






原帖: 阿里云云栖社区
https://yq.aliyun.com/articles/114669 排版清晰,建议去原帖看
更多深度文章,请关注:https://yq.aliyun.com/cloud
2016年,欧莱礼媒体公司首席数据科学家罗瑞卡宣称:“2017年将是数据科学和大数据圈参与AI技术合作的一年。”在2017年之前,对基于GPU的深度学习已经渗透到大学和研究机构,但基于CPU分散式深度学习开始在不同的公司和领域得到广泛采用。虽然GPU提供了顶级的数字计算性能,但CPU也在变得更加高效,并且现有的大部分硬件已经有大量可用的CPU计算能力。另外GPU的价格比CPU的价格要相对而言贵好多,相信大家最近一阵也发现显卡的价格暴涨,这源于数字货币比特币的暴涨,而比特币是通过电脑计算得到,计算能力越强,其每天的计算量也就越多,相当于每天“挖矿”的量。涉及深度学习的研究员都应该了解一个事实,基于GPU跑一个网络和基于CPU跑同一个网络,二者的仿真速度可以达到20倍左右的差距。因此,基于CPU的分散式深度学习也会成为后续研究的一个方向。而开源工具Deeplearning4j的出现将快速深度学习扩展到Hadoop堆栈,这将是未来几年影响深度学习的主要催化剂。
本文将详细介绍如何使用开源工具——Apache Spark、Apache Hadoop和Deeplearning4j(DL4J),再加上商用硬件(Commodity Hardware,便宜、被广泛使用、容易被买到),能够使用有限的训练集在图像识别任务上获得最先进的结果。
Deeplearning4j:JVM的深度学习工具集
Deeplearning4j是许多开源深度学习工具包之一,创建于2014年。DL4J集成了Hadoop和Spark,设计用于运行在分布式GPU和CPU上的商用环境。它由总部位于旧金山的商用智能和企业软件公司Skymind牵头开发。团队成员包括数据专家、深度学习专家、Java系统工程师和具有一定感知力的机器人。虽然deeplearning4j是为JVM构建的,但它使用高性能原生线性代数库Nd4j,可以对CPU或GPU进行大量优化的计算。另外使用Java编写的DL4J API对于熟悉Java虚拟机(JVM)的Java和Scala开发人员特别有吸引力。此外,Spark模型的并行训练能力使得我们轻松利用现有的群集资源来加快训练时间,而不会牺牲精度。
基于Caltech-256图像数据集的对象分类
本文介绍如何使用Apache Spark、Apache Hadoop和deeplearning4j来解决图像分类问题。简单来说,就是通过构建一个卷积神经网络来对Caltech-256数据集中的图像进行分类。在Caltech-256数据集中,实际上有257个对象类别,每类数量大概是80到800个图像,该数据集总共30,607个图像。值得注意的是,该数据集上目前最先进的分类精度在72 - 75%范围内。下面我将带领大家使用DL4J和Spark轻松超越这个结果。
小数据上的有效深度学习
目前,卷积网络可以有几亿个参数,比如在大型视觉识别挑战 “ImageNet”中表现最佳的神经网络之一,有1.4亿个参数需要训练!这些网络不仅需要大量的计算和存储资源(即使是使用一组GPU,也可能需要几周时间才能完成计算),而且还需要大量数据。而Caltech-256只有30000多张图像,在这个数据集上训练这样一个复杂的模型是不现实的,因为没有足够的样本来充分学习这么多参数。相反,可以采用一种迁移学习的方法来实现。简单来说,就是将已学到的知识应用到其它领域,使其能够更好地完成新领域的学习。这是因为卷积神经网络在对图像数据集进行训练时往往会学习非常普遍的特征,因此这种类型的特征学习通常对其他图像数据集也是通用的。例如,在ImageNet上训练的网络可能已经学会了如何识别形状、面部特征、图案、文本等,这无疑对于Caltech-256数据集是有用的。
加载预训练的模型
