







The new architecture utilizes two proposed operations, point wise group convolution and channel shuffle, to greatly reduce computation cost while maintaining accuracy.
该论文利用了point wise group convolution和channel shuffle两种技术进行了网络模型的搭建,在保证精度的前提下,大大的降低了计算量。
- pointwise group convolution:为了减少1x1卷积的操作带来的操作量。原先的卷积在所有通道上进行,作者把所有通道进行分组卷积,类似mobileNet中采用的depthwise separable convolution。(1x1卷积在很多基础模型上,都大量使用,作用也是用来减少计算量的,本文对1x1卷积更进一步,分组卷积,从而进一步降低计算量)
- shuffle channel操作:就是在分组卷积的基础上,打乱不同通道的排序,使得下一层的操作的输入能吸收来上一层不同组的内容,使得学习更佳均衡。(该思想早在AlexNet时,就采用过,当时分组的目的是由于当时的GPU显存不够,不得已而为之)
目的
保证精度的前提下,尽量减小模型的大小和计算量,从而可以在移动终端(手机)或者嵌入式设备上进行部署。
类似的工作有:
- GoogLeNet increases the depth of networks with much lower complexity compared to simply stacking convolution layers【将卷积在宽度和深度两个方向进行了拓展】
- SqeezeNet reduces parameters and computation significantly while maintaining accuracy.【利用fire module将1x1,3x3卷积拼接到一起】
- ResNet utilizes the efficient bottleneck structure to achieve impressive performance.【利用skip connection,学习残差比学习其他函数要快很多】
- Depthwise separable convolution proposed in Xception generalizes the ideas of separable convolutions in Inception series.【如何将Inception模块的思想过渡到分层卷积,运用分层卷积+残差思想】
