







 Xception是Google为改进Inception v3而提出的深度学习模型,它使用depthwise separable convolution来减少计算复杂度并提升性能。深度wise卷积通过单独处理每个通道的特征,接着使用pointwise卷积结合这些信息。与Inception结构相比,Xception通过residual connections简化了网络,并在不显著增加复杂度的情况下实现了更好的效果。
Xception是Google为改进Inception v3而提出的深度学习模型,它使用depthwise separable convolution来减少计算复杂度并提升性能。深度wise卷积通过单独处理每个通道的特征,接着使用pointwise卷积结合这些信息。与Inception结构相比,Xception通过residual connections简化了网络,并在不显著增加复杂度的情况下实现了更好的效果。
论文:Xception: Deep Learning with Depthwise Separable Convolutions
论文链接:https://arxiv.org/abs/1610.02357
算法详解:
Xception是google继Inception后提出的对Inception v3的另一种改进,主要是采用depthwise separable convolution来替换原来Inception v3中的卷积操作。
要介绍Xception的话,需要先从Inception讲起,Inception v3的结构图如下Figure1。当时提出Inception的初衷可以认为是:特征的提取和传递可以通过1*1卷积,3*3卷积,5*5卷积,pooling等,到底哪种才是最好的提取特征方式呢?Inception结构将这个疑问留给网络自己训练,也就是将一个输入同时输给这几种提取特征方式,然后做concat。Inception v3和Inception v1(googleNet)对比主要是将5*5卷积换成两个3*3卷积层的叠加。
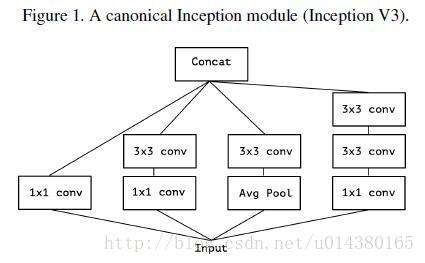
于是从Inception v3联想到了一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1498
1498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