下面讲解如何使用训练好的模型来完成自己的任务,以下示例使用VGG16 模型,该模型夺得了2014 ImageNet竞赛中的亚军(网络结构及训练好的参数已公开)。由于使用了不同的图像数据集,所以需要对VGG16模型进行微小修改以适用于Caltech-256数据集预测任务。该模型具有约1.4亿个参数,大约占用500 MB空间。
首先,获取DL4J可以理解和使用的VGG16型号的版本。事实证明,这种东西是建立在DL4J的API中的,它可以通过几行Scala代码完成。
val modelImportHelper = new TrainedModelHelper(TrainedModels.VGG16)
val vgg16 = modelImportHelper.loadModel()
val savePath = "./dl4j-models/vgg16.zip"
val locationToSave = new File(savePath)
// save the model in DL4J native format, which is faster for future reads
ModelSerializer.writeModel(vgg16, locationToSave, saveUpdater = true)
该模型采用的格式易于DL4J使用,使用内置的模型进行检查。
val modelFile = new File("./dl4j-models/vgg16.zip")
val vgg16 = ModelSerializer.restoreComputationGraph(modelFile)
println(vgg16.summary())
==================================================================================================
VertexName (VertexType) nIn,nOut TotalParams ParamsShape Vertex Inputs
==================================================================================================
input_2 (InputVertex) -,- - - -
block1_conv1 (ConvolutionLayer) 3,64 1792 b:{1,64}, W:{64,3,3,3} [input_2]
block1_conv2 (ConvolutionLayer) 64,64 36928 b:{1,64}, W:{64,64,3,3} [block1_conv1]
block1_pool (SubsamplingLayer) -,- 0 - [block1_conv2]
block2_conv1 (ConvolutionLayer) 64,128 73856 b:{1,128}, W:{128,64,3,3} [block1_pool]
block2_conv2 (ConvolutionLayer) 128,128 147584 b:{1,128}, W:{128,128,3,3} [block2_conv1]
block2_pool (SubsamplingLayer) -,- 0 - [block2_conv2]
block3_conv1 (ConvolutionLayer) 128,256 295168 b:{1,256}, W:{256,128,3,3} [block2_pool]
block3_conv2 (ConvolutionLayer) 256,256 590080 b:{1,256}, W:{256,256,3,3} [block3_conv1]
block3_conv3 (ConvolutionLayer) 256,256 590080 b:{1,256}, W:{256,256,3,3} [block3_conv2]
block3_pool (SubsamplingLayer) -,- 0 - [block3_conv3]
