








在VirtualBox 上建Ubantu虚机,安装Anaconda,Java 8,Spark,IPython Notebook,以及和Hello world 齐名的wordcount 例子程序。
搭建Spark 环境
本节我们学习搭建 Spark环境:
- 在Ubuntu 14.04的虚拟机上创建隔离的开发环境,可以不影响任何现存的系统
- 安装 Spark 1.3.0 及其依赖.
- 安装Anaconda Python 2.7 环境包含了所需的库 例如Pandas, Scikit-Learn, Blaze, and Bokeh, 使用PySpark, 可以通过IPython Notebooks访问
- 在我们的环境中搭建后端或数据存储,使用MySQL作为关系型数据库;MongoDB作文档存储;Cassandra 作为列存储数据库。 根据所需处理数据的需要,每种存储服务于不同的特殊目的。MySQL RDBMs可以使用SQL轻松地完成表信息查询;如果我们处理各种API获得的大量JSON类型数据, 最简单的方法是把它们存储在一个文档里;对于实时和时间序列信息,Cassandra 是最合适的列存储数据库.
下图给出了我们将要构建的环境视图 将贯穿本书的使用:
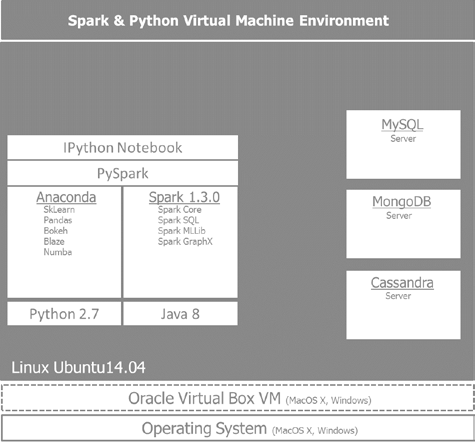
在Oracle VirtualBox 搭建Ubuntu
搭建一个运行Ubuntu 14.04的virtualbox环境是搭建开发环境最安全的办法,可以避免与现存库的冲突,还可以用类似的命令将环境复制到云端。
为了搭建Anaconda和Spark的环境,我们要创建一个运行Ubuntu 14.04的virtual box虚拟机.
步骤如下:
1. Oracle VirtualBox VM从 https://www.virtualbox.org/wiki/Downloads 免费下载,径直安装就可以了.
2. 装完 VirtualBox,打开Oracle VM VirtualBox Manager,点击按钮New.
3. 给新的VM指定一个名字, 选择Linux 类型和Ubuntu(64 bit)版本.
4. 需要从Ubuntu的官网下载ISO的文件分配足够的内存(4GB推荐) 和硬盘(20GB推荐).我们使用Ubuntu 14.04.1 LTS版本,下载地址: http://www.ubuntu.com/download/desktop.
5. 一旦安装完成, 就可以安装VirtualBox Guest Additions了 (从VirtualBox 菜单,选择新运行的VM) Devices|Insert Guest Additions CD image. 由于windows系统限制了用户界面,可能会导致安装失败.
6. 一旦镜像安装完成,重启VM,就已经可用了.打开共享剪贴板功能是非常有帮助的。选择VM点击 Settings, 然后General|Advanced|Shared Clipboard 再点击 Bidirectional.
安装Anaconda的Python 2.7版本
PySpark当前只能运行在Python 2.7(社区需求升级到Python 3.3),安装Anaconda, 按照以下步骤:
1. 下载 Linux 64-bit Python 2.7的Anaconda安装器 http://continuum.io/downloads#all.
2. 下载完Anaconda 安装器后, 打开 terminal进入到它的安装位置.在这里运行下面的命令, 在命令中替换2.x.x为安装器的版本号:
#install anaconda 2.x.x
#bash Anaconda-2.x.x-Linux-x86[_64].sh
3. 接受了协议许可后, 将让你确定安装的路径 (默认为 ~/anaconda).
4. 自解压完成后, 需要添加 anaconda 执行路径到 PATH 的环境变量:
# add anaconda to PATH
bash Anaconda-2.x.x-Linux-x86[_64].sh 安装 Java 8
Spark运行在 JVM之上所以需要安装Java SDK而不只是JRE, 这是我们构建spark应用所要求的. 推荐的版本是Java Version 7 or higher. Java 8 是最合适的, 它包安装 Java 8, 安装以下步骤:
1. 安装 Oracle Java 8 使用的命令如下:
# install oracle java 8
$ sudo apt-get install software-properties-common
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get install oracle-java8-installer
2. 设置 JAVA_HOME 环境变量,保证Java 执行程序在PATH中.
3. 检查JAVA_HOME 是否被正确安装:
#
$ echo JAVA_HOME安装 Spark
首先浏览一下Spark的下载页 http://spark.apache.org/downloads.
html.
