







ASF(Application Service Framework)基于SCA规范的框架第一期基本结束,整体上来说已经能够取得原想的第一步要求。第一期的总结和第二期的规划让我一度有些迷惘,因为作为框架设计来说,商业目标第一,客户需求第一,技术创新为后,现在要规划第二期,首先还是需要关注与业务组的需求,业务组的需求尚满足于第一期的框架成果,所以只能够在首架和老大的要求下规划第二期。正好中间参加了BEA的SOA年会,虽然没有很多实质性的解决方案学习,但是对我将来的工作有了一点灵感的激发,遂写了后面的第一期总结和第二期规划。
总体上来说有两大部分工作需要去做:
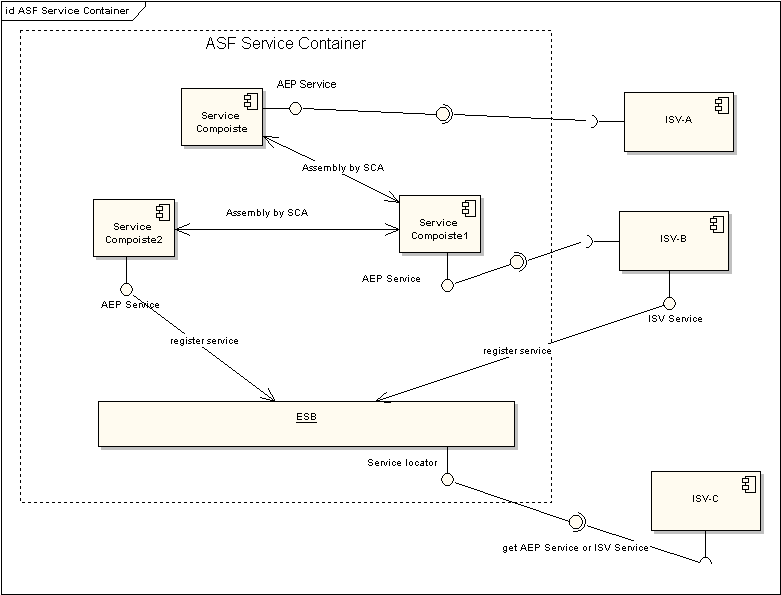
1.ISV的互联互通。SCA框架能够很好的构建一个服务容器(对业务模块内服务的封装和完成业务模块间服务的组装),让服务作为资源在容器互联互通,同时很便捷的将服务发布成为Web Service或者其他分布式服务实现(Hessian,RMI等)提供给外部ISV调用。但是作为一个服务平台,需要将集成在服务平台上的服务价值最大化,那么就需要将这些服务能够互联互通,这样才能够为以后服务定制打好最基本的基础,因此服务的互联互通就成为了重点需要做的工作了。下面的图就说明了基本的实现思路:
2.高性能易扩展的框架设计。这部分内容本来只是需要我去研究适合平台的Cache来提高系统的性能。由于早期的平台采用过多种的Cache机制来缓存一些重要信息,但是总是遇到一些问题,首先是采用了Jboss treeCache,这是一种分布式的Cache,大部分现有的开源的分布式Cache都采用了Jgroup来消息传播,以保证数据的一致性,但是Jgroup一直有个问题没有解决,就是Jgroup中有Master node和 salve node之分,当有新的service node需要加入的时候,需要Jgoup中的各个master去审批,当master失效的时候,就会导致其它的节点无法加入或者消息出现传播问题,其中也有参数配置Master的失效的策略,配置上去以后的却解决了大部分的问题,但是偶尔还是在集群重启后出现问题。(也可能还是我不是很了解需要配置的一些内容吧),再加上考虑到分布式的Cache效率上也有折扣,因此后来采用了兄弟公司的Cache实现,但是兄弟公司的Cache实现也有不少问题,包括可扩展性,单点问题,数据丢失,失效策略配置等,因此需要考虑使用更加适合的Cache。
随着大家对新新的Web2.0网站的关注,这类以用户为中心的网站对于性能要求十分高,因此正好参考了这些网站的架构设计,好好的学习和实践一下,其中Cache已经开始学习MemCached,同时了解了它的优点和缺点,后续需要做的就是根据当前平台的需求和场景,来订制使用策略和策略的实现。与此同时,这些网站的整体结构设计让我也产生了研究下去的兴趣,特别是在如何在用户数激升的时候,让框架可以扩展适应这种飞速增长,以前记得和自己部门的另外一个业务组也有过这样的交流,因为该业务组是和C2C业务相关,那么对于这方面的需求很大,讨论过关于DB的scale up或者 scale out,但是都发觉存在了很多问题,但是参考了这些网站的成长历程,很多问题就迎刃而解了。不过一句话,实践出真知,现在学到的只是形,真正要实施还有很多细节需要去考虑和思索。
Shards : 用碎片来Scale out
