




 本文介绍了自学习(Self-taught Learning)的概念,强调了在机器学习中使用大量未标注数据提升性能的重要性。通过稀疏自编码器进行无监督特征学习,然后结合少量已标注数据使用有监督学习进行分类。自学习与半监督学习的区别在于未标注数据的分布,自学习应用更加广泛。以手写体识别为例,详细阐述了自学习算法的步骤,并提供了实验结果链接和主要参考文献。
本文介绍了自学习(Self-taught Learning)的概念,强调了在机器学习中使用大量未标注数据提升性能的重要性。通过稀疏自编码器进行无监督特征学习,然后结合少量已标注数据使用有监督学习进行分类。自学习与半监督学习的区别在于未标注数据的分布,自学习应用更加广泛。以手写体识别为例,详细阐述了自学习算法的步骤,并提供了实验结果链接和主要参考文献。
简介
如果已经有一个足够强大的机器学习算法,为了获得更好的性能,最靠谱的方法之一是给这个算法以更多的数据。机器学习界甚至有个说法:“有时候胜出者并非有最好的算法,而是有更多的数据。”
在自学习和无监督特征学习问题上,可以给算法以大量的未标注数据,学习出较好的特征描述。在尝试解决一个具体的分类问题时,可以基于这些学习出的特征描述和任意的(可能比较少的)已标注数据,使用有监督学习方法完成分类。
我们已经了解到如何使用一个自编码器(autoencoder)从无标注数据中学习特征。假定有一个无标注的训练数据集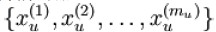
利用训练得到的模型参数W和b,给定任意的输入数据 x,可以计算隐藏单元的激活量(activations)a 。如前所述,相比原始输入 x 来说,a可能是一个更好的特征描述。下图的神经网络描述了特征(激活量 )的计算。
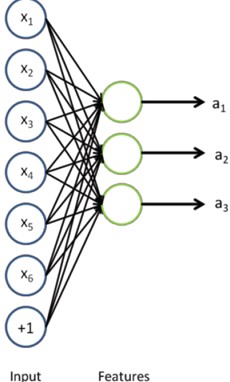
这实际上就是之前得到的稀疏自编码器,在这里去掉了最后一层。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8256
8256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









