








导读:人体姿态估计中常用的模式,就是用堆叠的漏斗模型去实现精密的关键点预测,并将上一阶段的预测结果用于当前阶段的先验知识,并以强制中间层监督的方式来解决梯度消失的问题。这一系列经典的操作,根源与这篇文章,即卷积姿态学习机,CPM。
摘要
Pose机为学习丰富的隐式空间模型提供了一个序列预测模型。这篇文章展示了一个姿态估计的系统设计,如何将卷积网络整合到pose机中以学习图像特征和图像相关的空间模型。文章的贡献在于,在结构化的预测任务中如关节姿态估计,隐式建模变量之间的长距离依赖关系。我们通过设计一个由卷积网络组成的顺序架构来实现,该网络直接在上一阶段的信念图上运行,对身体部位的位置产生了不断精细地估计,而不需要显式的图形模型式的推导。我们的方法通过提供一个强制中间监督的自然学习目标函数来解决训练过程中的梯度消失的典型问题,因此补充反向传播的梯度和调节学习过程。我们在标准的数据集如MPII,LSP和FLIC数据集上验证了领先的性能。
介绍
我们介绍了卷积姿态机用于关节点姿态识别。CPM继承了pose机架构的优点,即图像和多局部线索之间长距离依赖的隐式建模,学习与推荐的紧密集成,模块化的循序设计,以及将他们与卷积网络提供的优点结合起来:从数据中学习用于图像和空间上下文的特征表征的能力;一个可微的架构,允许反向传播用于全局联合训练;以及有效处理大数据集的能力。
CPM包含了一个序列的卷积网络,它重复产生每一个局部位置的2D信念图。在CPM的每一个阶段,由上一阶段产生的图像特征与信念图,作为当前阶段的输入。信念图为后续阶段的每个部位的空间不确定性提供了一个表达性的非参数编码,允许CPM去学习丰富的图像相关的部位之间关系的空间建模。取代使用图形建模或者专门的后续处理显式地解析信念图,我们学习卷积网络能够之间在中间层的信念图上操作,并学习隐式的部位之间关系的空间模型。整体提出的多阶段架构是完全可微的,因此能够使用反向传播以端到端的方式来训练。