block4_conv1 (ConvolutionLayer) 256,512 1180160 b:{1,512}, W:{512,256,3,3} [block3_pool]
block4_conv2 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block4_conv1]
block4_conv3 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block4_conv2]
block4_pool (SubsamplingLayer) -,- 0 - [block4_conv3]
block5_conv1 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block4_pool]
block5_conv2 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block5_conv1]
block5_conv3 (ConvolutionLayer) 512,512 2359808 b:{1,512}, W:{512,512,3,3} [block5_conv2]
block5_pool (SubsamplingLayer) -,- 0 - [block5_conv3]
flatten (PreprocessorVertex) -,- - - [block5_pool]
fc1 (DenseLayer) 25088,4096 102764544 b:{1,4096}, W:{25088,4096} [flatten]
fc2 (DenseLayer) 4096,4096 16781312 b:{1,4096}, W:{4096,4096} [fc1]
predictions (DenseLayer) 4096,1000 4097000 b:{1,1000}, W:{4096,1000} [fc2]
--------------------------------------------------------------------------------------------------------------------------------------------
Total Parameters: 138357544
Trainable Parameters: 138357544
Frozen Parameters: 0
==================================================================================================
上面代码显示VGG16网络的结构及参数,ConvolutionLayer表示卷积层、SubsamplingLayer表示采样层、DenseLayer表示全连接层。下图简明扼要的展示了该网络结构:

VGG16具有13个卷积层,中间间隔放置最大池化层以收缩图像,降低计算复杂度。卷积层中的权重实际上是过滤器,可以学习从图像中挑选出视觉特征,当使用最大池化层时,它们会“收缩”图像,这意味着后来的卷积层中的滤波器实际上提取更加抽象的特征。这样,卷积层的输出是输入图像的抽象的视觉特征,如“这个图像中有脸吗?”还是“有日落?”卷积层的输出被馈送到连续的三个全连接层,全连接层能够学习这些视觉特征与输出之间的非线性关系。
另外卷积网络的关键性质之一是允许我们进行迁移学习——可以通过已经训练好的VGG16网络传递新的图像数据,并获取每个图像的特征。一旦提取了这些特征,就只需要送人最后的预测网络就可以完成相应的任务,这在计算和复杂度上都是非常容易解决的问题。
使用VGG16进行图像特征化
数据集可以从Caltech-256 网站下载,拆分为三个数据集,分别为训练/验证/测试数据集,并存储在HDFS中。一旦完成该步骤,下一步就是将整个图像数据集传递到网络的所有卷积层和第一个全连接层,并将该输出保存到HDFS。