- MobileNet utilizes the depth wise separable convolutions and gains state-of-art results among lightweight models.【利用分层卷积,达到AlexNet级别效果,但参数量少很多】
网络结构
(1)Channel Shuffle
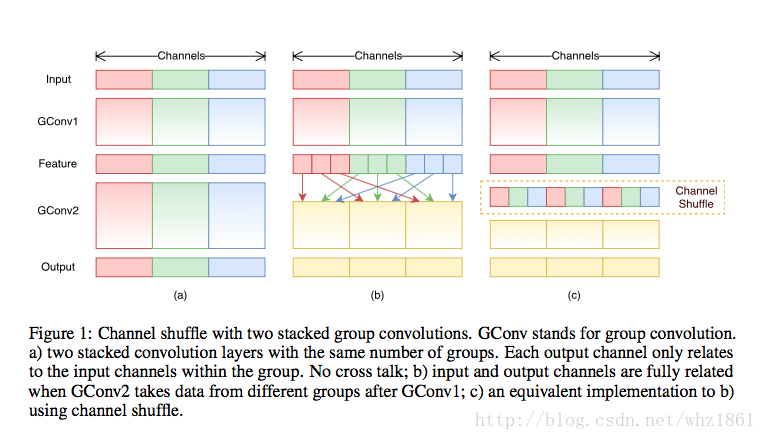
- 最左侧的卷积不同组之间完全分离,每一层卷积只一类自己的上一层。学习特征完全独立,不利于网络的收敛性。
- 中间和右侧的效果是,每一组结构都能得到不同层传过来的信息,从而使整个网络更佳健壮,稳定性和容错性更好,也是一种正则化的表现【感觉有点类似于dropout的感觉,使得不同路径都能学习到对最终结果有帮助的信息】。
(2)Shuffle Units
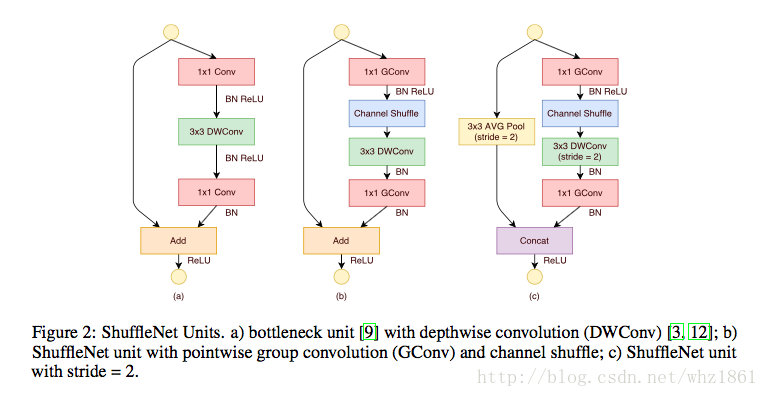
- 最左侧的为残差的基本模块
- 中间在卷积开始的时候,利用了channel shuffle操作,前面的1x1卷积主要起到分组的效果
- 在中间形式的基础上,做了两点修改:
- 整个结构是一个pooling的过程,图像尺寸减小了一倍
- 左侧不是直接连接过来,应为特征的尺寸发生了变化,从而采用的是一个average pooling操作
- 最终的连接不是add操作,而是concat操作,目的是在讲少特征大小的时候,增加特征的深度,保持网络的表达能力
(3)整体结构
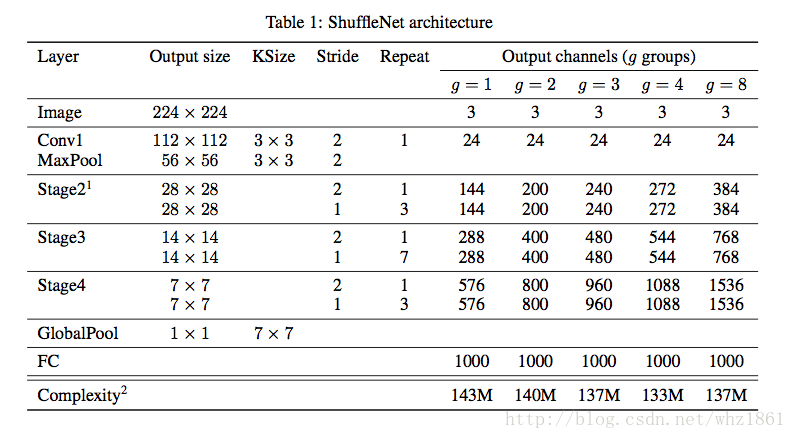
- 每一个stage开始的时候,都是采用Channel Units中的c结构,对特征进行降维(stride=2),特征深度加倍
- 令bottleneck的特征图深度是每一个shuffle unit输出特征图的1/4
- 参数
g
表示分组个数,
g 越大,表示point convolutions的连接越稀疏。
实验结果与分析
实验一:
对比不同分组对模型的影响
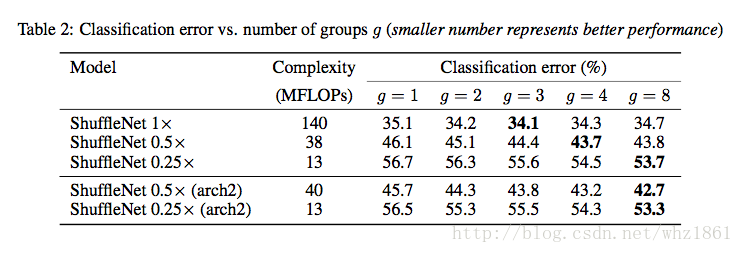
- 结果最好的模型为shuffleNet 1x 且 g=3
- 随着模型参数的减少,每个系列最好的模型,会往 g 增大的方向便宜。这个间接的说明了,当网络参数较少的时候,shuffleNet中的分组数量能发挥更大的作用
- group convolution操作能够使得模型在相同计算复杂度的情况下,获得更多的feature map channels,而这也实验三中,对比不同基础结构中获得了证明
- 论文中,将shuffleNet中的stage3去掉,然后增加其他层的feature map,在相同的计算复杂度的情况下,模型的效果也是在
g=8 ,分层越多的情况下获取,而且比对应的shuffleNet 0.5x, shuffleNet 0.25x效果要好,也再次证明了,作者提出的feature map channel 越多,最终的效果越好
