






 本文通过典型实例介绍动态规划的基本概念,包括跳台阶问题和0-1背包问题,并深入解析动态规划算法解决最长公共子序列(LCS)问题的方法。
本文通过典型实例介绍动态规划的基本概念,包括跳台阶问题和0-1背包问题,并深入解析动态规划算法解决最长公共子序列(LCS)问题的方法。
通俗理解动态规划(最初发布于10年年底,后修改于11年年底,23年再次修订)
前言
本文也是有意思,先后经历了三个版本
- 最开始发布于2010年年底,标题就叫“三、dynamic programming”,作为十五大算法研究系列的第三篇
- 一年后的2011年年底重写,标题改成:通过动态规划算法解最长公共子序列LCS问题
- 23年2月因为在写RL笔记中的三大表格求解法,发现本文并不通俗,原因在于本身DP就不是特别好讲懂,LCS问题也不好讲懂,用一个不好讲懂的例子去讲解一个并不好讲懂的算法,这无疑增加初学者的阅读负担
故再次修订本文的第一部分:增加三个形象易懂的示例,以及全面修订第二部分
第一部分 什么是动态规划
1.1 动态规划两个示例
在RL极简入门笔记里提到,动态规划的核心思想在于将复杂问题的最优解划分为多个小问题的最优解,就像递归一样,且子问题的最优解会被储存起来重复利用
对于大部分文章而言,此时就该上动态规划的定义了,考虑到本文的读者有初学者甚至是文科生,一上来就搬出定义、公式、概念不太友好啊。
对此,我在我维护的一个聚集着国内AI各大咖、中咖、小咖的「Machine Learning读书会」群里问大家,有哪些例子举例说明DP比较形象呢,形象到一个初一小孩 也能看明白的?
很多朋友比如刘鹏老师、达尔、kosora给了我很多建议,说可以通过这些例子以形象说明DP:跳台阶问题、01背包(寻找和为定值的多个数)、字符串的编辑距离
一想确实形象,而且巧的是这三个问题在我15年写的《编程之法:面试和算法心得》里面都有讲(顺带说一句,正在修订准备出第二版,本文所讲的DP算法会作为新的内容之一放进第二版中,第二版中全部的更新内容超过1/3),我们来看下前两个问题
问题1 跳台阶问题
一个台阶总共有n 级,如果一次可以跳1 级,也可以跳2 级。求总共有多少总跳法,并分析算法的时间复杂度。
首先考虑最简单的情况
- 如果只有1级台阶,那显然只有一种跳法
- 如果有2级台阶,那就有两种跳的方法了:一种是分两次跳,每次跳1级;另外一种就是一次跳2级
泛化到一般情况,把n级台阶时的跳法看成是n的函数,记为f(n),当n>2时,第一次跳的时候就有两种不同的选择:
- 一是第一次只跳1级,此时跳法数目等于后面剩下的n-1级台阶的跳法数目,即为f(n-1)
- 另外一种选择是第一次跳2级,此时跳法数目等于后面剩下的n-2级台阶的跳法数目,即为f(n-2)
因此n级台阶时的不同跳法的总数
上述解法用的递归的方法有许多重复计算的工作,事实上,我们可以从后往前推,一步步利用之前计算的结果递推。
初始化时,dp[0]=dp[1]=1,然后递推计算即可:dp[n] = dp[n-1] + dp[n-2]
//1, 1, 2, 3, 5, 8, 13, 21..