它提供了多种可能来下载Spark的早期版本,不同的分发包和下载类型。 我们选择最新的版本. pre-built for Hadoop 2.6 and later. 安装 Spark 的最简方法是使用 Spark
package prebuilt for Hadoop 2.6 and later, 而不是从源代码编译,然后 移动 ~/spark 到根目录下。下载最新版本 Spark—Spark 1.5.2, released on November 9, 2015:
1. 选择Spark 版本 1.5.2 (Nov 09 2015),
2. 选择包类型 Prebuilt for Hadoop 2.6 and later,
3. 选择下载类型 Direct Download,
4. 下载spark: spark-1.5.2-bin-hadoop2.6.tgz,
5. 验证 1.3.0 签名校验,也可以运行:
# download spark
$ wget http://d3kbcqa49mib13.cloudfront.net/spark-1.5.2-bin-hadoop2.6.tgz
接下来, 我们将提取和清理文件:
#extract,clean up,move the unzipped files under the spark directory
$ rm spark-1.5.2-bin-hadoop2.6.tgz
$ sudo mv spark-* spark
现在,我们能够运行 Spark 的 Python 解释器了:
# run spark
$ cd ~/spark
./bin/pyspark应该可以看到类似这样的效果:
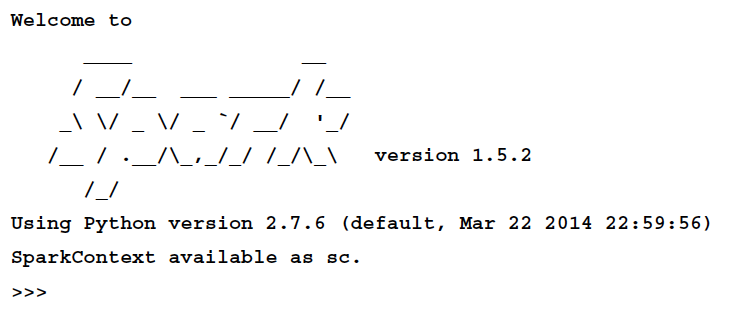
解释器已经提供了一个Spark context 对象, sc, 我们可以看到:
>>>print(sc)
<pyspark.context.SparkContext object at 0x7f34b61c4e50>
使用 IPython Notebook
IPython Notebook 比控制台拥有更更友好的用户体验.
可以使用如新命令启动IPython Notebook:
$ IPYTHON_OPTS="notebook --pylab inline" ./bin/pyspark
在目录 examples/AN_Spark,启动PySpark和IPYNB或者在Jupyter或
IPython Notebooks 的安装目录启动:
# cd to /home/an/spark/spark-1.5.0-bin-hadoop2.6/examples/AN_Spark
$ IPYTHON_OPTS='notebook' /home/an/spark/spark-1.5.0-bin-hadoop2.6/bin/
pyspark --packages com.databricks:spark-csv_2.11:1.2.0
#launch command using python 3.4 and the spark-csv package:
$ IPYTHON_OPTS='notebook' PYSPARK_PYTHON=python3
/home/an/spark/spark-1.5.0-bin-hadoop2.6/bin/pyspark --packages com.databricks:spark-csv_2.11:1.2.0构建在 PySpark上的第一个应用
我们已经检查了一切工作正常,将word count 作为本书的第一个实验是义不容辞的:
# Word count on 1st Chapter of the Book using PySpark
import re
# import add from operator module
from operator import add
# read input file
file_in = sc.textFile('/home/an/Documents/A00_Documents/Spark4Py
20150315')
# count lines
print('number of lines in file: %s' % file_in.count())
# add up lengths of each line
chars = file_in.map(lambda s: len(s)).reduce(add)
print('number of characters in file: %s' % chars)
# Get words from the input file
words =file_in.flatMap(lambda line: re.split('\W+', line.lower().
strip()))
# words of more than 3 characters
swords = words.filter(lambda x: len(x) > 3)
# set count 1 per word
words = words.map(lambda w: (w,1))
# reduce phase - sum count all the words
words = words.reduceByKey(add)在这个程序中, 首先从目录 /home/an/ Documents/A00_Documents/Spark4Py 20150315 中读取文件到 file_in. 然后计算文件的行数以及每行的字符数.
我们把文件拆分成单词并变成小写。 为了统计单词的目的, 我们选择多于三个字符的单词来避免象 the, and, for 这样的高频词. 一般地, 这些被认为是停词,应该被语言处理任务过滤掉 . 在该阶段,我们准备了 MapReduce 步骤,每个单词 map 为值1, 计算所有唯一单词的出现数量. 这是IPython Notebook中的代码描述. 最初的 10 cells是在数据集上的单词统计预处理 数据集在本地文件中提取.
