







本内容整理自coursera,欢迎交流转载。
如何定义损失
我们用如下符号表示回归模型的损失(loss):
L(y,fw^(x⃗ ))
举个栗子,我们可以使用局对误差或者方差表示 损失函数:
L(y,fw^(x⃗ ))=|y−fw^(x⃗ )|
L(y,fw^(x⃗ ))=|y−fw^(x⃗ )|2
三种误差
training error
根据如上对损失函数的定义,training error可以表示为:
Training error= average.loss in Training set= 1N∑Ni=1L(y,fw^(x⃗ ))
注意:这里的计算实在training set上进行的。
例如我们可以用squared error来表示损失函数,那么
Trainingerror(w^)=1N∑Ni=1|y−fw^(x⃗ )|2−−−−−−−−−−−−−−−−√
由于training error是在训练集计算的,所以随着模型复杂度的增加,training error逐渐减小。
generalization error(泛化误差)
泛化误差表示为我们所有可能遇到的数据的误差,
generalization error=Ex,y[L(y,fw^(x⃗ ))]
这里的
Ex,y
指的是所有世界上可能的数据,
w^
是我们在training set得到的拟合系数向量。
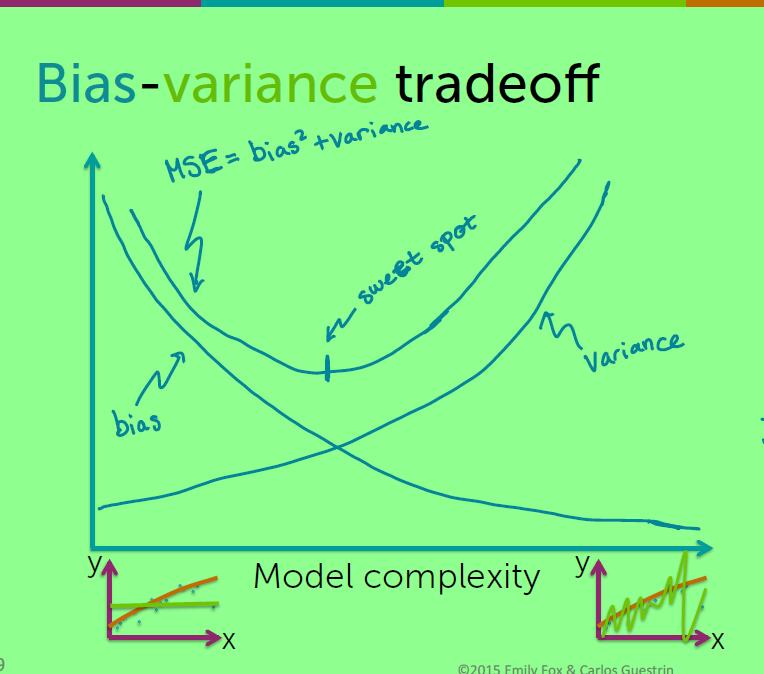
所以说泛化误差是永远无法得到的。随着模型的复杂度的增加,泛化误差先变小,然后由于过拟合而变大。
test error(测试误差)
Test error=avg.loss in test set=1Ntest∑i in test setL(y,fw^(x⃗ i))
注意:这里的 w^ 依旧是在训练集你喝的道德系数向量。
下面比较一下三种误差:

误差的三个来源
主要来自以下三个方面:
- noise(噪声)
- bias(偏差)
- variance(方差)
噪声是不可消除的。
Bias定义为:
假设我们有好多拟合函数,在不同的训练集拟合。我们把这些函数平均得到一个 fw¯(x⃗ ) ,那么我们的 Bias(x⃗ )=fw(true)(x⃗ )−fw¯(x⃗ ) ,由这个定义我们可以得知较低的模型复杂度会有较高的偏差,即 Low complexity→high bias .
方差:随着模型复杂度增加,方差增加
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











