







作者
Varun Ramakrishna, Daniel Munoz, Martial Hebert,
J. Andrew Bagnell, and Yaser Sheikh
The Robotics Institute, Carnegie Mellon University
本文是CVPR2016 Convolution Pose Machine所follow的论文。
一、论文所解决的问题
本文所用的方法还是图模型的方法采用了一种模拟图模型的推断的机制(消息传递机制的方法),本文说起来挺玄乎的,其实就是多个分层次的多类分类器的级联。
来实现对于关节的位置的预测,本文宣称能够解决遮挡问题。
(1)对关节建模的传统方法
普通的图模型一般都是限制为树模型或者星状模型(把关节建模成树状和星状) ,不能很好地捕获身体部件之间的关系,而如果加入复杂的关系,则会导致图模型不可解。比如这些简单的图模型会在遮挡的时候导致双重计数。(何为双重计数:图像的某一个区域可以解释成两个或者若干个关节,特别是两个关节重叠的时候)。
所以在传统的图模型中(把关节建模成树状和星状)为了可解性,会被算法本身牵着走,而不是问题的复杂度牵着走
(2)本文的创新
本文就是为了打破图模型在可解性和问题的复杂度之间的权衡,从而发明了姿态机框架(该方法源自于scene parsing follow的论文
Munoz, D., Bagnell, J.A., Hebert, M.: Stacked hierarchical labeling. In: ECCV.
(2010) 和
Ross, S., Munoz, D., Hebert, M., Bagnell, J.A.: Learning message-passing inference
machines for structured prediction. In: CVPR. (2011) )
Pose Machine, is a sequential prediction algorithm that
emulates the mechanics of message passing to predict a confidence for each variable (part), iteratively improving its estimates in each stage.
总而言之:本文能够解决遮挡问题,为什么能解决,因为作者是用了另外一种方法进行图模型的inference,通过模拟图模型中的消息推断机制,作者称为推断机 (inference machine),速度快,因此可以包含更多的身体部件之间的关系,可以有效地对遮挡的关节进行建模
二、论文的解决方案
(1)整体架构一览
问题可以看成结构化输出的预测问题,所谓结构化输出就是输出的是关节的位置类标Y_i=(x,y),是一种结构化的类标,要预测Y={Y_1,Y_2,...,Y_P},其中P是人关节的个数。
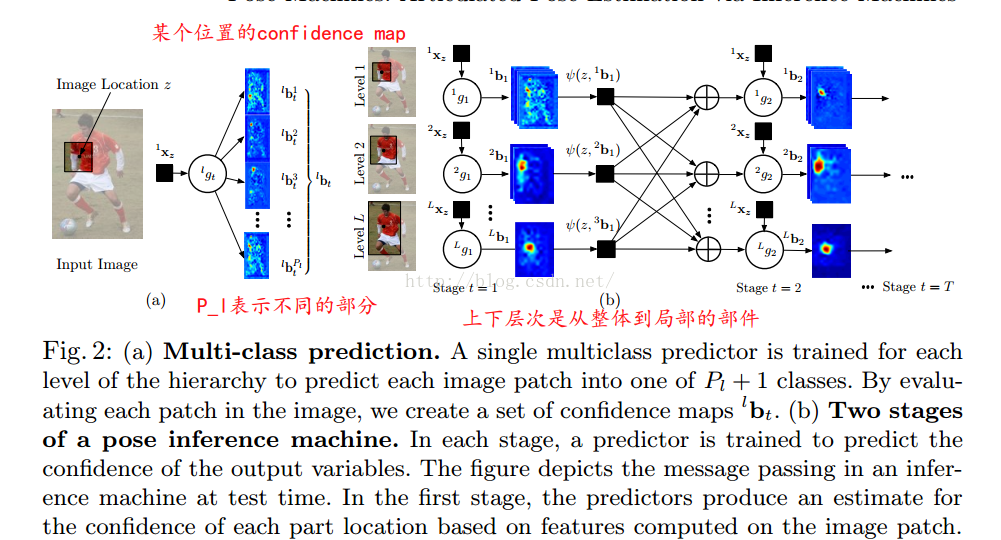
本文使用多阶段的多类分类器来预测关节的位置,通过首先用多类分类器的级联实现关节位置的预测。并且分类器从最上层往下预测的关节的范围是不一样的,最上面的分类器预测所有的关节,最下面的分类器预测单个关节。然后通过全连接将这一stage的预测结果作为下一stage的输入。
整体是,划分成多个层次,最低层次表示某个部件,而越往上表达的就越多,比如最顶层表示整个人。然偶在图像中每层都用(a)中的多类分类来进行预测,预测得到置信度map,然后将置信度map作为下一阶段的输入。
作者提到了两种处理这个置信度map的方法,处理完毕之后才能作为下一阶段的输入
1)Context Patch Features

2)Context Offset Features
使用nms,非最大抑制来得到经过排序的K个peaks,然后计算极坐标系下的图像patch的位置z到K个peak的offset,最后该offset作为特征。
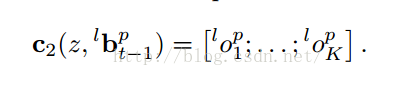
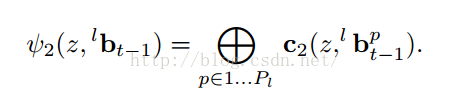
整个算法如下:

