







一、为什么要shuffle?shuffle有什么作用?
- 防止过拟合
- 随机优化(梯度下降),容易找到最优解,容易收敛
- 机器学习,前提假设是独立同分布。不论是机器学习还是深度学习,我们总是基于数据独立同分布的假设条件,也就是说,数据的出现应该是随机的,而不是按照某种顺序排列好的。以上就是需要shuffle的根本原因。因此,我们需要在每个epoch的开始把数据shuffle一下
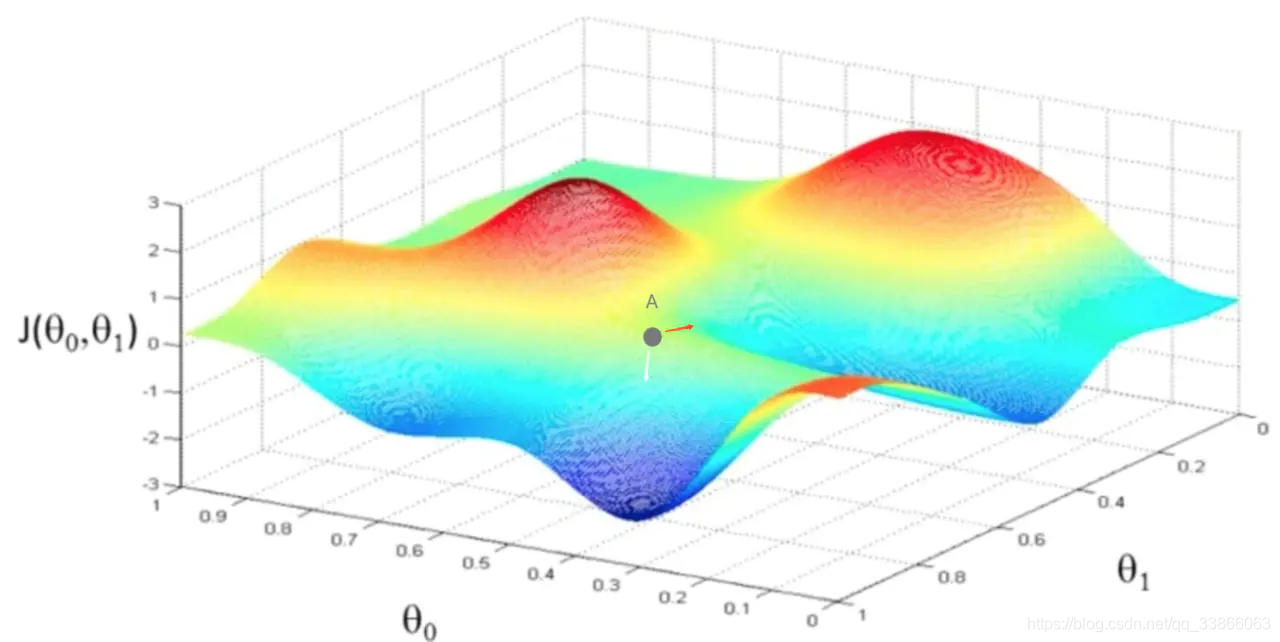
参考掘金的一篇博文,如下图,我们用梯度下降来优化损失函数J,在给定参数W和学习步长时,固定顺序的数据集(假设相同类别的样本都紧密排列),如果不随机打乱样本,那么,在一段时间内,收敛方向会沿着某一个类别,即同一个方向进行,如下图的红色箭头。打乱样本的目的,就是为了使得收敛的方向更加随机化,有机会转向白色箭头,向最优解收敛。
固定的数据集顺序,严重限制了梯度优化方向的可选择性,导致收敛点选择空间严重变少,容易导致过拟合。模型是会记住数据路线的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2291
2291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









