









课程概要:
1.生成学习算法(Generative learning algorithm)
2.高斯判别分析(GDA,Gaussian Discriminant Analysis)
3.GDA与logistic模型的联系
4.朴素贝叶斯(Naive Bayes)
5.拉普拉斯平滑(Laplace smoothing)
一、生成学习算法
两种学习算法的定义
1 判别学习算法:直接学习p(y|x),其中x是某类样例的特征,y是某类样例的分类标记。即给定输入特征,输出所属的类或学习得到一个假设hθ(x),直接输出0或1。通俗的说就是直接对问题求解,比如logistic算法,在解空间中寻找一条直线从而把两种类别的样例分开。
2生成学习算法: 对p(x|y)(条件概率),p(y)(先验概率)进行建模,p(x|y)表示在给定所属的类的情况下,显示某种特征的概率。
然后根据贝叶斯公式(Bayes rule)推导出y在给定x的概率为:
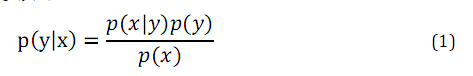
使得后验概率最大的类别y即是新样例的预测值:
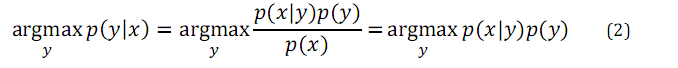
二、高斯判别分析
高斯判别分析(GDA)算法即为一种生成学习算法。
高斯判别分析的两个假设:
- 假设输入特征x∈Rn,并且是连续值;
- p(x|y)是多维正态分布(即高斯分布);
多维正态分布是正态分布在多维变量下的拓展。均值向量(mean vector)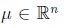
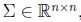
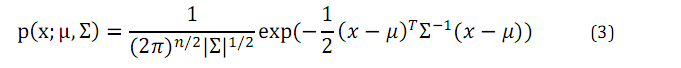
其中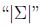
对于服从多维正态分布的随机变量x,均值由下面的公示得到:
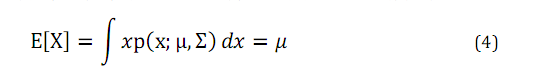
协方差矩阵与协方差函数得到:
Cov(Z)=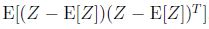
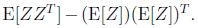
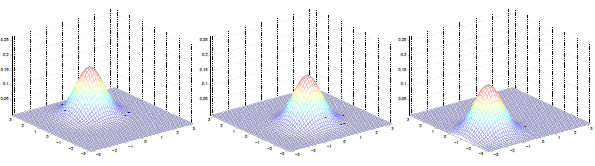
对于多维高斯分布只要注意上述两个参数即可。
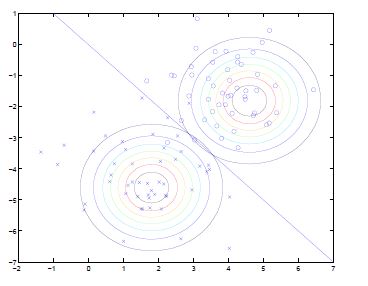
多维高斯分布图像与参数的关系
左图:μ=0,∑=I(单位矩阵)
中图:μ=0,∑=0.6I,图形变陡峭
右图:μ=0,∑=2I,图形变扁平
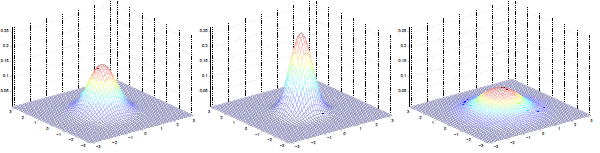
三图中μ=0,∑如下:
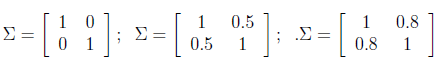
可见增加矩阵对角元素的值,即变量间增加相关性,高斯曲面会沿z1=z2(两个水平轴)方向趋于扁平。其水平面投影图如下:
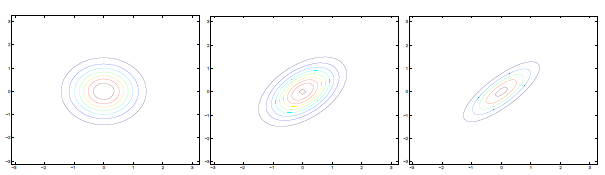
即增加∑对角线的元素,图形会沿45°角,偏转成一个椭圆形状。
若∑对角线元素为负,图形如下:
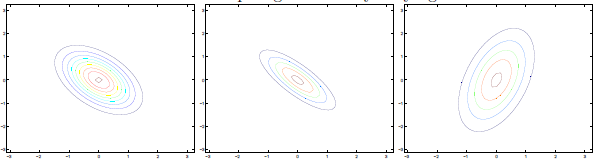
∑分别为:
不同μ的图形如下:
μ分别为:
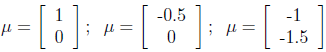
