψ
[
u
]
=
e
k
[
u
]
ψ[u] = e_k [u]
ψ[u]=ek[u]的特征,其中
e
i
e_i
ei是在索引i处为零,其他地方为零的向量,则单稀疏内积仅仅是查找
β
T
ψ
[
u
]
=
β
k
[
u
]
β^Tψ[u] =β^{k [u]}
βTψ[u]=βk[u],如在VOT13挑战中PLT方法描述的一样[26]。我们认为的特定类型的特征是量化的RGB颜色,虽然合适的替代方案是局部二值模式(LBP)。由(7)可知,直方图得分可以被认为是一个平均投票。因此,为了提高效率,我们建议对对象和背景区域KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲O和KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲B⊂\Bbb Z^2独立地对每个特征像素应用线性回归,使用每个图像的目标
l
h
i
s
t
(
x
,
p
,
β
)
=
l_{hist}(x,p,β)=
lhist(x,p,β)=
公式23
其中
ψ
ψ
ψ是
ψ
T
(
x
,
p
)
ψ_{T(x, p)}
ψT(x,p)的简写。引入one-hot假设,目标在每个特征维度分解为独立的项
l
h
i
s
t
(
x
,
p
,
β
)
=
l_{hist}(x,p,β)=
lhist(x,p,β)=
公式24
其中
N
j
(
A
)
=
∣
{
u
∈
A
:
k
[
u
]
=
j
}
∣
N^j(A)= | \{u∈A:k [u] = j\} |
Nj(A)=∣{u∈A:k[u]=j}∣是特征j为非零
k
[
u
]
=
j
k [u] = j
k[u]=j 的
ϕ
T
(
x
,
p
)
\phi _{T(x,p)}
ϕT(x,p)的区域A中的像素数。相关岭回归问题的解是
公式25
对于每个特征维度
j
=
1
,
…
,
M
j = 1, \dots, M
j=1,…,M,其中
ρ
j
(
A
)
=
N
j
(
A
)
/
∣
A
∣
ρ^j(A)= N^j(A)/|A|
ρj(A)=Nj(A)/∣A∣是特征
j
j
j不为零的区域中的像素的比例。此表达式先前已经在概率动机下使用[2,33]。在在线版本中,模型参数被更新
公式26
其中
ρ
t
(
A
)
ρ_t(A)
ρt(A)是对于
j
=
1
,
…
,
M
j = 1, \dots ,M
j=1,…,M的
ρ
t
j
(
A
)
ρ^j_t(A)
ρtj(A)的向量
3.5搜索策略
当在新的框架中搜索目标的位置时,我们考虑在平移/缩放而不是纵横比/方向上变化的矩形窗口。我们不是在平移/缩放中联合搜索,而是首先平移并且随后进行缩放上的搜索。我们遵循Danelljan等人 [8]并使用1D相关滤波器学习用于缩放搜索的独特的多尺度模板。 使用与学习平移模板相同的方案来更新此模型的参数。直方图得分不适合缩放搜索,因为它通常会倾向于缩小目标以找到更纯粹前景的窗口。
对于平移和缩放,我们仅搜索上一个位置周围的区域。我们还遵循采用相关滤波器来进行跟踪的先前工作[18,8],使用Hann窗口进行搜索以及训练。这些可以被认为是一个隐含的运动模型。
平移模板的大小被标准化为具有固定区域。该参数可以调整来使用跟踪质量换速度,如以下章节所示。
4. Evaluation评估
我们将Staple与两个最近和受欢迎的基准测试(VOT14 [24,25]和OTB [39])上的竞争方法进行比较,并展示了最先进的性能。为了实现最新的比较,我们报告了几个最近跟踪器的结果,作为每个基准一部分的基线之外的补充,使用作者自己的结果来确保公平的比较。因此,对于每个评估,我们只能与提供结果的方法进行比较。为了帮助重现我们的实验,我们将我们的跟踪器的源代码和我们的结果放在我们的网站上:www.robots.ox.ac.uk/ luca / stap.html。
图3:精确度 - 鲁棒性 report_challenge 排名图 更好的跟踪器更接近于右上角。
在表1中,我们报告了我们使用的最重要的参数的值。与标准实践相反,我们不从测试集中选择跟踪器的参数,而是使用VOT15作为验证集。
???