int ClimbStairs(int n)
{
int dp[3] = { 1, 1 };
if (n < 2)
{
return 1;
}
for (int i = 2; i <= n; i++)
{
dp[2] = dp[0] + dp[1];
dp[0] = dp[1];
dp[1] = dp[2];
}
return dp[2];
}更多分析请参见原来的:编程艺术GitHub 2nd
问题2 寻找和为定值的多个数(01背包问题)
输入两个整数n和sum,从数列1,2,3.......n 中随意取几个数,使其和等于sum,要求将其中所有的可能组合列出来。
注意到取n,和不取n个区别即可,考虑是否取第n个数的策略,可以转化为一个只和前n-1个数相关的问题。
- 如果取第n个数,那么问题就转化为“取前n-1个数使得它们的和为sum-n”,对应的代码语句就是sumOfkNumber(sum - n, n - 1);
- 如果不取第n个数,那么问题就转化为“取前n-1个数使得他们的和为sum”,对应的代码语句为sumOfkNumber(sum, n - 1)
所以其关键代码就是
list1.push_front(n); //典型的01背包问题
SumOfkNumber(sum - n, n - 1); //“放”n,前n-1个数“填满”sum-n
list1.pop_front();
SumOfkNumber(sum, n - 1); //不“放”n,前n-1个数“填满”sum问题2的扩展 0-1背包问题
这是一个典型的0-1背包问题,其具体描述为:有件物品和一个容量为
的背包。放入第
件物品耗费的费用是
(也即占用背包的空间容量),得到的价值是
,求解将哪些物品装入背包可使价值总和最大。
简单分析下:这是最基础的背包问题,特点是每种物品仅有一件,可以选择放或不放。用子问题定义状态:即表示前
件物品恰放入一个容量为
的背包可以获得的最大价值
对于“将前i件物品放入容量为v的背包中”这个子问题,若只考虑第i件物品的策略(放或不放),那么就可以转化为一个只和前件物品相关的问题。即:
- 如果不放第
件物品,那么问题就转化为“前
件物品放入容量为
的背包中”,价值为
;
- 如果放第
的背包中”,此时能获得的最大价值就是
再加上通过放入第i件物品获得的价值
则其状态转移方程便是:
伪代码如下:
F[0,0...V] ← 0
for i ← 1 to N
for v ← Ci to V
F[i, v] ← max{F[i-1, v], F[i-1, v-Ci] + Wi }更多分析见原来的编程艺术GitHub
1.2 动态规划的定义与算法流程
通过上述两个例子,相信你已经看出一些端倪,具体而言,动态规划一般也只能应用于有最优子结构的问题。最优子结构的意思是局部最优解能决定全局最优解(对有些问题这个要求并不能完全满足,故有时需要引入一定的近似)。简单地说,问题能够分解成子问题来解决。
动态规划算法一般分为以下4个步骤:
- 描述最优解的结构
- 递归定义最优解的值
- 按自底向上的方式计算最优解的值 //此3步构成动态规划解的基础。
- 由计算出的结果构造一个最优解 //此步如果只要求计算最优解的值时,可省略
换言之,动态规划方法的最优化问题的俩个要素:最优子结构性质,和子问题重叠性质
- 最优子结构
如果问题的最优解所包含的子问题的解也是最优的,我们就称该问题具有最优子结构性质(即满足最优化原理)。意思就是,总问题包含很多个子问题,而这些子问题的解也是最优的。 - 重叠子问题
子问题重叠性质是指在用递归算法自顶向下对问题进行求解时,每次产生的子问题并不总是新问题,有些子问题会被重复计算多次。动态规划算法正是利用了这种子问题的重叠性质,对每一个子问题只计算一次,然后将其计算结果保存在一个表格中,当再次需要计算已经计算过的子问题时,只是在表格中简单地查看一下结果,从而获得较高的效率
1.3 DP与贪心的对比:零钱凑整问题
我在知乎上专门搜了下动态规划,发现高赞的一个回答不错,名叫阮行止的举了一个零钱凑整的例子,如下(为行文简洁,我精简了下描述)
假设你想现在需要用各种1、5、10、20、50、100元面值的人民币凑出某个金额w比如666元,你会怎样尽快凑齐呢
- 为了尽快凑齐666元,你会按照各个钞票的金额大小,先用多张100逼近要凑整的金额,其次再用50、20、10、5、1的,在这种策略下,666 = 6×100+1×50+1×10+1×5+1×1,共使用了10张钞票
这种策略称为贪心,即当需要凑出w时,贪心的策略在于以最快速度让所需凑的剩余金额尽快变小,所以能让w先少100就先让它少100,从而接下来就是继续凑w-100 - 但是,如果我们换一组钞票的面值,贪心策略可能就不成立了,比如一个奇葩国家的钞票面额分别是:1、5、11,那我们在凑出15的时候,贪心策略会出错:
15 = 1 × 11 + 4 × 1
贪心策略使用了5张钞票,因为贪心策略的纲领是“尽量使接下来要凑的金额更小”。这样,贪心策略在所凑金额w=15时,会优先使用面值11的钞票来把接下来所需凑的剩余金额降到4,但再之后得用到4张1元钞票凑出4
正确的策略先使用5,所需凑的剩余金额会降为10,虽然剩余金额没有4那么小,但是再凑出10只需要两张5元,最终只需用3张钞票,即