样做的原因是是因为卷积网络中的大多数内存占用和耗时计算都是发生在卷积层中,VGG16中的大多数参数(权重)调用发生在全连接层。迁移学习利用预先训练的卷积层来获取关于新输入图像的特征,这意味着只有原始模型的一小部分——全连接层被重新训练。其余的参数是静态不变的。通过这种操作,迁移学习可以节省大量的训练时间和计算量。
首先提取用于特征化步骤的网络部分,Deeplearning4j具有内置的迁移学习API可用于此任务。即拆分VGG16模型,在拆分之前和之后获取整个图层列表,代码如下。
val modelFile = new File("./dl4j-models/vgg16.zip")
val vgg16 = ModelSerializer.restoreComputationGraph(modelFile)
val (frozenLayers: Array[Layer], unfrozenLayers: Array[Layer]) = {
vgg16.getLayers.splitAt(vgg16.getLayers.map(_.conf().getLayer.getLayerName).indexOf("fc2") + 1)
}
现在使用org.deeplearning4j.nn迁移学习包来提取全连接“fc2”层之前(包括“fc2”层)的网络模型,如下图所示:垂线左边部分。
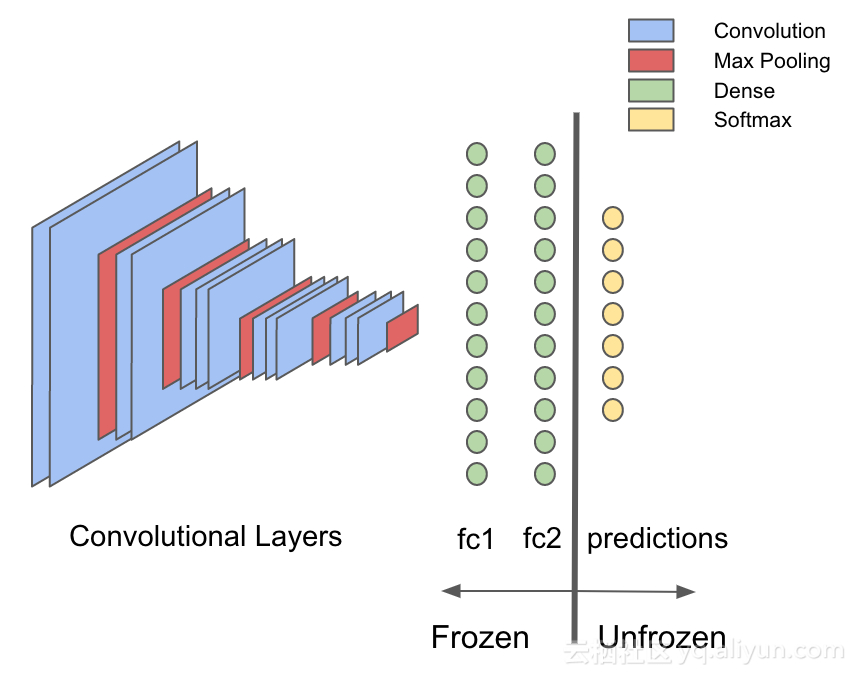
val builder = new TransferLearning.GraphBuilder(model)
.setFeatureExtractor(frozenLayers.last.conf().getLayer.getLayerName)
// remove all the unfrozen layers, leaving just the un-trainable part of the model
unfrozenLayers.foreach { layer =>
builder.removeVertexAndConnections(layer.conf().getLayer.getLayerName)
}
builder.setOutputs(frozenLayers.last.conf().getLayer.getLayerName)
val frozenGraph = builder.build()
接下来是读取数据库中的图像文件。在这种情况下,这些文件被单独保存到HDFS作为JPEG文件。图像被组织成子目录,其中每个子目录包含属于特定类的一组图像。首先通过使用sc.binaryFiles 加载存储在HDFS中的图像,并使用DataVec库(DL4J的ETL库)中的图像处理工具将它们转换为INDArrays,这是DL4J处理的本机张量表示(此处为完整代码)。最后,使用上图中的冻结网络部分对输入图像进行特征提取,本质上是将它们传递到VGG16模型中的预测层前。
val finalOutput = Utils.getPredictions(data, frozenGraph, sc)
val df = finalOutput.map { ds =>
(Nd4j.toByteArray(ds.getFeatureMatrix), Nd4j.toByteArray(ds.getLabels))
}.toDF()
df.write.parquet("hdfs:///user/leon/featurizedPredictions/train")
经过上述操作后,得到一个保存到HDFS中新的数据集。接下来可以开始构建使用这种特征化数据的传输学习模型,从而大大减少训练时间和计算复杂度。在上述示例中,得到的新数据集由30607个长度为4096的向量组成(这是由于VGG16模型中的全连接层“f2”维度为4096)。
替换VGG16的预测层
