







当训练一个模型,它往往是有价值的实时跟踪和评估进展。在本教程中,您将学习如何使用TensorFlow的记录功能和监测API审核在分类器分类的神经网络进行训练的鸢尾花。本教程建立在tf.contrib.learn快速开发的代码,所以如果你还没有完成这个教程,你可能想探索它,特别是如果你正在寻找一个基本tf.contrib.learn介绍/复习.
解决这个问题的方法之一是分裂模型训练成多个适应调用的步骤数较小,以更准确地评估精度。不过,这并不建议做法,因为它大大减慢了模型训练。幸运的是,tf.contrib.learn提供另一种解决办法:一个监控API的设计来帮助你评估你的日志数据和模型在训练的过程中。在下面的章节中,您将学习如何在TensorFlow启用,设置一个validationmonitor做流评估和可视化你的度量采用tensorboard。.
Enabling Logging with TensorFlow
TensorFlow用五个不同级别的日志信息。为了升序的严重性,他们是调试DEBUG,信息INFO,警告WARN,错误ERROR和致命FATAL的。当你配置日志记录在任何级别,TensorFlow将输出对应于更高程度的严重性和所有级别的日志信息。例如,如果设置错误的日志记录级别,将得到包含错误和致命消息的日志输出,并且如果设置了调试级别,则将从所有五个级别获取日志消息。默认情况下,TensorFlow配置在日志记录级别的WARN,但当跟踪模型的训练,你会想要调整水平到INFO,这将提供额外的反馈如进程中的fit操作。
将下面的行添加到代码的开头(在导入之后):
tf.logging.set_verbosity(tf.logging.INFO)
INFO:tensorflow:loss = 1.18812, step = 1
INFO:tensorflow:loss = 0.210323, step = 101
INFO:tensorflow:loss = 0.109025, step = 201
Configuring a ValidationMonitor for Streaming Evaluation
记录训练损失的日志有助于了解你的模型是否收敛,但如果你想进一步了解在训练过程中发生了什么?tf.contrib.learn提供若干高级Monitor可以附加到你 fit 操作进一步跟踪指标和/或调试级别较低的tensorflow操作模型的训练过程中,包括:
| Monitor | Description |
|---|---|
CaptureVariable | Saves a specified variable's values into a collection at every n steps of training |
PrintTensor | Logs a specified tensor's values at every n steps of training |
SummarySaver | Saves tf.Summary protocol buffers for a given tensor using a tf.summary.FileWriter at everyn steps of training |
ValidationMonitor | Logs a specified set of evaluation metrics at every n steps of training, and, if desired, implements early stopping under certain conditions |
Evaluating Every N Steps
对于IRIS神经网络分类器,日志记录训练损失的同时,你也可能要同时评估测试数据,看看模型泛化能力如何。你可以通过与试验数据的配置validationmonitor(test_set.data和test_set.target),并设置评价频率every_n_steps。every_n_steps的默认值是100;在这里,集every_n_steps 50评估后每50步模型训练:
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor(
test_set.data,
test_set.target,
every_n_steps=50)validationmonitors依靠保存检查站执行评估业务的,所以你要修改的分类实例添加一个tf.contrib.learn.runconfig包括save_checkpoints_secs,指定多少秒应该从检查点保存在训练。因为Iris数据集很小,因此训练很快,就设置save_checkpoints_secs 1(保存一个检查站每二)确保有足够数量的检查:
classifier = tf.contrib.learn.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model",
config=tf.contrib.learn.RunConfig(save_checkpoints_secs=1))最后,为了添加上你的validation_monitor,更新 the fit call 让其包括一个 monitors 参数,它让一个列表中的所有monitors 运行在模型训练:
现在,当您重新运行代码时,您应该看到日志输出中的验证度量,例如:
INFO:tensorflow:Validation (step 50): loss = 1.71139, global_step = 0, accuracy = 0.266667
...
INFO:tensorflow:Validation (step 300): loss = 0.0714158, global_step = 268, accuracy = 0.966667
...