多维高斯分布图像与参数总结:
μ决定分布曲线中心的位置。
协方差 ∑决定陡峭程度。GDA模型
GDA模型针对的是输入特征为连续值时的分类问题。
这个模型的额基本假设是目标值y服从伯努利分布,条件概率p(x|y)服从多维正态分布。所以,他们的概率密度为:
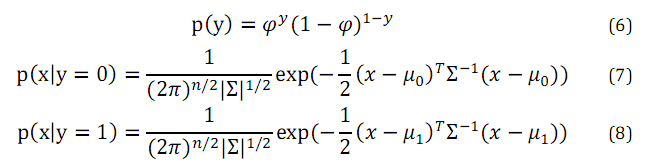
所以数据集的极大似然函数的对数如下所示:
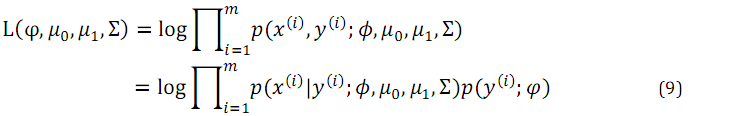
各个参数的极大似然估计如下:
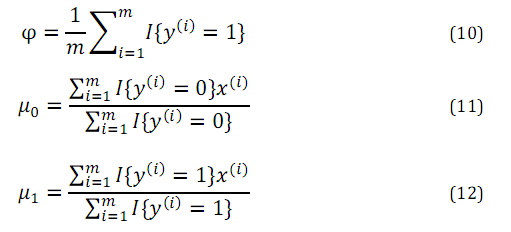
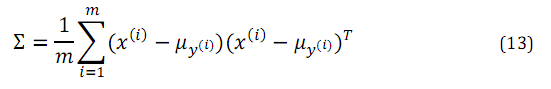
三、GDA与logistics模型的联系
GDA模型和logistic回归有一个很有意思的关系.
如果把 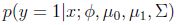
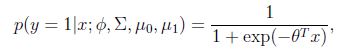
其中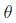
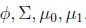
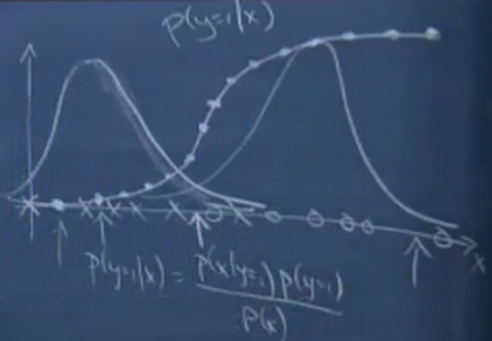
关于模型的选择:
刚才说到如果p(x|y)是一个多维的高斯分布,那么p(y|x)必然能推出一个logistic函数;反之则不正确,p(y|x)是一个logistic函数并不能推出p(x|y)服从高斯分布.这说明GDA比logistic回归做了更强的模型假设.
- 如果p(x|y)真的服从或者趋近于服从高斯分布,则GDA比logistic回归效率高.
- 当训练样本很大时,严格意义上来说并没有比GDA更好的算法(不管预测的多么精确).
- 事实证明即使样本数量很小,GDA相对logisic都是一个更好的算法.
但是,logistic回归做了更弱的假设,相对于不正确的模型假设,具有更好的鲁棒性(robust).许多不同的假设能够推出logistic函数的形式. 比如说,如果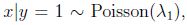
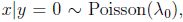
GDA优点:预测更精确,需要的数据少。缺点:做的假设更强,需要数据服从高斯分布才会有很好的效果。
logistic适用范围更广,鲁棒性好。缺点:需要数据多,如果数据近似服从高斯分布,不如GDA回归的好。
四、朴素贝叶斯
朴素贝叶斯(NB)也是一种学习算法。GDA针对的是特征向量x为连续值时的问题,而朴素贝叶斯则针对的是特征向量x为离散值时的问题。
朴素贝叶斯最常用与文本的分类,例如甄别邮件是否为垃圾邮件。
例子:垃圾邮件分类问题
首先是把一封邮件作为输入特征,与已有的词典进行比对,如果出现了该词,则把向量的xi=1,否则xi=0,例如:

我们要对p(x|y)建模,但是假设我们的词典有50000个词,那么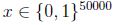
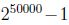
为了对p(x|y)建模,我们做一个很强的假设,假设给定y,xi是条件独立(conditionally independent)的.这个假设成为朴素贝叶斯假设(Naive Bayes assumption).