这个词还是在Flickr的框架结构设计中看到的,其实这个概念应该比较早出现了,在Hibernate 已经有了实现,同时MySql也已经有类似的实现机制。属于数据层扩展的实现方案,也就是过去常说的 Scale out的一种机制。
当用户和业务数据不断增长的情况下,网站的DB将会承受越来越大的压力,同时DB也会成为应用的瓶颈,导致网站应用响应速度变慢。有很多策略来缓解这样的情况,如果从数据库本身扩展策略来看,就有两种模式:Scale up和Scale out。所谓Scale up就是向上扩容,Scale out就是平面型的扩容。两种扩容的方式分别从两个维度来解决数据库压力,纵向的扩容就是将DB Server的配置提高,增加硬件配置,通过硬件速度提升来解决访问压力,横向扩容就是将应用的数据拆分,将原来集中存储的数据根据一定的规则分布到不同的物理数据库服务器上。很明显,前者实施代价较后者高,同时到达一定的压力以后,硬件可能也无法满足这类的升级。因此Scale out应该说是性价比和可长期扩展的有效手段,但是缺点就是在于策略的制定复杂以及维护成本要高于Scale up。Flickr网站通过Shards这种模式,利用众多的价格低廉数据库服务器横向分布信息,在每天处理亿级的事务情况下响应时间还是很快,同时在信息不断膨胀的情况下扩展的成本很低,扩展对于网站的影响基本没有。
Shards这个单词的含义是碎片,而在这边的含义指的是将应用的数据横向拆分,也就是说如果有几千万的用户信息,那么这些用户信息可以被分布在多个数据库服务器上,例如编号1到100000的用户为第一组分在服务器A上,100000到200000的用户在服务器B上,这种分组分布数据到不同的数据库服务器上,横向切分数据块就叫做Shards,当然这种切分的规则以及策略都是根据具体的业务场景不同而不同的,策略的好坏直接影响到扩展对应用产生的作用以及后续扩展对于应用产生影响的大小。
那么Shards能够带来哪些好处呢?在《An Unorthodox Approach to Database Design : The Coming of the Shard》一文中提到了这么四点:高可靠性(一台数据库服务器出现问题,其他依然能够正常使用)。更快的查询(数据量的减小可以极大的提高查询效率)。更多的写入带宽(因为数据分布在多台服务器上,网络带宽自然就增大了)。可以做更多的处理(数据库压力减小,自然对于应用服务器来说本身的响应时间能够减少,事务处理量就会增加)。那就我个人对于上述的一些优点来看,其实觉得有几点不能称之为优点了,首先高可靠性,如果一台数据库服务器失效,那么那台数据库服务器上的数据将会丢失,应用程序将会无法正常的返回结果,当然可以做备份,那么其实是否分散数据,都可以通过备份的数据库服务器来保证服务器正常,同时Shards可能需要更多的数据库服务器来保证应用的数据正常和完整。其他的几点优点都是有代价的,数据的物理隔离分布,如果需要对应用透明,那么就需要在DB或者持久化层做选择策略,同时选择策略的好坏也将直接影响应用的可靠性,性能以及可扩展性。
说说Shards如果要实施起来的几个问题,当然自己现在还没有去实施,所以这些问题只是在过去的Scale out 讨论方案中也提起过,同时经历了这段时间的接触也有一些新的想法。