INFO:tensorflow:Validation (step 1750): loss = 0.0574449, global_step = 1729, accuracy = 0.966667Customizing the Evaluation Metrics with MetricSpec
默认情况下,如果没有指定的评价指标,validationmonitor将日志记录损失和准确性,但您可以自定义指标,将每50个步骤运行logging一次。为了指定你想运行在每次评估过程中,你可以添加一个metrics 参数到validationmonitor构造函数中。metrics 需要字典的键/值对,其中每一个key是你要log的度量的名称,对应的value是一个MetricSpec对象。metricspec构造函数接受四个参数:
metric_fn.计算并返回度量值的函数。这可以是一个预定义的函数在tf.contrib.metrics模块可用,如tf.contrib.metrics.streaming_precision或tf.contrib.metrics.streaming_recall.
或者,您可以定义自己的自定义度量函数,它必须将预测和标签张量作为参数(也可以可选地提供权重参数)。函数必须以两种格式中的一种返回度量值:
A single tensor
A pair of ops (value_op, update_op), where value_op returns the metric value and update_opperforms a corresponding operation to update internal model state.
prediction_key.包含模型预测的张量的关键。这种说法可以省略,如果模型返回一个张量或与一个单一的入口。一类dnnclassifier模型,预测将在一个关键tf.contrib.learn.predictionkey.classes张量回来。
label_key含模型返回的标签的张量的关键,通过模型的input_fn指定。与prediction_key,这种说法可以省略,如果input_fn返回一个张量或与一个单一的入口。在虹膜的例子在本教程中,将dnnclassifier没有input_fn(X,Y数据直接传递到合适的),所以没有必要提供一个label_key。
weights_key.可选。张量的关键(由input_fn返回)含权重输入的metric_fn。
下面的代码创建一个validation_metrics字典定义日志在模型评估三个指标:
"accuracy", usingtf.contrib.metrics.streaming_accuracyas themetric_fn"precision", usingtf.contrib.metrics.streaming_precisionas themetric_fn"recall", usingtf.contrib.metrics.streaming_recallas themetric_fn
validation_metrics = {
"accuracy":
tf.contrib.learn.metric_spec.MetricSpec(
metric_fn=tf.contrib.metrics.streaming_accuracy,
prediction_key=tf.contrib.learn.prediction_key.PredictionKey.
CLASSES),
"precision":
tf.contrib.learn.metric_spec.MetricSpec(
metric_fn=tf.contrib.metrics.streaming_precision,
prediction_key=tf.contrib.learn.prediction_key.PredictionKey.
CLASSES),
"recall":
tf.contrib.learn.metric_spec.MetricSpec(
metric_fn=tf.contrib.metrics.streaming_recall,
prediction_key=tf.contrib.learn.prediction_key.PredictionKey.
CLASSES)
}重新运行代码,您应该看到精度和召回包含在您的日志输出,例如:
INFO:tensorflow:Validation (step 50): recall = 0.0, loss = 1.20626, global_step = 1, precision = 0.0, accuracy = 0.266667
...
INFO:tensorflow:Validation (step 600): recall = 1.0, loss = 0.0530696, global_step = 571, precision = 1.0, accuracy = 0.966667
...
INFO:tensorflow:Validation (step 1500): recall = 1.0, loss = 0.0617403, global_step = 1452, precision = 1.0, accuracy = 0.966667Early Stopping with ValidationMonitor
请注意,在上述日志输出,通过步骤600,该模型已经实现了精度和召回率为1。这就提出了一个问题,模型训练是否可以受益于提前停止。除了测井评价指标,validationmonitors易于实现early stopping在达到指定条件时,通过三个参数:| Param | Description |
|---|---|
early_stopping_metric | Metric that triggers early stopping (e.g., loss or accuracy) under conditions specified in early_stopping_rounds andearly_stopping_metric_minimize. Default is "loss". |
early_stopping_metric_minimize | True if desired model behavior is to minimize the value ofearly_stopping_metric; False if desired model behavior is to maximize the value of early_stopping_metric. Default is True. |
early_stopping_rounds | Sets a number of steps during which if the early_stopping_metric does not decrease (if early_stopping_metric_minimize is True) or increase (ifearly_stopping_metric_minimize is False), training will be stopped. Default is None, which means early stopping will never occur. |
validation_monitor = tf.contrib.learn.monitors.ValidationMonitor(
test_set.data,
test_set.target,
every_n_steps=50,
metrics=validation_metrics,
early_stopping_metric="loss",
early_stopping_metric_minimize=True,
early_stopping_rounds=200)
...
