







在对机器学习进行评价之前,我们先来了解一个名叫混淆矩阵的东西。
混淆矩阵:
在二分类问题中,我们只需要将样本分为两类,用数字对定类进行量化:0和1.
那么我们在用机器学习分类时也会出现两种情况,这时一个机器学习模型预测的结果就可以分为4种情况了。
我们以分汉堡为例:
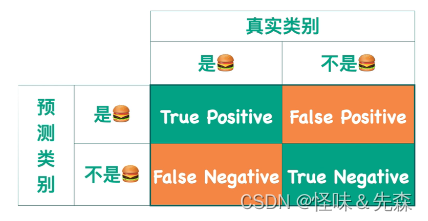
上图中:
Ture表示预测值和实际值相同的情况。
Positive和Negative分别表示预测的结果是什么。
当然这个也不局限于二分类问题,多分类问题也是一样的,我们构造一个n维的混淆矩阵就可以了。
好了,现在了解完混淆矩阵之后我们就可以来评价一个机器学习模型的好坏啦。
一.准确率
准确率是用来评价一个机器学习预测的正确性的指标。
用预测正确的个数来除以所有样本的个数。
缺陷:不同类别的样本的比例不均衡时,占比大的类别往往成为影响准确率的最主要因素。比如说输入的训练集中有99个不是病人,一个是病人。即使准确率很高,但如果是病人时我们没有预测出来,这个模型也不能说是一个很好的模型。
二.精确率
精确率=预测为正的样本中实际也为正的样本占被预测为正的样本的比例。
三.召回率
召回率=实际为正的样本中被预测为正的样本所占实际为正的样本的比例。
四.F1指标
在F1指标中,综合了召回率和精准率。
Precision体现了模型对负样本的区分能力。Precision越高,模型对负样本的区分能力越强;Recall体现了模型对正样本的识别能力。Recall越高,模型对正样本的识别能力越强。F1 score是 Precision和 Recall 的综合。F1 score越高,说明模型越稳健。
所以我们一般可以根据F1来判断模型的好坏。
五.AUC和ROC
在了解ROC曲线和AUC值之前,我们先来了解一下机器学习分类的原理。
我们通过训练一个机器学习的模型,然后往里面输入数据,模型会给出这个数据属于Positive的概率,那我们怎么确定这个属于哪一类呢?
我们可以设定一个阈值,当这个概率大于阈值时,它属于Positive,反之,则属于Negative。
了解这个之后,我们就可以来绘制ROC曲线啦。
我们引入两个指标:
伪阳性率(FPR):判定为正例却不是真正例的概率,即真负例中判为正例的概率
真阳性率(TPR):判定为正例也是真正例的概率,即真正例中判为正例的概率(也即正例召回率)
而ROC曲线的横坐标是伪阳性率(也叫假正类率,False Positive Rate),纵坐标是真阳性率(真正类率,True Positive Rate)。当然我们希望ROC曲线越靠近左上角越好,因此我们规定曲线下方的面积为AUC值,也就是说AUC值越大,模型的预测效果越好。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