4.1. VOT14和 VOT15
The benchmark
VOT14 [24]比较了从394个中选出的表示几个具有挑战性的情况:相机运动,遮挡,照明,尺寸和运动变化的25个序列上的竞争跟踪器。使用两种性能指标。跟踪序列的精度表示为预测的边界框 r t r_t rt和真实值 r G T r_{GT} rGT之间的平均每帧重叠,使用交并比IOU评价标准, S t = ∣ r t ∩ r G T ∣ ∣ r t ∪ r G T ∣ S_t = \frac {| r_t∩r_{GT} |} {| r_t∪r_{GT} |} St=∣rt∪rGT∣∣rt∩rGT∣。 跟踪器的鲁棒性是其序列中的失败数量,当 S t S_t St变为零时确定已经发生失败。由于基准的关注点是短期跟踪,失败后的跟踪器在失败后五帧自动重新初始化为真实值。
鉴于两个性能指标的性质,共同考虑它们是至关重要的。考虑到彼此独立并且是不提供信息的,因为频繁失败的跟踪器将被更频繁地重新初始化,并且可能实现更高的精度,而通过报告对象占据整个视频帧,总是可以实现零失败。
result
为了产生表2和图3,我们使用在提交时可用的最新版本的VOT工具包(提交d3b2b1d)。从VOT14 [25]我们只包括了最优秀的表现者:DSST [8],SAMF [29],KCF [18],DGT [6],PLT 14和PLT 13。表2报告了每个追踪器的平均精度和失败次数,以及为两者而设计的总体排名。图3可以显示两个轴上的每个度量的独立排名。令人惊讶的是,我们的简单方法显着地超过了所有VOT14条目,以及许多最近的
表2:VOT14的排名结果。第一,第二和第三栏代表准确性,失败次数(在25个序列上)和总体排名。排越下面的越好。
表3,在VOT15的60个序列上的排名结果
VOT14后发布的追踪器。特别是,特别是,它超越了基于相关滤波器的DSST [8],SAMF [29]和KCF [18],基于色彩的PixelTrack [11],DAT,DAT(带有缩放)[33]和DGT [6]还有更复杂和更慢的方法如DMA [40]和SRDCF [9],执行时低于10 FPS。这是很有意思的,来观察Staple与第二好的相关性和颜色跟踪器SRDCF和DAT进行比较时的表现:与SRDCF相比,其精度提高了7%,失败率数量上提高了41%,与DAT相比,其精度提高了11%,失败数量上提高了13%。 分别考虑到这两个指标,Staple是目前准确性最好的方法,而失败次数方面是第四,在DMA,PLT 13和PLT 14之后。然而,所有这些跟踪器在准确性方面表现不佳,得分至少比Staple更差20%。
为了完整,我们还在表3中提供了VOT15上的结果,比较了Staple与表2中第二好的表现者(DAT)和VOT14的获胜者(DSST)。我们的性能明显优于DAT和DSST 在精度方面(分别+ 22%和+ 10%)和对于失败的鲁棒性(+ 35%和+47%)。
在本实验中,我们保留了为VOT15选择的超参数。 然而,这是符合惯例的,因为VOT基准从未包含验证集,假设超参数将足够简单,不会在数据集之间显着变化。
4.2 OTB-13
基准。
与VOT一样,OTB-13[39]的想法是对追踪器的准确性和对于失败的鲁棒性进行评估。
图5:与速度相关的对于大小为1×1,2×2,4×4和8×8的HOG的cells的失败次数(越低越好)。
再次,预测精度被测量为跟踪器的包围盒和真实值之间的IOU。当该值高于阈值 t o t_o to时,检测到成功。为了不为这种阈值设定一个具体值,将 t o t_o to不同值的成功率曲线下的面积作为最终得分。
结果。