实验二:
探讨shuffle channel操作的作用
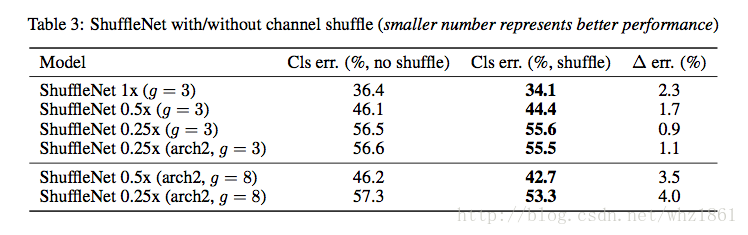
- 通过对比使用shuffle操作和不适用shuffle操作带来的效果,可以看出,shuffle在模型上,起到了非常大的作用。
实验三:
在相同计算复杂度前提下,对比不同基础结构的效果
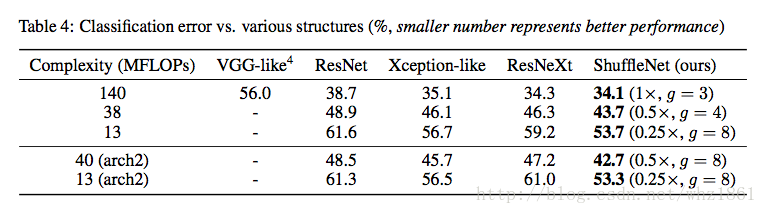
- 和其他基础结构(VGG, ResNet, Xception-like, ResNeXt)相比,shuffleNet在相同计算复杂度的前提下具有非常明显的优势。【作者分析,这个主要是由shuffleNet相比其他基础结构拥有更多的channel,论文也提到,随着channel的增加,哥哥基础结构的效果也成上升趋势】
实验四
对比MobileNet网络结构
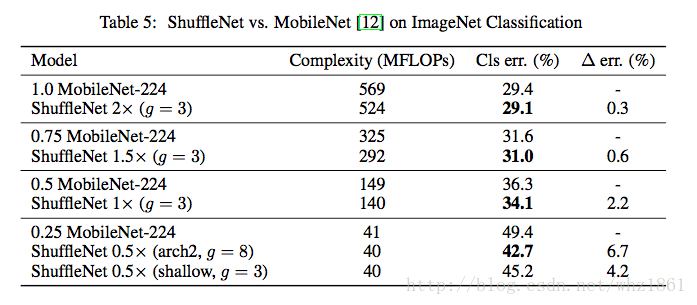
- 和mobile相比,在相同计算复杂度的情况下,shuffleNet表现更好
- 在Complexity(~40 MFloaps)情况下,shuffleNet超过了MobileNet 6.7%
- 即使将ShuffleNet的网络结构减半(ShuffleNet 0.5x shallow, g=3),模型的效果也比MobileNet要好
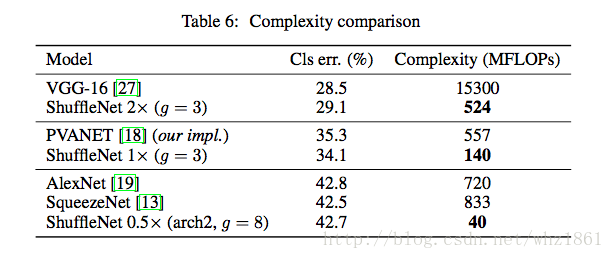
- 和其他模型相比,在相同精度的前提下,模型的参数要少很多
实验五
讨论ShuffleNet的检测方向的推广能力
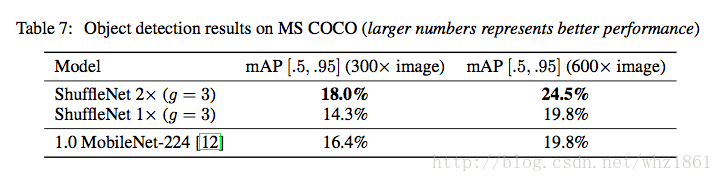
- 模型在检测领域的推广能力也得到了证实
实验五
讨论ShuffleNet的运算速度
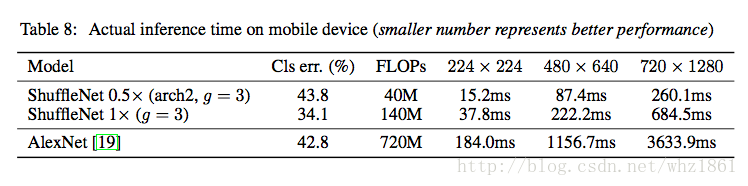
- 相比AlexNet的运算速度,ShuffleNet有了明显提升
参考文献
https://arxiv.org/abs/1707.01083
http://m.blog.csdn.net/u014380165/article/details/75137111
http://blog.csdn.net/shuzfan/article/details/77141425
http://baijiahao.baidu.com/s?id=1572512027246277&wfr=spider&for=pc
http://blog.csdn.net/c602273091/article/details/75137878














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