15 = 5 + 2 × 5
如此我们发现,贪心是一种只考虑只看眼前不看长远的策略,属于鼠目寸光,那怎么避免鼠目寸光呢?总不能直接暴力枚举所有凑出w的方案吧,那样时间复杂度过高。
我们把该问题抽象化建模下,当面对“给定w,凑出w所用的最少钞票是多少张?”这个问题时,可用来表示“凑出n所需的最少钞票数量”,则当所需凑的金额w=15的时候
- 如果一开始先用11来逼近15,接下来就面对15 -11 = 4的情况,从而之后付出的代价是f(4),最后用掉的钞票总数是
cost = 1 + f(4)= 1(11元) + 1(1元) + 1(1元) + 1(1元) + 1(1元) = 5 - 如果一开始只取5来逼近15,则接下来面对15 - 5=10的情况,则
cost = 1 + f(10) = 1(5元) + 1(5元) + 1(5元) = 3 - 如果一开始取1来逼近15,则
cost= 1 + f(14) = 1 + 1(11元) + 1(1元) + 1(1元) + 1(1元) = 5
我们要取的钞票策略自然就是cost值最低的一开始取5的方案,这给了我们一个至关重要的启示:只与
、
、
相关,更确切地说:
第二部分 动态规划算法解LCS问题
通过上文第一部分,我们了解了什么是DP,接下来咱们运用经典的动态规划算法解决LCS问题即最长公共子序列问题
2.1 如何逐步求解最长公共子序列问题LCS
请编写一个函数,输入两个字符串,求它们的最长公共子序列(子序列不要求字符是连续的),并打印出最长公共子序列
例如:输入两个字符串BDCABA和ABCBDAB,字符串BCBA和BDAB都是它们的最长公共子序列,则输出它们的长度4,并打印任意一个子序列。
分析:求最长公共子序列(Longest Common Subsequence, LCS)是一道非常经典的动态规划题,因此一些重视算法的公司像MicroStrategy都把它当作面试题。
事实上,最长公共子序列问题也有最优子结构性质,记:
假定
,则
表示
序列的前
)
假定
, 则
表示
序列的前
个字符 (
)
假定
-
若
(最后一个字符相同),则不难用反证法证明:该字符必是X与Y的任一最长公共子序列
(设长度为
)的最后一个字符,即有
且显然有
,即Z的前缀
是
与
的最长公共子序列
此时,问题化归成求等于
的长度加1,相当于最后在
-
若
(最后一个字符不同),则亦不难用反证法证明:要么
,要么
由于与
其中至少有一个必成立,若
此时,问题化归成求
从而
由于上述当的情况中,求
的长度与
的长度,这两个问题不是相互独立的:两者都需要求
的长度。另外两个序列的LCS中包含了两个序列的前缀的LCS,故问题具有最优子结构性质且具有子问题重叠性质,可以考虑用动态规划法
换言之,你只需要求以下4个方面的解:
- 若
其中,
,
- 若
- 若
- 最后针对上述2和3的结果取其更大值:
现在我们来建立子问题的最优值的递归关系,用记录序列
和
的最长公共子序列的长度,当
或
时,空序列是
和
的最长公共子序列,故
,最终由定理可建立递归关系如下:
可以看到,计算时间是随输入长度指数增长的,相当于有个不同的子问题,因此,用动态规划算法自底向上地计算最优值能提高算法的效率。
接下来,我们考虑代码实现,首先定义计算最长公共子序列长度的DP算法,
- 以序列
和
比如下图所示,竖向的,横向的
向上走一格,意味着:
向左边走一格,意味着:
向左上斜着走一格,意味着: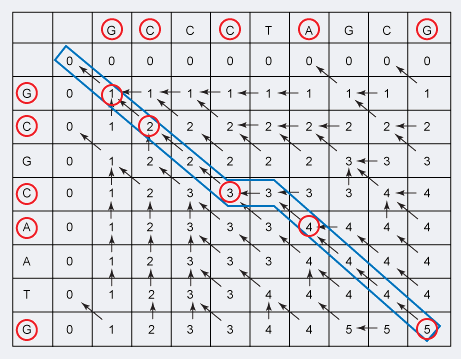
- 输出两个数组
和
其中存储
与
的最长公共子序列的长度,
记录指示
当
是LCS的一个元素),表示
与
的最长公共子序列在尾部加上
或
得到的子序列
当
当
当然,有时候左上、左、上三者中有多个同时达到最大,可以任取其中之一,也可以定义为一个优先级,比如左上 > 左 > 上 - 最后,
中
这种方法是按照反序来找LCS的每一个元素的。由于每个数组单元的计算耗费时间,算法
耗时
,代码如下
Procedure LCS_LENGTH(X,Y);
begin
m:=length[X];
n:=length[Y];
for i:=1 to m do c[i,0]:=0;
for j:=1 to n do c[0,j]:=0;
for i:=1 to m do
for j:=1 to n do
if x[i]=y[j] then
begin
c[i,j]:=c[i-1,j-1]+1;
b[i,j]:="↖";
end
else if c[i-1,j]≥c[i,j-1] then
begin
c[i,j]:=c[i-1,j];
b[i,j]:="↑";
end
else
begin
c[i,j]:=c[i,j-1];
b[i,j]:="←"
end;
return(c,b);
end;下面的算法实现根据
的内容打印出
与
的最长公共子序列,通过算法的调用
,便可打印出序列X和Y的最长公共子序列
Procedure LCS(b,X,i,j);
begin
if i=0 or j=0 then return;
if b[i,j]="↖" then
begin
LCS(b,X,i-1,j-1);