此外为了防止过拟合,使用了
Stacked training aims to prevent predictors trained on the output of the first
stage from being trained on same training data.
三、其他未能考虑的问题
多人骨架的提取能够解决吗?如果一幅图片中有多个人该算法是否有效
四、有什么收获
这篇文章的意思是很容易明白的,就是多个多类分类器,级联,然后分类器还划分层次,主要是因为我之前阅读的一篇文章
Poselet
conditioned pictorial structures说了更高层次的表达有利于姿态的估计。所以作者给每个stage设计多个层次的分类器,然后再将分类器的输出作为输入全连接到下一个stage上去。
本文解决了遮挡问题,这一点也算是提供了一种解决遮挡的思路。
此外也验证了,local image evidence is weak。
五、实验
(1)数据集
LEEDs Sport 数据集和FLIC数据集
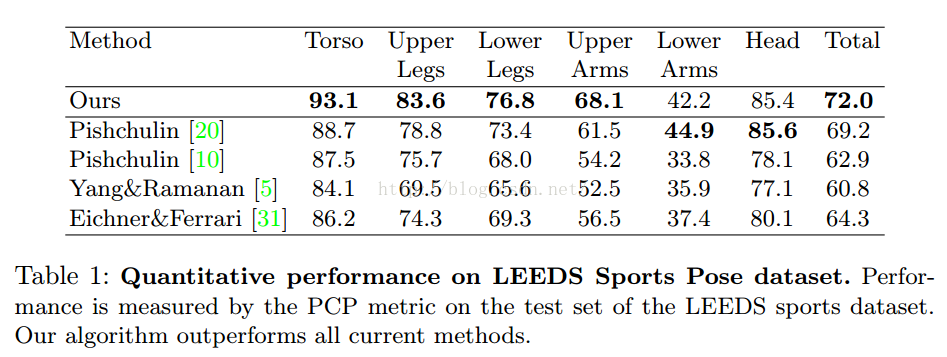
PCP是正确关节位置的百分比
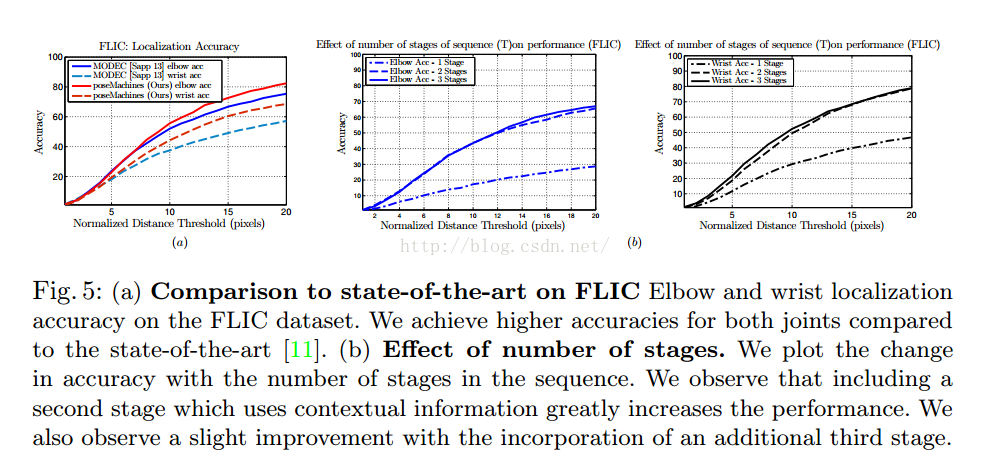
这个图的横坐标是是与正确位置偏移的像素个数,纵坐标是精确度,发现5个像素的值精确度还是很低,在FLIC这个数据集,这个数据集也确实很难,也就是我之前做的那个数据集。
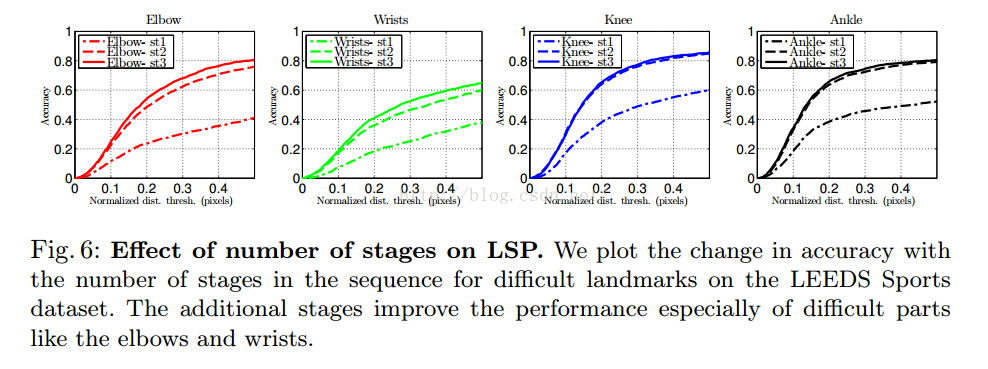
最后还对比了stage数目对结果的影响,发现越多,效果是越好的,但是也有上限。3个stage基本就差不多了
(2)代码
没找到














 2081
2081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









