






 本文详细介绍了如何利用双隐层网络进行手写数字识别,通过稀疏自编码器预训练提取特征,并最终使用softmax分类器实现分类任务。阐述了深度学习网络的训练过程、参数校正方法以及实际应用步骤,提供了完整的代码流程详解。
本文详细介绍了如何利用双隐层网络进行手写数字识别,通过稀疏自编码器预训练提取特征,并最终使用softmax分类器实现分类任务。阐述了深度学习网络的训练过程、参数校正方法以及实际应用步骤,提供了完整的代码流程详解。
本文分为三部分,前言和实验基础copy自tornadomeet博客;后面代码详解为自己原创。
前言:
本次是练习2个隐含层的网络的训练方法,每个网络层都是用的sparse autoencoder思想,利用两个隐含层的网络来提取出输入数据的特征。本次实验验要完成的任务是对MINST进行手写数字识别,实验内容及步骤参考网页教程Exercise: Implement deep networks for digit classification。当提取出手写数字图片的特征后,就用softmax进行对其进行分类。关于MINST的介绍可以参考网页:MNIST Dataset。本文的理论介绍也可以参考前面的博文:Deep learning:十六(deep networks)。
实验基础:
进行deep network的训练方法大致如下:
1. 用原始输入数据作为输入,训练出(利用sparse autoencoder方法)第一个隐含层结构的网络参数,并将用训练好的参数算出第1个隐含层的输出。
2. 把步骤1的输出作为第2个网络的输入,用同样的方法训练第2个隐含层网络的参数。
3. 用步骤2 的输出作为多分类器softmax的输入,然后利用原始数据的标签来训练出softmax分类器的网络参数。
4. 计算2个隐含层加softmax分类器整个网络一起的损失函数,以及整个网络对每个参数的偏导函数值。
5. 用步骤1,2和3的网络参数作为整个深度网络(2个隐含层,1个softmax输出层)参数初始化的值,然后用lbfs算法迭代求出上面损失函数最小值附近处的参数值,并作为整个网络最后的最优参数值。
上面的训练过程是针对使用softmax分类器进行的,而softmax分类器的损失函数等是有公式进行计算的。所以在进行参数校正时,可以对把所有网络看做是一个整体,然后计算整个网络的损失函数和其偏导,这样的话当我们有了标注好了的数据后,就可以用前面训练好了的参数作为初始参数,然后用优化算法求得整个网络的参数了。但如果我们后面的分类器不是用的softmax分类器,而是用的其它的,比如svm,随机森林等,这个时候前面特征提取的网络参数已经预训练好了,用该参数是可以初始化前面的网络,但是此时该怎么微调呢?因为此时标注的数值只能在后面的分类器中才用得到,所以没法计算系统的损失函数等。难道又要将前面n层网络的最终输出等价于第一层网络的输入(也就是多网络的sparse autoencoder)?本人暂时还没弄清楚,日后应该会想明白的。
关于深度网络的学习几个需要注意的小点(假设隐含层为2层):
- 利用sparse autoencoder进行预训练时,需要依次计算出每个隐含层的输出,如果后面是采用softmax分类器的话,则同样也需要用最后一个隐含层的输出作为softmax的输入来训练softmax的网络参数。
- 由步骤1可知,在进行参数校正之前是需要对分类器的参数进行预训练的。且在进行参数校正(Finetuning )时是将所有的隐含层看做是一个单一的网络层,因此每一次迭代就可以更新所有网络层的参数。
另外在实际的训练过程中可以看到,训练第一个隐含层所用的时间较长,应该需要训练的参数矩阵为200*784(没包括b参数),训练第二个隐含层的时间较第一个隐含层要短些,主要原因是此时只需学习到200*200的参数矩阵,其参数个数大大减小。而训练softmax的时间更短,那是因为它的参数个数更少,且损失函数和偏导的计算公式也没有前面两层的复杂。最后对整个网络的微调所用的时间和第二个隐含层的训练时间长短差不多。
以上复制来自:http://www.cnblogs.com/tornadomeet/archive/2013/04/09/3011209.html
代码流程详解:
Step0:
初始化网络参数,确定网络结构
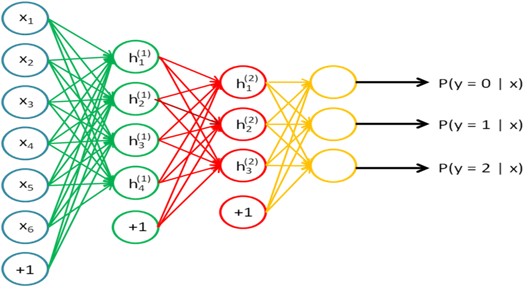
28*28 100 100 10
Inputsize hiddensizeL1 hiddensizeL1 numclass
W1=matrix(hiddensizeL1,inputsize)= matrix(100,764)
b1=vector(hiddensizeL1,1)=vector(100,1)
sae1Theta=[W1,b1];
W2=matrix(hiddensizeL2,hiddensizeL1)= matrix(100,100)
b2=vector(hiddensizeL2,1)=vector(100,1)
SoftmaxTheta=matrix(numclass,hiddensizeL2)=matrix(10,100)
Step1:加载数据
trainData = loadMNISTImages('../data/train-images-idx3-ubyte');
Step2:训练第一个稀疏自编码,得到W1和b1的优化权值
[sae1OptTheta,loss] = minFunc( @(p) sparseAutoencoderCost(p, ...