VGG16模型是在ImageNet数据集上进行训练的,而ImageNet数据集具有1000种不同对象类别。在典型的图像分类神经网络中,输出层的最后一层使用其输入来为数据集中的每个对象生成概率(哪一类的概率大就判断为哪一类)。因此,该输入可以被认为是关于图像的抽象视觉特征,提供关于其包含的对象的有用信息。直观地说,上述步骤生成的新数据集于Caltech-256数据集中识别对象应该是有用的。因此,定义一个新的模型,“f2”层前的模型不变,只是替换VGG16模型的最后一层预测层,将维度从原先的1000变成257,正好对应Caltech256数据集的257个类别。
val conf = new NeuralNetConfiguration.Builder()
.seed(42)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.iterations(1)
.activation(Activation.SOFTMAX)
.weightInit(WeightInit.XAVIER)
.learningRate(0.01)
.updater(Updater.NESTEROVS)
.momentum(0.8)
.graphBuilder()
.addInputs("in")
.addLayer("layer0",
new OutputLayer.Builder(LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX)
.nIn(4096)
.nOut(257)
.build(),
"in")
.setOutputs("layer0")
.backprop(true)
.build()
val model = new ComputationGraph(conf)
直观图如下,可以看到只是改变了预测层的维度:
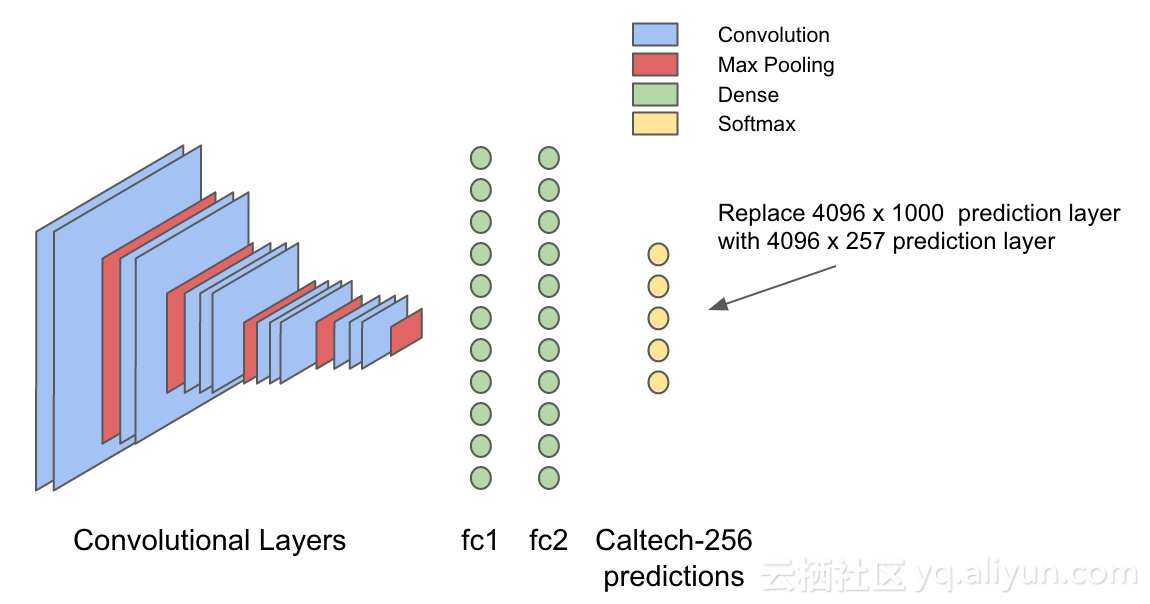
该模型现在已准备好使用DL4J进行大量计算,而且还使用Spark进行规模化。简单来说是切分大规模的数据集,然后将分片交给spark群集中的每个工作核心上运行SGD,最后使用Spark RDD聚合操作对每个核心上学习的不同模型进行平均,实现分布式训练。
val tm = new ParameterAveragingTrainingMaster.Builder(1)
.averagingFrequency(5)
.workerPrefetchNumBatches(2)
.batchSizePerWorker(32)
.rddTrainingApproach(RDDTrainingApproach.Export)
.build()
val model = new SparkComputationGraph(sc, graph, tm)
现在针对具体的迭代次数训练SparkComputationGraph,并监控一些训练统计数据以跟踪进度。
model.setListeners(new ScoreIterationListener(1))
(1 to param.numEpochs).foreach { i =>
logger4j.info(s"epoch $i starting")
model.fit(trainRDD)
// print model accuracy and score on entire train and validation sets every 5 iterations
if (i % 5 == 0) {
logger4j.info(s"Train score: ${model.calculateScore(trainRDD, true)}")
logger4j.info(s"Train stats:\n${Utils.evaluate(model.getNetwork, trainRDD, 16)}")
if (validRDD.isDefined) {
logger4j.info(s"Validation stats:\n${Utils.evaluate(model.getNetwork, validRDD.get, 16)}")