A Convolutional Pose Machine consists of a sequence of predictors trained to make dense predictions at each image location. Here we show the increasingly refined estimates for the location of the right elbow in each stage of the sequence. (a) Predicting from local evidence often causes confusion. (b) Multi-part context helps resolve ambiguity. © Additional iterations help converge to a certain solution.
一个CPM包含有序列组成的预测器,被训练成用于每个图像位置的密集预测。这里展示序列中每个阶段右手腕位置不断精细的预测。(a)从局部特征预测经常引起混淆;(b)多部位上下文有助于解决歧义;(c)额外的训练有助于收敛到一个确定的位置。
在CPM的某一特定阶段,部位信念的空间上下文为后续阶段提供了强有力的线索。因此,CPM的每一个阶段产生了针对每个部位位置的不断精细化估计的信念图,上图所示。为了获取部位之间长距离的交互,我们的序列预测网络的每一个阶段,网络的设计都出于在图像和信念图上实现更大感受野的目标。我们发现,通过实验,信念图上的更大感受野对于长距离的空间建模至关重要,并且有助于提升精度。
CPM的多卷积网络组成导致了一个具有多层网络的整体结构,在训练过程中会存在梯度弥散的风险。这个问题出现主要由于反向的梯度在多层网络中传播会降低强度。虽然最近的工作展示了中间层监督深度网络有助于学习,他们大多数局限于分类问题。在这篇文章中,展示了对于结构化的预测问题如姿态估计,CPM如何自然地提出一个系统框架,它通过网络定期地执行中间层监督来补充梯度和引导网络生成越来越精确的信念图。我们同样讨论了诸如此类序列预测问题的不同训练方法。
论文的主要贡献在于:通过一个序列的卷积架构来学习隐式的空间模型;一个系统的方法去设计和训练如此的架构去学习图像特征和图像相关的空间模型用于结构化的预测任务,同时不需要任何的图形模型类的推测。我们在标准的数据集合如MPII,LSP和FLIC等取得了领先的结果。
方法
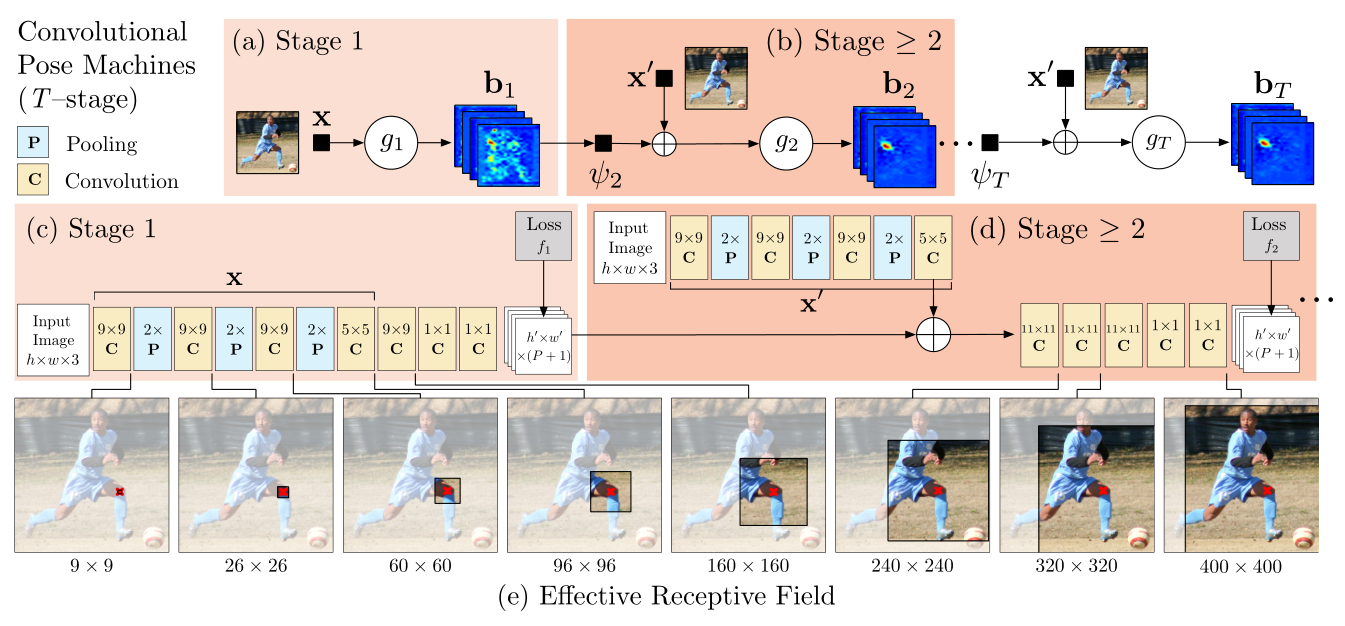
Architecture and receptive fields of CPMs. We show a convolutional architecture and receptive fields across layers for a CPM with any T stages. The pose machine [29] is shown in insets (a) and (b), and the corresponding convolutional networks are shown in insets © and (d). Insets (a) and © show the architecture that operates only on image evidence in the first stage. Insets (b) and (d) shows the architecture for subsequent stages, which operate both on image evidence as well as belief maps from preceding stages. The architectures in (b) and (d) are repeated for all subsequent stages (2 to T ). The network is locally supervised after each stage using an intermediate loss layer that prevents vanishing gradients during training. Below in inset (e) we show the effective receptive field on an image (centered at left knee) of the architecture, where the large receptive field enables the model to capture long-range spatial dependencies such as those between head and knees. (Best viewed in color.)
CPM的架构和视觉感受野。我们显示了一个卷积架构和在任一阶段中CPM的视觉感受野。pose机如插图(a)和(b)所示,响应的卷积网络显示在插图© 和(d)中。插图(a)和(c)显示第一阶段仅在图像证据上的卷积操作。插图(b)和(d)显示了后续阶段的架构,它在图像和上一阶段的信念图上操作。网络在每个阶段之后都使用中间损失层进行本地监督,以防止训练期间的梯度消失。插图(e)展示了架构中一幅图像(以左膝盖为中心)的有效视觉感受野,其中大视觉感受野使得模型能够在长距离的空间依赖性上建模,例如头与膝盖等。
总结
提示:
卷积姿态机器提供了端到端的架构用于解决在计算机视觉中结构化的预测问题,而不需要图形模型分割的推理。文章展示了一个序列架构由卷积网络组成,能够隐式地学习用于姿态的空间模型,通过在阶段中传达不断精确的信念图。计算机视觉的多个领域中,如语义标签,单图像深度估计和目标检测等,出现变量之间空间依赖性,将涉及把我们的工作扩展到这些问题中。但该模型对于密集的人群会出现失败的例子,以端到端的模型来处理多人场景是一个有挑战的问题,也是未来工作的有趣途径。
















 979
979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