利用函数sparseAutoencoderCost()计算损失值和梯度;并利用minFunc的l-bfgs
算法进行优化,得到优化后的W1和b1的权值,sae1OptTheta=[W1,b1]。
Step3:训练第二个稀疏自编码,得到W2和b2的优化权值
1.
[sae1Features] = feedForwardAutoencoder(sae1OptTheta, ..
利用前馈函数feedForwardAutoencoder计算原始数据data的第一个特征表达sae1Features
2.
初始化W2和b2
sae2Theta = initializeParameters(hiddenSizeL2,hiddenSizeL1);
3.
利用函数sparseAutoencoderCost()计算损失值和梯度;并利用minFunc的算法进行优化,得到优化后的W2和b2的权值,sae2OptTheta=[W2,b2]。
Step4:训练softmax分类器
1.
[sae2Features] = feedForwardAutoencoder(sae2OptTheta,hiddenSizeL2, ...hiddenSizeL1, sae1Features);
利用前馈函数和第一次特征表达sae1Features计算第二层特征表达sae2Features 作为softmax分类器的输入数据
2.
初始化softmax分类器的参数theta,用小数值随机初始化
saeSoftmaxTheta = 0.005 * randn(hiddenSizeL2 *numClasses, 1);
3.
训练softmax分类器
softmaxModel = softmaxTrain(hiddenSizeL2, numClasses,1e-4, ... sae2Features,trainLabels, options);
softmaxTrain函数的输出参数softmaxModel为一个结构体,即struct;其中包含三个子属性值
softmaxModel.optTheta =reshape(softmaxOptTheta, numClasses, inputSize); %分类器的参数theta
softmaxModel.inputSize = inputSize; %分类器的输入参数个数
softmaxModel.numClasses = numClasses; %分类器的种类
3.1
优化参数theta
在softtrain中调用的函数softmaxcost,类似sparseAutoencoderCost函数,通过softmax分类器模型来计算函数损失值和梯度值,之后通过l-bfgs算法来优化。
Step5:微调fine-tuning softmax模型
Setp5就是这个算法的关键部分了,首先这个算法叫做stackedautoencoder,栈式自编码,其中这个“栈”,也就是stack,就体现在这里。这里的stack就是一个元包(cell),cell的元素是各个参数矩阵,即W1,b1等。通过stack的初始化,把这个深度网络结构的所有参数W1,b1,W2,b2合并(打包)到stack中;后续计算中通过打包(params2stack函数完成)与拆包(stack2params)函数完成)来计算更新各个权值。
5.1 参数打包到stack中,进行栈化
stack = cell(2,1);%定义一个包含2个元包的元包矩阵(额,称呼有些不恰当)
stack{1}.w =reshape(sae1OptTheta(1:hiddenSizeL1*inputSize), ...hiddenSizeL1, inputSize);
stack{1},是调用stack中的第一个元包,第一个元包的数据类型是结构体struct;里面包含W1和b1两个属性值。
stack{1}.w = weights of first layer=W1
stack{1}.b = weights of first layer=b1
stack{2}.w = weights of second layer=W2
stack{2}.b = weights of second layer=b2
[stackparams, netconfig] = stack2params(stack);
stackedAETheta = [ saeSoftmaxOptTheta ; stackparams ];%合并网络参数和分类器参数。
5.1.1 stack2params函数说明
[stackparams, netconfig] =stack2params(stack);
把栈stack转换为params的过程,其输出参数为两个,一个是向量化后的网络参数stackparams,一个是网络配置结构参数netconfig;这种方式感觉很简洁,应为我们训练神经网络最后要得到的就是网络结构和结构件的连接权重,stackparams来记录网络的连接权重,netconfig来记录网络的配置结构;这样就把一个复杂的网络,通过两个略微复杂的变量记录下来,方便后续的应用和计算。
函数部分一:
打包过程,stack向量化
for d = 1:numel(stack)
params = [params ; stack{d}.w(:) ; stack{d}.b(:) ];
end
assert函数说明:
MATLAB语言没有系统的断言函数,但有错误报告函数error 和 warning。由于要求对参数的保护,需要对输入参数或处理过程中的一些状态进行判断,判断程序能否/是否需要继续执行。
其中的assert函数,类似if函数,判断程序是否进行
assert(size(stack{d}.w, 1) == size(stack{d}.b, 1), ['The biasshould be a *column* vector of ' int2str(size(stack{d}.w,1)) 'x1']);
等价于:
If size(stack{d}.w,1) ~= size(stack{d}.b, 1)
temp= int2str(size(stack{d}.w, 1));
error(‘The biasshould be a *column* vector of ‘temp’x1’)
end
用来判断stack{d}.w的行数和stack{d}.b的行数是否相同,都等于隐层节点数目。
函数部分二:
