







 本文介绍了Mahout中对数似然比相似度的计算原理,通过一个实例展示了计算过程,包括行熵、列熵、矩阵熵的计算,并探讨了相似度的解释,以及从相关性的角度理解该相似度。通过对用户偏好商品集合的分析,揭示了用户之间的相似程度。
本文介绍了Mahout中对数似然比相似度的计算原理,通过一个实例展示了计算过程,包括行熵、列熵、矩阵熵的计算,并探讨了相似度的解释,以及从相关性的角度理解该相似度。通过对用户偏好商品集合的分析,揭示了用户之间的相似程度。
最近在看mahout的相似性度量时,对其中的对数似然比相似度颇为好奇,由于书本上完全没有涉及到对数似然比相似度的计算原理,只是提供了一个函数接口,因此决定深入了解一下这个对数似然比相似度。下面mahout中的源码:
public static double logLikelihoodRatio(int k11, int k12, int k21, int k22) {
double rowEntropy = entropy(k11, k12) + entropy(k21, k22);
double columnEntropy = entropy(k11, k21) + entropy(k12, k22);
double matrixEntropy = entropy(k11, k12, k21, k22);
return 2 * (matrixEntropy - rowEntropy - columnEntropy);
}
public static double entropy(int... elements) {
double sum = 0;
for (int element : elements) {
sum += element;
}
double result = 0.0;
for (int x : elements) {
if (x < 0) {
throw new IllegalArgumentException(
"Should not have negative count for entropy computation: (" + x + ')');
}
int zeroFlag = (x == 0 ? 1 : 0);
result += x * Math.log((x + zeroFlag) / sum);
}
return -result;
}我以一个实际的例子来介绍一下其中的计算过程:假设有商品全集I={a,b,c,d,e,f},其中A用户偏好商品{a,b,c},B用户偏好商品{b,d},那么有如下矩阵:
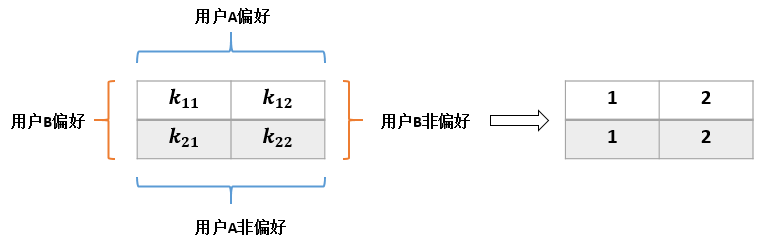
- k11表示用户A和用户B的共同偏好的商品数量,显然只有商品b,因此值为1
- k12表示用户A的特有偏好,即商品{a,c},因此值为2
- k21表示用户B的特有偏好,即商品d,因此值为1
- k22表示用户A、B的共同非偏好,有商品{e,f},值为2
此外我们还定义以下变量N=k11+k12+k21+k22,即总商品数量。
计算步骤如下:
计算行熵
rowEntropy=k11+k12N(k11k11+k12logk11k11+k12+k12k11+k12logk12k11+k12)+k21+k22N(k21k21+k22logk21k21+k22+k22k21+k22logk22
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