我们使用与VOT14 / 15完全相同的代码和参数获得OTB的结果。唯一的区别是我们被限制对在基准中存在的几个灰度级序列使用一维直方图。图4报告了OPE(一次性评估),SRE(空间鲁棒性评估)和TRE(时间鲁棒性评估)的结果。Staple表现明显优于[39]中报道的所有方法,相对于原始基准评估的最佳追踪者(Struck [16]),平均相对改善了23%。此外,我们的方法也胜过近期在基准之后发布的跟踪器,如MEEM [41],DSST [8],TGPR [13],EBT [38]以及使用深层卷积网络如CNN-SVM [19]和SO-DLT [37],并以更高的帧率运行。在帧率方面,唯一可比的方法是ACT [10],然而在所有的评估中,这种方法表现得更差。由于ACT使用相关滤波器学习颜色模板,所以该结果表明,Staple通过组合模板和直方图分数实现的改进不能仅仅归结于颜色的引入。在OTB上,唯一比Staple更好的跟踪器就是最近的SRDCF [9]。 但是,它在VOT14上表现更差。 此外,它报告的速度只有5 FPS,严重限制了其适用性。
4.3 效率
以上述报告的配置,我们的MATLAB原型在配备英特尔酷睿i7-4790K @4.0GHz的机器上每秒运行约80帧。然而,通过调整其计算模型的patch的大小,可能实现更高的帧率并在性能方面相对小的损失。例如(参照图5),使用大小为2×2的HOG单元和502的固定区域仅导致失败数量的小幅增加,但是将速度提高到每秒100帧以上。精度遵循类似的趋势。
4.4 学习率实验
分别用于模板(21)和直方图(26)模型更新的学习率KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲η_{tmpl}和KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲η_{hist}确定了用当前帧的新证据取代早期帧中的旧证据的速率。学习率越低,与从早期帧中学到的模型实例相关性就越高。图6的热图说明了对于KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲ ̲η_{tmpl}和KaTeX parse error: Undefined control sequence: \cal at position 1: \̲c̲a̲l̲η_{hist}都可以实现在0.01左右的最大鲁棒性。精度遵循类似的趋势。
4.5 合并因子实验
在图7中,我们展示了Staple的精确度是如何受到在(3)中调节γtmpl和γhist的合并因子α的选择的影响的:在α= 0.3附近达到最佳性能。鲁棒性遵循类似的趋势。图7还显示,合并两个岭回归问题的密集响应的策略比仅仅对最终估计的插值获得了明显更好的表现,这表明选择具有兼容性(和互补性)的密集响应的模型是一个获胜的选择。
结论
通过从正样本的循环移位中学习他们的模型,相关滤波器不能学习到置换不变的分量。 这使得它们对形变固有地敏感。 因此,我们提出了模板和直方图分数的简单组合,独立地学习以保持实时操作。 由此产生的跟踪器,Staple,在几个基准测试中胜过了更复杂的最先进的跟踪器。 鉴于其速度和简单性,我们的跟踪器对于需要计算工作量本身的应用程序是一个合乎逻辑的选择,并且其中对颜色,照明和形状变化的鲁棒性至关重要。
致谢。
这项研究得到了Apical Imaging,Technicolor,EPSRC,Leverhulme Trust和ERC授权ERC-2012-AdG 321162- HELIOS的支持。
参考资料:
http://blog.csdn.net/u010598445/article/details/52793592
http://blog.csdn.net/cv_family_z/article/details/52386073
http://www.cnblogs.com/sysuzyq/p/6169414.html
http://blog.csdn.net/crazyice521/article/details/65658513















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