netconfig(netconfiguration,网络配置)部分,记录网络各层的配置参数(节点数)。
变量nargout,是matlab函数自带的“隐藏”变量,判断函数中输出参数个数的变量,n arg out
if nargout> 1 …… end %如果本函数的输出参数大于一个,则执行下面的代码
netconfig变量是一个struct变量,有inputsize(一个数值)和layersizes(一个量)向两个子属性。
netconfig.inputsize = size(stack{1}.w, 2);netconfig.layersizes= {};
for d = 1:numel(stack)
netconfig.layersizes = [netconfig.layersizes ;size(stack{d}.w,1)];
end
遍历stack的所有元包,通过size(stack{d}.w,1),来记录网络每层的节点数。
5.2
利用stackedAECost函数计算梯度和函数损失值,并用l-bfgs算法优化
stackedAECost函数说明
1.把向量化参数theta还原为矩阵形式
softmaxTheta =reshape(theta(1:hiddenSize*numClasses), numClasses, hiddenSize);
stack =params2stack(theta(hiddenSize*numClasses+1:end), netconfig);
2.初始化梯度矩阵softmaxThetaGrad和梯度栈stackgrad
softmaxThetaGrad = zeros(size(softmaxTheta));
stackgrad = cell(size(stack));
for d = 1:numel(stack)
stackgrad{d}.w = zeros(size(stack{d}.w));
stackgrad{d}.b = zeros(size(stack{d}.b));
end
3.前馈计算神经网络
depth = numel(stack);%获取栈中元包个数,即网络的层数
z = cell(depth+1,1);
a = cell(depth+1, 1);%记录原始输入数据和各层的输出激活值a
a{1} = data;
for layer = (1:depth)
z{layer+1} = stack{layer}.w * a{layer} + repmat(stack{layer}.b, [1,size(a{layer},2)]);%前馈计算w*x+b
a{layer+1} = sigmoid(z{layer+1});%利用sigmoid函数进行非线性变换
end
4.计算softmax分类器
M = softmaxTheta * a{depth+1}; %计算theta*x
M = bsxfun(@minus, M, max(M));%参数theta冗余消除,就是把参数变小
p = bsxfun(@rdivide, exp(M), sum(exp(M)));%概率归一化操作
cost = -1/numCases * groundTruth(:)' *log(p(:)) + lambda/2 * sum(softmaxTheta(:) .^ 2);%计算softmax函数值y
softmaxThetaGrad = -1/numCases * (groundTruth- p) * a{depth+1}' + lambda * softmaxTheta;%计算梯度值,并更新
5.反向传播,计算各层梯度
d = cell(depth+1);%存放梯度的元包
d{depth+1} = -(softmaxTheta' * (groundTruth -p)) .* a{depth+1} .* (1-a{depth+1});%计算最后一层(softmax)的梯度值
for layer = (depth:-1:2)
d{layer} = (stack{layer}.w' * d{layer+1}) .* a{layer} .* (1-a{layer});%通过反向传播机制计算各层的梯度
end
6.梯度跟新
for layer = (depth:-1:1)
stackgrad{layer}.w = (1/numCases) * d{layer+1} * a{layer}';%梯度更新
stackgrad{layer}.b = (1/numCases) * sum(d{layer+1}, 2);
end
Step6:预测精确度
1.加载测试数据
testData = loadMNISTImages('../data/t10k-images-idx3-ubyte');
2.用没有经过微调的参数进行预测
[pred] = stackedAEPredict(stackedAETheta, inputSize, hiddenSizeL2, ...numClasses,netconfig, testData);
stackedAEPredict()函数说明
部分一:拆包,把参数矩阵化
softmaxTheta = reshape(theta(1:hiddenSize*numClasses), numClasses,hiddenSize);
stack= params2stack(theta(hiddenSize*numClasses+1:end), netconfig);
部分二:前馈网络计算
for layer = (1:depth)
z{layer+1} = stack{layer}.w * a{layer} +repmat(stack{layer}.b, [1, size(a{layer},2)]);
a{layer+1} = sigmoid(z{layer+1});
end
[~,pred] = max(softmaxTheta * a{depth+1});
%pred=max(a),结果pred是矩阵a每列的最大值;[~, pred]=max(a),则pred是矩阵a每列最大值的位置索引,此处为对应的类型
3.预测输出
acc = mean(testLabels(:) ==pred(:));
fprintf('Before Finetuning Test Accuracy: %0.3f%%\n', acc * 100);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