关于数据的平衡问题。可以分成两部分来看,一部分是业务数据本身所存在的不平衡性,当采用比较简单的算法将业务数据分割shards到各个DB Server上的时候,可能根本无法去预料到如何这些看似平均分配的数据在日后增长的情况会如何,其实可能某些客户的数据量增长的相当快,某些增长的很慢,这样可能造成不同的DB Server的数据不平衡性,也导致了压力无法较为合理的均分,最后还可能导致某一台DB Server会要从新被拆分。解决这种情况在我看来没有什么万能的解决模式,只有根据不同的情况来做出策略选择和设计,但是有一点我能够确定的就是,不论采用什么方式,策略的配置必须灵活,也就是说,DB Server的配置修改必须能够比较方便,那么就算后期修改策略或者再次拆分庞大的DB,也不会对应用造成很大的影响,具体的策略配置设计看到过一些,比较灵活的就是设计策略配置的前置层。另一方面就是当业务不断增长的情况下,如何用新增机器来分担压力。最近看了一下Memcached的客户端的一点设计,它对于多个Memcached Client Connection可以配置权重,这样数据来的时候除了按照基本的负载均衡的策略以外还可以根据动态权重的调整来调整数据的分布。那其实在新增DB的时候如果将DB的权重设置为较高,那么自然可以优先分担数据压力。不过这些都是一些很浅的考虑,真正实施过程中需要用实践来考验设计方案,所以这里提到的任何观点都仅仅是学习理论的东西,还需要后面用实践来给出真正的解决方案和其中遇到的问题。
第二个难点就是关于如何将分散数据在查询中集中返回。业务数据在一个DB Server上面可以很容易的查询返回,但是现在分散在多台物理服务器上,那么就需要往多台DB上面去查询,最后再将数据汇集返回,这个过程对于性能一定是有影响的,同时排序问题也是会造成复杂度增加。那么这部分问题一方面要看Shards的实现对于性能和排序等问题的解决策略,另一方面也可以通过Cache来做部分的缓解(这也是Memcached往往需要作的一些事情,甚至都可以Cache某些sql和对应的结果)。
第三个难点就是在于如何将数据合理分配到Shards中,因为可能某些业务逻辑的Sql就需要按照规则分配到多个Shards的数据作关联,那么此时这种关联就会由原来的DB关联,变成了业务关联,那么这类问题往往就不是DB层和持久层能够做的。其实如果遇到这样的问题,往往就是要作冗余,也就是某一些数据在多个Shards都有,但是这势必造成了多服务器写入或者就是写入通知的问题,这么回过头来看,就变成了DB备份的特殊版了,效率不高。
暂时就想到了这些问题,当然这里也没有给出具体的解决方案,最多是一些比较浅的想法,其实这就是后面要作的事情,去实践,去做才能找到答案。对于DB扩展来说另一种Scale out是将业务表分离,业务表分离其实就是根据业务模块的关联性来划分Shards,它可以容易的解决业务数据分离带来的一些问题,但是自身又会出现其他的问题,包括业务表的划分合理性,全局性业务表的归属(冗余还是全局可获取)。其实说到底这些扩展在应用中往往是结合应用,而非单纯的简单使用某一种。同时根据业务的读写比例适当的采用DB的Master,Slave来缓解压力也是一种联合解决策略。
还是先学习概念,抛出问题,后面实践面对问题,解决问题。有这方面解决实践经验的朋友也可以多多提出一些想法和意见给我,其实技术需要分享,国外的开源如火如荼,国内大家除了忙着应付商业需求,有空的时候多一些分享,提高别人也能够提高自己。















 9340
9340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