因此得到下式:
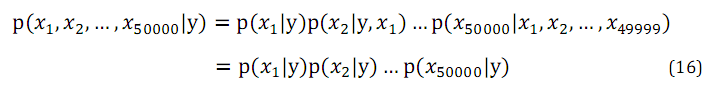
朴素贝叶斯假设在文本分类问题上的解释为文本中出现某词语时不会影响其他词语在文本中出现的频率。
模型中的参数有:
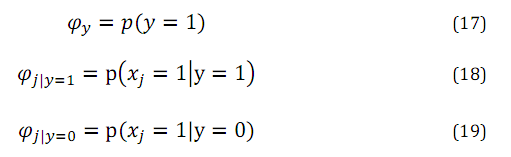
于是,我们就得到了NB方法的极大似然估计函数:
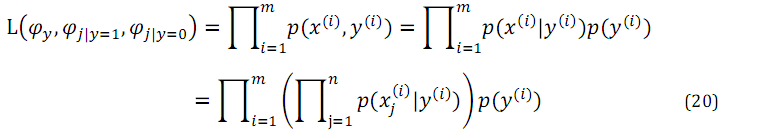
其中n为词典大小,最大化该函数,我们得到参数的极大似然估计:
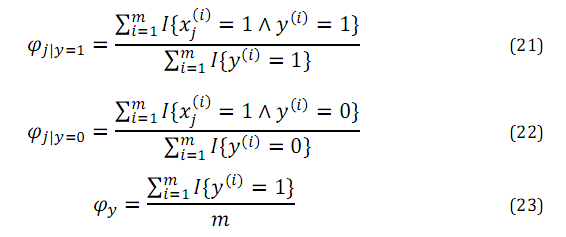
Φi|y=1的分子为标记为1的邮件(垃圾邮件)中出现词j的邮件数目和,分母为垃圾邮件数,总体意义就是训练集中出现词j的垃圾邮件在垃圾邮件中的比例。
Φi|y=0就是出现词j的非垃圾邮件在非垃圾邮件中的比例。
Φy就是垃圾邮件在所有邮件中的比例。
求出上述参数,就知道了p(x|y)和p(y),用伯努利分布对p(y)建模,用上式中p(xi|y)的乘积对p(x|y)建模,通过贝叶斯公式就可求得p(y|x)
对于新样本,按照如下公式计算其概率:
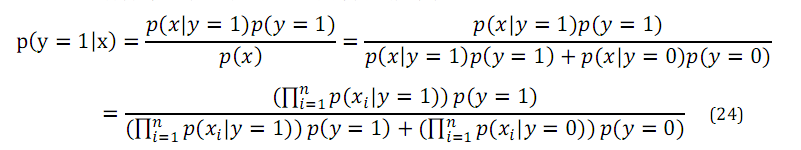
总结:朴素贝叶斯的总体思想即根据贝叶斯公式,先求条件概率与先验概率,在得出结果。具体在本例中即先分别求出为垃圾邮件时出现某词的频率,和为非垃圾邮件时出现某词的频率以及垃圾邮件的频率,然后根据贝叶斯公式,求出出现某词时为垃圾邮件的频率
朴素贝叶斯的问题:
假设在一封邮件中出现了一个以前邮件从来没有出现的词,在词典的位置是35000,那么得出的最大似然估计为:
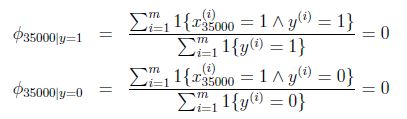
也即使说,在训练样本的垃圾邮件和非垃圾邮件中都没有见过的词,模型认为这个词在任何一封邮件出现的概率为0.
假设说这封邮件是垃圾邮件的概率比较高,那么
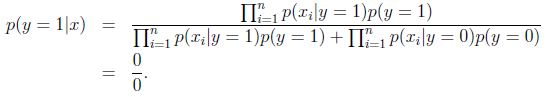
模型失灵.
在统计上来说,在你有限的训练集中没有见过就认为概率是0是不科学的.
五、拉普拉斯平滑
拉普拉斯平滑又称为加1平滑,是比较常用的平滑方法,使用拉普拉斯平滑即可解决上述概率为0的问题。
对于一个随机变量,它的取值范围是{1,2,3...k},m次实验后的观测结果为Z(i),极大似然估计按照下式计算:
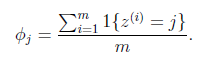
即值为j的样本所占比例,对其用Laplace平滑如下式:
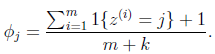
回到朴素贝叶斯问题,通过laplace平滑:
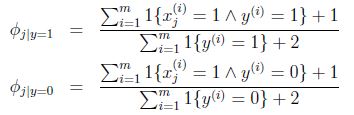
分子加1,分母加1就把分母为零的问题解决了.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