print(x[i]); {打印x[i]}
end
else if b[i,j]="↑" then LCS(b,X,i-1,j)
else LCS(b,X,i,j-1);
end; 在算法中,每一次的递归调用使
或
减1,因此算法的计算时间为
。
再举个例子,设所给的两个序列为和
,由算法
和
计算出的结果如下图所示:

再来说明下此图(参考算法导论)
- 由
计算出表c和b,第
的项4,表的右下角为
的长度
对于,项
和
的值,这几个项都在
- 为了重构一个LCS的元素,从右下角开始跟踪
所以根据上述图所示的结果,程序将最终输出:“B C B A”,或“B D A B”
2.2 进一步分析:算法改进、代码实现、时间复杂度
对于一个具体问题,按照一般的算法设计策略设计出的算法,往往在算法的时间和空间需求上还可以改进。这种改进,通常是利用具体问题的一些特殊性。
- 例如,在算法
中,可进一步将数组b省去。事实上,数组元素
三个值之一确定,而数组元素
- 因此,在算法LCS中,我们可以不借助于数组b而借助于数组c本身临时判断
- 既然
对于算法
的空间,而
和
。不过,由于数组c仍需要
的空间,因此这里所作的改进,只是在空间复杂性的常数因子上的改进
另外,如果只需要计算最长公共子序列的长度,则算法的空间需求还可大大减少。事实上,在计算时,只用到数组
的第
行和第
行。因此,只要用2行的数组空间就可以计算出最长公共子序列的长度。更进一步的分析还可将空间需求减至
。
最后给出此LCS的最终代码,参考如下:
// LCS.cpp : 定义控制台应用程序的入口点。
//
//copyright@zhedahht
//updated@2011.12.13 July
#include "stdafx.h"
#include "string.h"
#include <iostream>
using namespace std;
// directions of LCS generation
enum decreaseDir {kInit = 0, kLeft, kUp, kLeftUp};
void LCS_Print(int **LCS_direction,
char* pStr1, char* pStr2,
size_t row, size_t col);
// Get the length of two strings' LCSs, and print one of the LCSs
// Input: pStr1 - the first string
// pStr2 - the second string
// Output: the length of two strings' LCSs
int LCS(char* pStr1, char* pStr2)
{
if(!pStr1 || !pStr2)
return 0;
size_t length1 = strlen(pStr1);
size_t length2 = strlen(pStr2);
if(!length1 || !length2)
return 0;
size_t i, j;
// initiate the length matrix
int **LCS_length;
LCS_length = (int**)(new int[length1]);
for(i = 0; i < length1; ++ i)
LCS_length[i] = (int*)new int[length2];
for(i = 0; i < length1; ++ i)
for(j = 0; j < length2; ++ j)
LCS_length[i][j] = 0;
// initiate the direction matrix
int **LCS_direction;
LCS_direction = (int**)(new int[length1]);
for( i = 0; i < length1; ++ i)
LCS_direction[i] = (int*)new int[length2];
for(i = 0; i < length1; ++ i)
for(j = 0; j < length2; ++ j)
LCS_direction[i][j] = kInit;
for(i = 0; i < length1; ++ i)
{
for(j = 0; j < length2; ++ j)
{
//之前此处的代码有问题,现在订正如下:
if(i == 0 || j == 0)
{
if(pStr1[i] == pStr2[j])
{
LCS_length[i][j] = 1;
LCS_direction[i][j] = kLeftUp;
}
else
{
if(i > 0)
{
LCS_length[i][j] = LCS_length[i - 1][j];
LCS_direction[i][j] = kUp;
}
if(j > 0)
{
LCS_length[i][j] = LCS_length[i][j - 1];
LCS_direction[i][j] = kLeft;
}
}
}
// a char of LCS is found,
