







ImageNet数据集和cifar,mnist数据集最大的不同,就是数据量特别大;单张图片尺寸大,训练样本个数多;面对如此大的数据集,在转换成lmdb文件时;使用了很多新的类型对象。
1,动态扩容的数组“vector”,动态地添加新元素
2,pair类型数据对,用于存储成对的对象,例如存储文件名和对应标签
3,利用opencv中的图像处理函数,来读取和处理大尺寸图像
一:程序开始
由于要向imageNet数据集中设置resize和是否乱序等参数,所以本文使用gflags命令行解析工具;在Create.sh文件中,调用convert_imageset.bin语句为:
<pre name="code" class="cpp">GLOG_logtostderr=1$TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \ 图像数据集存放的根目录
$DATA/train.txt \ 图像的ID和对应的分类标签数字
$EXAMPLE/ilsvrc12_train_lmdb lmdb文件保存的路径65ILSVRC2012_val_00000002.JPEG ,65应该是对应的标签,后面的是图像的编号id。
二:数据转换流程图

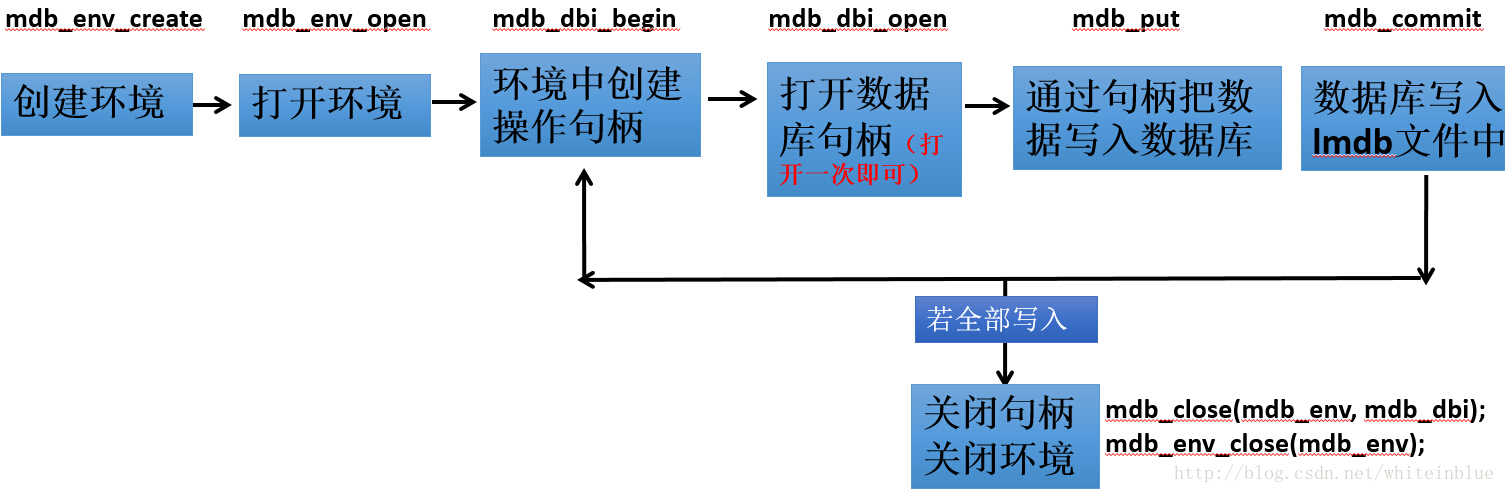
三:convert_imageset.cpp函数分析
1引入必要的头文件和命名空间
#include<algorithm>//输出数组的内容、对数组进行升幂排序、反转数组内容、复制数组内容等操作,
#include <fstream> // NOLINT(readability/streams)
#include <string>
#include<utility>//utility头文件定义了一个pair类型,pair类型用于存储一对数据
#include<vector>//会自动扩展容量的数组
#include "boost/scoped_ptr.hpp"//智能指针头文件
#include "gflags/gflags.h"
#include "glog/logging.h"
#include"caffe/proto/caffe.pb.h"
#include "caffe/util/db.hpp" //引入包装好的lmdb操作函数
#include "caffe/util/io.hpp" //引入opencv中的图像操作函数
#include "caffe/util/rng.hpp"1,引入gflags命令行解析工具;
2,引入utility头文件,里面提供了数组洗牌等操作
using namespace caffe; // NOLINT(build/namespaces)
using std::pair;
using boost::scoped_ptr;1,引入全部caffe命名空间
2,引入pair对命名空间
2 gflags宏定义参数
//通过gflags宏定义一些程序的参数变量
DEFINE_bool(gray, false,"When thisoption is on, treat images as grayscale ones");//是否为灰度图片
DEFINE_bool(shuffle, false,"Randomlyshuffle the order of images and their labels");//定义洗牌变量,是否随机打乱数据集的顺序
DEFINE_string(backend, "lmdb","The backend {lmdb, leveldb} for storing the result");//默认转换的数据类型
DEFINE_int32(resize_width, 0, "Width images areresized to");//定义resize的尺寸,默认为0,不转换尺寸
DEFINE_int32(resize_height, 0, "Height imagesare resized to");
DEFINE_bool(check_size, false,"When this optionis on, check that all the datum have the samesize");
DEFINE_bool(encoded, false,"When this option ison, the encoded image will be save in datum");//用于转换数据格式的
DEFINE_string(encode_type, "","Optional:What type should we encode the image as ('png','jpg',...).");//要转换的数据格式3 main()函数
没有想cifar和mnist的main函数,通过调用convert_data()函数来转换数据,而是直接在main函数内完成了所有数据转换代码。
3.1 通过gflags宏定义接收命令行中传入的参数
const boolis_color = !FLAGS_gray; //通过gflags把宏定义变量的值,赋值给常值变量
const boolcheck_size = FLAGS_check_size; //检查图像的size
const boolencoded = FLAGS_encoded;//是否编译(转换)图像格式
const stringencode_type = FLAGS_encode_type;//要编译的图像格式3.2.1创建读取对象变量
std::ifstream infile(argv[2]);//创建指向train.txt文件的文件读入流
std::vector<std::pair<std::string, int> > lines;//定义向量变量,向量中每个元素为一个pair对,pair对有两个成员变量,一个为string类型,一个为int类型;其中string类型用于存储文件名,int类型,感觉用于存数对应类别的id
如val.txt中前几个字符为“ILSVRC2012_val_00000001.JPEG65ILSVR
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