logger4j.info(s"Validation score: ${model.calculateScore(validRDD.get, true)}")
}
}
}
最后,通过spark提交训练工作,然后使用DL4J webui监控进度并诊断问题。下图绘制的是模型得分与迭代次数的关系,注意到分数是minibatch的负对数似然率,分数越小,效果越好。
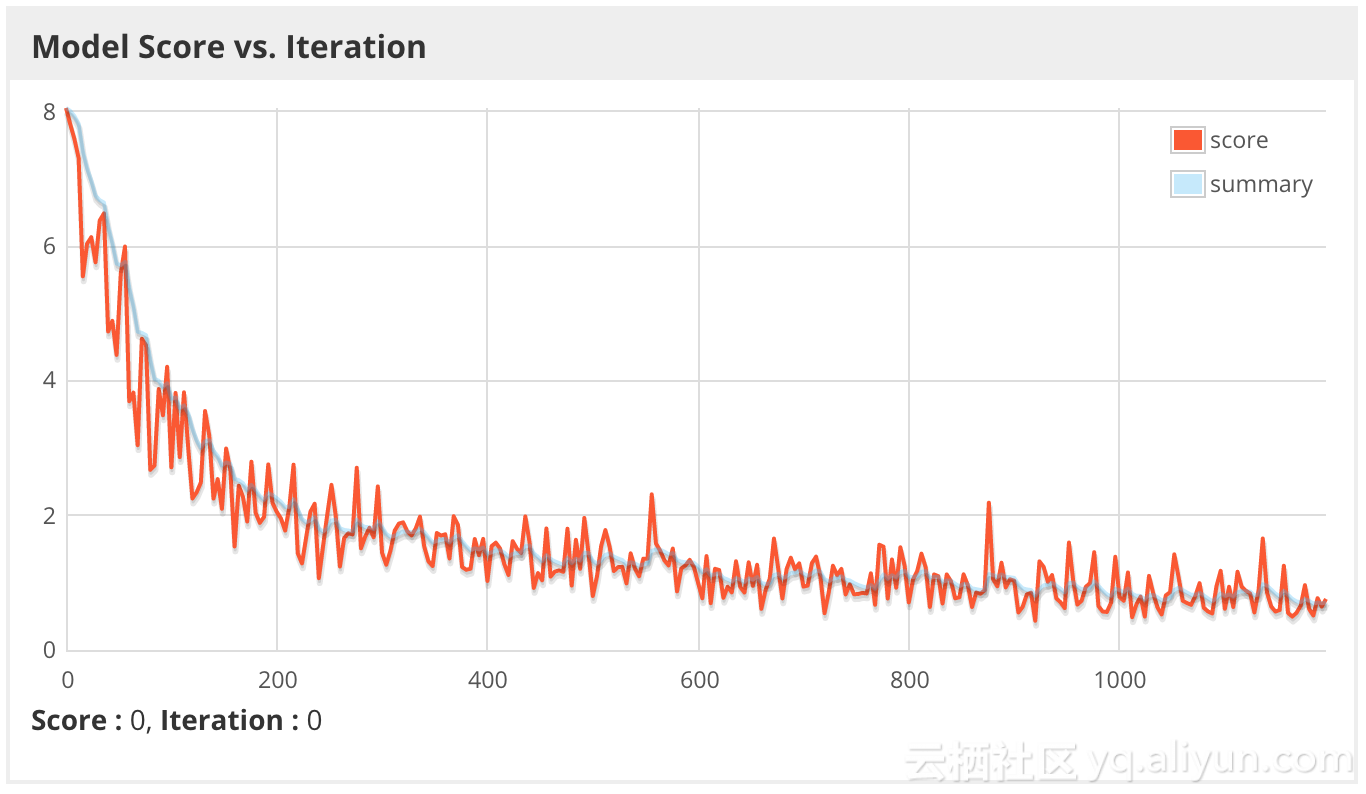
这次将学习率调低后,该模型似乎能比Imagenet模型能更快地学习,因为这次使用的特征比ImageNet概率更具预测性。
17/05/12 16:06:12 INFO caltech256.TrainFeaturized$: Train score: 0.6663876733861492
17/05/12 16:06:39 INFO caltech256.TrainFeaturized$: Train stats:
Accuracy: 0.8877570632327504
Precision: 0.8937314411403346
Recall: 0.876864905154427
17/05/12 16:07:17 INFO caltech256.TrainFeaturized$: Validation stats:
Accuracy: 0.7625918867410836
Precision: 0.7703367671469078
Recall: 0.7383574179140013
17/05/12 16:07:26 INFO caltech256.TrainFeaturized$: Validation score: 1.08481537405921
由于训练准确率为88.8%,但验证准确率仅为76.3%,从结果上看该模型似乎已经过拟合了。为了确保模型不会过拟合到验证集,在测试集上评估该模型。
Accuracy: 0.7530218882718066
Precision: 0.7613121478786196
Recall: 0.7286152891276695
虽然准确率有所降低,但是使用基于现有Hadoop集群和商用CPU的简单深度学习架构仍然打破了该数据集的最好结果!虽然这可能不是一个突破性的成就,但这仍然是一个令人兴奋的结果。
结论
虽然deeplearning4j只是许多深度学习可用的工具之一,但它具有本机Apache Spark集成,并且采用Java编写,使其特别适合整个Hadoop生态系统。由于现有的企业数据已经通过Hadoop进行了大量访问,而且在Spark上进行处理,所以deeplearning4j的定位是花费更少的时间部署和减少开销,从而企业公司可以立即开始从深度学习中提取数据。它利用ND4J进行大量计算,这是一种高度优化的库,可与商用CPU配合使用,但在需要性能提升时也支持GPU。Deeplearning4j提供了一个全功能的深度学习库,具有从采集到部署的工具,可
用于各种任务,如图像/视频识别,音频处理等。
作者信息
Nisha Muktewar,数据科学家,目前就职于Cloudera的数据科学团队,专注于专业服务、售前工作。
Seth Hendrickson,以前是电气工程师,现在是数据科学家和软件工程师,研究方向是分布式机器学习。
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《Deep learning on Apache Spark and Apache Hadoop with Deeplearning4j | Cloudera Engineering Blog》,作者:Nisha Muktewar、Seth Hendrickson,译者:海棠,审阅:














 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