INFO:tensorflow:Validation (step 1150): recall = 1.0, loss = 0.056436, global_step = 1119, precision = 1.0, accuracy = 0.966667
INFO:tensorflow:Stopping. Best step: 800 with loss = 0.048313818872.
Visualizing Log Data with TensorBoard
通过validationmonitor阅读日志提供了在训练模型的性能数据很多,但它也可能有助于看到这个数据,以获得进一步的洞察趋势,例如可视化,如何准确率在步数的变化。你可以使用TensorBoard(一个单独的程序打包与TensorFlow)设置为logdir命令行参数到保存你的模型的训练数据目录图表这样(这里,/tmp/ iris_model)。在命令行上运行以下命令:
$ tensorboard --logdir=/tmp/iris_model/
Starting TensorBoard 39 on port 6006
然后导航到HTTP:/ / 0.0.0.0:< port_number >在您的浏览器,在< port_number >在命令行输出指定的端口(这里,6006)。
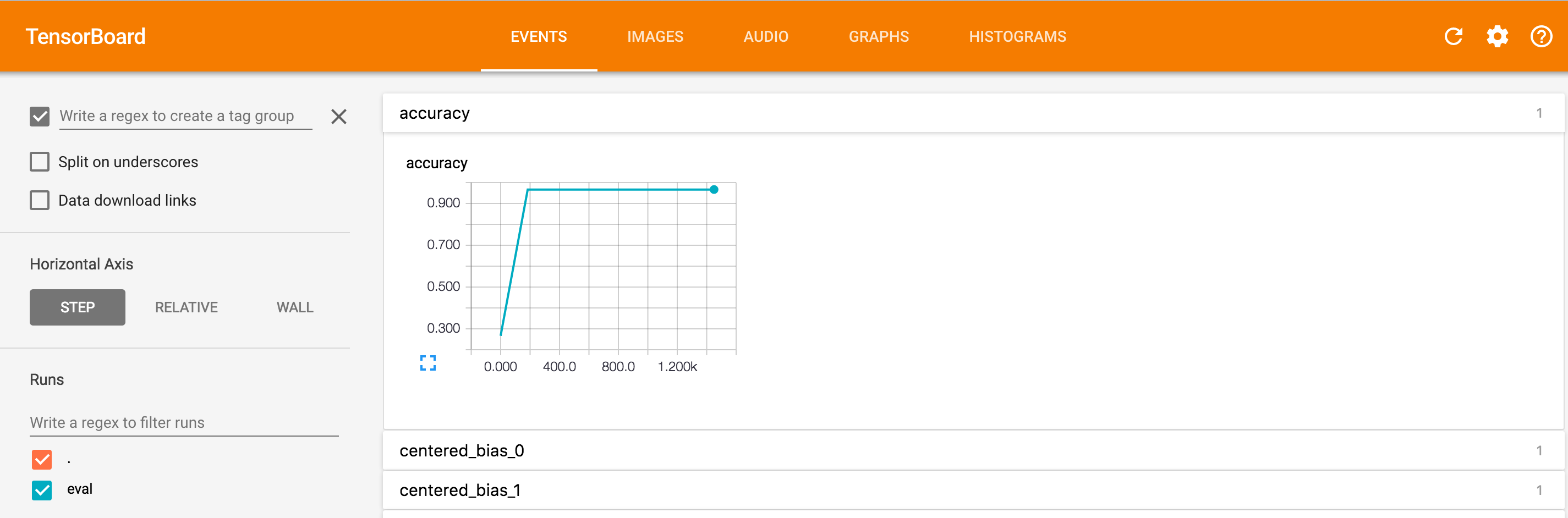
如果你点击精度字段,你会看到一个像下面的图像,它显示了精确的步骤计数:















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