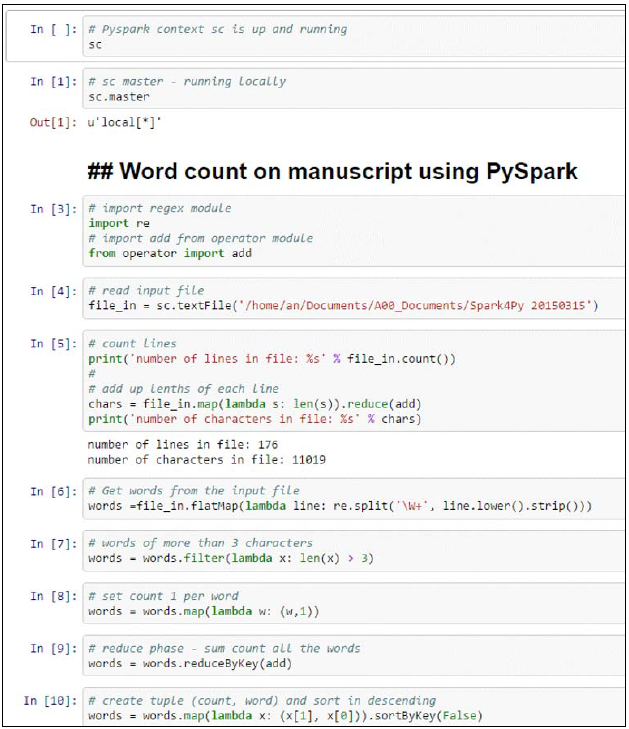
以(count, word)格式交换词频统计元组是为了把count作为元组的key 进行排序 :
# create tuple (count, word) and sort in descending
words = words.map(lambda x: (x[1], x[0])).sortByKey(False)
# take top 20 words by frequency
words.take(20)未来显示结果, 我们创建(count, word) 元组来以逆序显示词频出现最高的20个词:
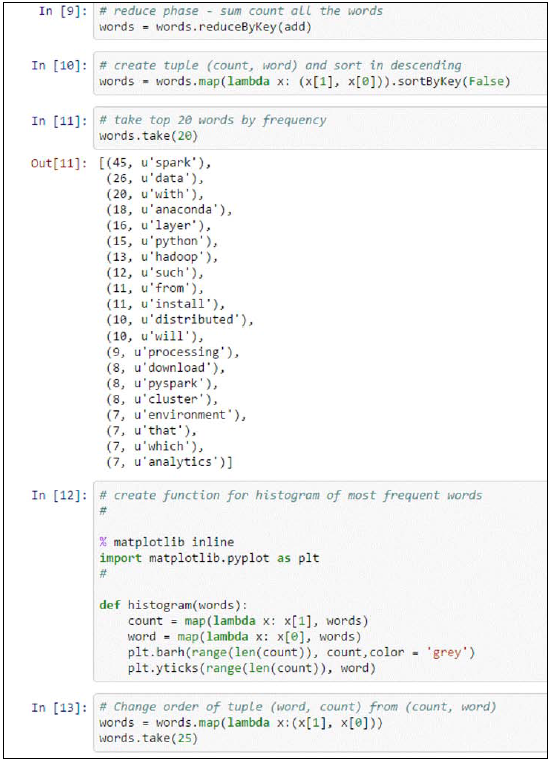
生成直方图:
# create function for histogram of most frequent words
% matplotlib inline
import matplotlib.pyplot as plt
#
def histogram(words):
count = map(lambda x: x[1], words)m
word = map(lambda x: x[0], words)
plt.barh(range(len(count)), count,color = 'grey')
plt.yticks(range(len(count)), word)
# Change order of tuple (word, count) from (count, word)
words = words.map(lambda x:(x[1], x[0]))
words.take(25)
# display histogram
histogram(words.take(25)) 我们可以看到以直方图形式画出的高频词,我们已经交换了初识元组 (count, word) 为 (word, count):
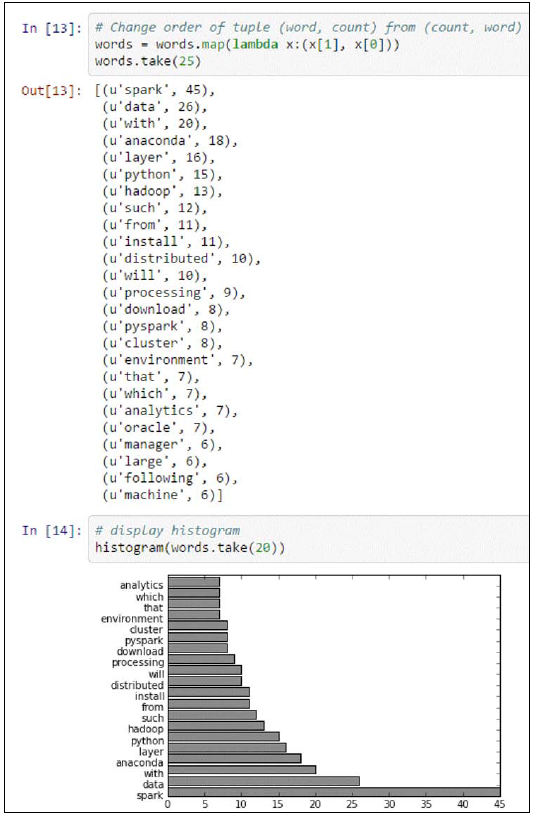
所以,我们也已经回顾了本章所有的高频词 Spark, Data 和 Anaconda.















 5924
5924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