// it comes from the left up entry in the direction matrix
else if(pStr1[i] == pStr2[j])
{
LCS_length[i][j] = LCS_length[i - 1][j - 1] + 1;
LCS_direction[i][j] = kLeftUp;
}
// it comes from the up entry in the direction matrix
else if(LCS_length[i - 1][j] > LCS_length[i][j - 1])
{
LCS_length[i][j] = LCS_length[i - 1][j];
LCS_direction[i][j] = kUp;
}
// it comes from the left entry in the direction matrix
else
{
LCS_length[i][j] = LCS_length[i][j - 1];
LCS_direction[i][j] = kLeft;
}
}
}
LCS_Print(LCS_direction, pStr1, pStr2, length1 - 1, length2 - 1); //调用下面的LCS_Pring 打印出所求子串。
return LCS_length[length1 - 1][length2 - 1]; //返回长度。
}
// Print a LCS for two strings
// Input: LCS_direction - a 2d matrix which records the direction of
// LCS generation
// pStr1 - the first string
// pStr2 - the second string
// row - the row index in the matrix LCS_direction
// col - the column index in the matrix LCS_direction
void LCS_Print(int **LCS_direction,
char* pStr1, char* pStr2,
size_t row, size_t col)
{
if(pStr1 == NULL || pStr2 == NULL)
return;
size_t length1 = strlen(pStr1);
size_t length2 = strlen(pStr2);
if(length1 == 0 || length2 == 0 || !(row < length1 && col < length2))
return;
// kLeftUp implies a char in the LCS is found
if(LCS_direction[row][col] == kLeftUp)
{
if(row > 0 && col > 0)
LCS_Print(LCS_direction, pStr1, pStr2, row - 1, col - 1);
// print the char
printf("%c", pStr1[row]);
}
else if(LCS_direction[row][col] == kLeft)
{
// move to the left entry in the direction matrix
if(col > 0)
LCS_Print(LCS_direction, pStr1, pStr2, row, col - 1);
}
else if(LCS_direction[row][col] == kUp)
{
// move to the up entry in the direction matrix
if(row > 0)
LCS_Print(LCS_direction, pStr1, pStr2, row - 1, col);
}
}
int _tmain(int argc, _TCHAR* argv[])
{
char* pStr1="abcde";
char* pStr2="acde";
LCS(pStr1,pStr2);
printf("\n");
system("pause");
return 0;
}程序运行结果如下所示:

算法导论上指出,
- 最长公共子序列问题的一个一般的算法、时间复杂度为
时间内执行的算法,其中
,而且此序列是从一个有限集合中而来。在输入序列中没有出现超过一次的特殊情况中,Szymansk说明这个问题可在
内解决
- 一篇由Gilbert和Moore撰写的关于可变长度二元编码的早期论文中有这样的应用:在所有的概率pi都是0的情况下构造最优二叉查找树,这篇论文给出一个
时间的算法。Hu和Tucker设计了一个算法,它在所有的概率pi都是0的情况下,使用
的时间和
更多可参考《算法导论》一书第15章 动态规划问题,或参考:程序员编程艺术第十一章、最长公共子序列(LCS)问题


















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











