







1.什么是决策树
- 从树的根节点开始一步步(决策)走到子节点的树型结构
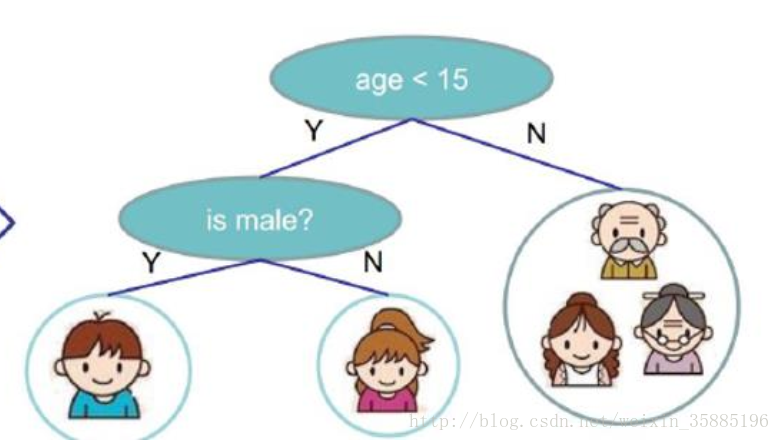
- 假如我门需要解决谁愿意和我们一起玩游戏的问题,并且有如下的数据
那么我们可以构造一个如下的决策树来预测结果

2.决策树的构建
- 决策树定义很简单,关键是我们如何构建一棵决策树,为什么要把年龄当成树节点,把性别当成子节点?我们分配的标准就是,使用这个分类器后,使得数据的混乱度最大的降低。我们用熵来表示混乱程度度,
- 熵
- 表示物体的混乱程度
- 表示函数: Info(D)=−∑ni=1pi∗log2pi (小概率事件越多,熵越大)
- 信息增益
- 表示函数 InfoA(D)=∑vj=1|Dj||D|∗Info(Dj)
- Gain=Info(D)−InfoA(D)
- 表示每次分类后数据混乱度下降的程度
- 遍历每种分类的信息增益率,把最大的当初当次分类的分类器
- 连续值离散化:如果是连续值,可以把数据进行切分,进行离散化,比如年龄,我们可以在15岁分割,也可以在38 岁进行分割,计算所有可能性,取结果最好的(在实际中,更多的是使用随机切分,遍历所有可能回导致巨大的计算量)
- C4.5算法对ID3算法的优化:
- ID3算法中,如果是ID列,数值从1~n,那么分成n类后,它的信息增益是最高的,然而对于实际情况,这种分类是没有任何意义的,所以在C4.5算法中,提出了信息增益率的概念来解决这个问题
- 信息增益率
- 分裂信息: SplitInfoa(D)=−∑vj=1|Dj||D|∗log2(|Dj||D|)
- GainRatio(A)=Gain(A)SplitInfo(A)
- CART:GINI系数
- Gini(D)=1−∑mi=1p2i
决策树剪枝
- 剪枝原因:过拟合风险大
- 预剪枝
- 限制深度,页子节点个数,页子节点样本数,信息增益量
- 可以选择特征??
- 后剪枝
- 在决策树构建完成之后,通过一定的标准决定剪掉哪些枝叶
集成算法(Ensemble Learning)
- Bagging:选了多个分类器取平均值(典型例子:随机森林)
- 数据随机,特征随机
- 优点:
- 处理高纬度,不用特征选择
- 可以计算出特征的重要程度,通过破坏特征,比较之间的差值
- 并行运算,速度快
- 可视化展示
- 一般生成100-200棵树,就好,因为树多了效果不一定好
- Boosting(提升模型):从弱学习开始(AdBoost,xgBoost),串行计算
- Stacking(堆叠模型):聚合多个分类
- 通常套路:使用多个算法计算出结果,把结果作为作为输入再次使用一个算法计算结果















 242
242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









