







机器学习方法主要分为有监督学习(supervised learning)和无监督学习(unsupervised learning)。下面来用例子来简单介绍下。
1.监督学习
1.1 地价预测问题
假如我是一位房产商。打算购买某城市的一处20亩的土地来造房子,当然我希望用最低的价格来购买啦,这样才能赚到最多嘛。可我并不了解这个城市的地价。我先收集这个周边地区,近3个月的地产成交数据,数据的内容是土地面积和对应的价格(假如只考虑面积这一个变量)。如下表:1所示,根据这些数据我想预估出这套房产的合理价格范围,这样才能心中有数好下手。
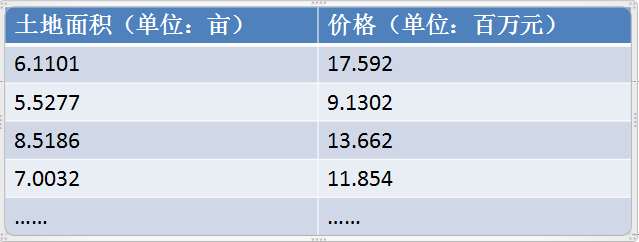
表1:地价与面积关系表
根据表格内容,我制作一张数据图1。
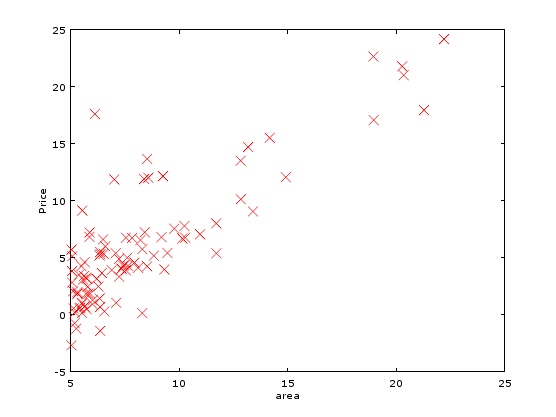
图1:地价与面积关系图
看到这图之后,我心中窃喜啊,这里的地价和面积成正比,于是我通过这些数据集,计算(训练)出一条直线(线性方程)。如下图2。那么这条线就能大致表示这个地区的房价与面积的关系了。

图2:训练后的关系图
那么我要购买的那套20亩的土地要多少钱呢?看下图3,我带入上面训练出来的线性方程,求得地价。

图3:地价结果
很明显,我大概要花19百万,也就是1.9千万。那我就会尽力把价格砍到1.9千万一下,哈哈。
1.2 肿瘤诊断问题
假如我是一名肿瘤科外科医生(喝喝,我是有很多身份的)。有一位病人,已经检测出肿瘤的大小(假如只考虑大小这一个变量),现在在没有得到化验结果前,让我预估下是恶性还是良性?我打开电脑里记录的肿瘤大小和肿瘤性状对比表2。
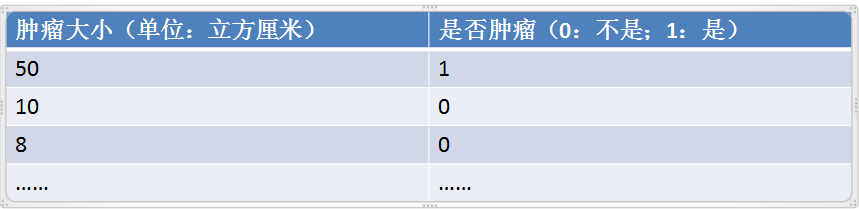
表2:对比表
然后我吧表中的内容绘制成图4.
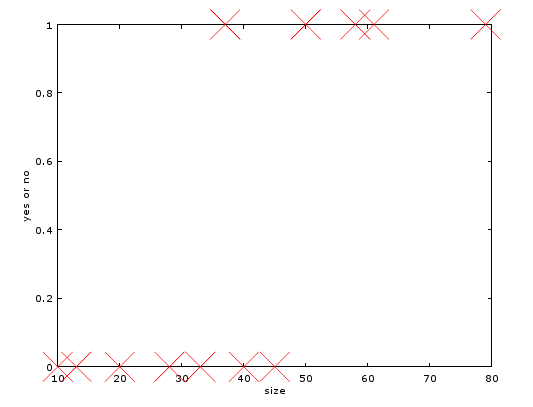
图4:对比图
再将患者的大小做对比,如下图五。其中绿色的标记是患者的肿瘤大小。
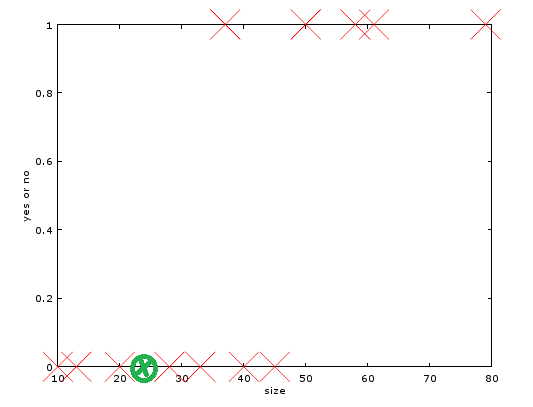
图5:患者结果图
通过图中的对比,我告诉患者,别担心,是良性。结果化验结果真是良性。看,我是不是神医。
总结:这2个例子都是通过已有数据内容进行分析,得到一个规律,然后预算出结果。例1是一种回归问题,例2是分类问题,属于监督学习。
2.无监督学习
2.1 超市保健品问题
假如我是某连锁超市的一位营销总监(喝喝,别在意,这是我的另一个身份)。最近的旗下有两个超市A和B,在保健品销售方面业绩差距很大,A比B好很多。我想要知道其中的原因,从而改善业绩差的B超市,可是要考虑的因素(参数)太多了,如销售人员,购买者情况。于是我把销售人员的工龄作为判断其水平的标志,工龄越久的销售人员我认为其销售水平高,反之销售水平低。购买者情况我用年龄来衡量其购买保健品的能力。年龄越大的,购买保健品的能力越大,反之,年轻人当然买的少啦。
我让市场部把之后3个月A,B超市购买这个产品的情况记录下来(记录销售工龄和购买者年龄)。3个月后市场部给了我一张表3。
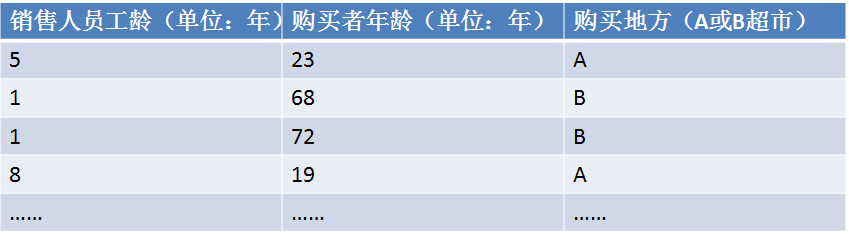
表3:购买情况表
接下来我把购买者年龄作为X轴,销售年龄作为Y轴,画成图6所示的二维图,用圈圈表示交叉点。其中红色表示A超市卖出的,绿色表示B超市卖出的。
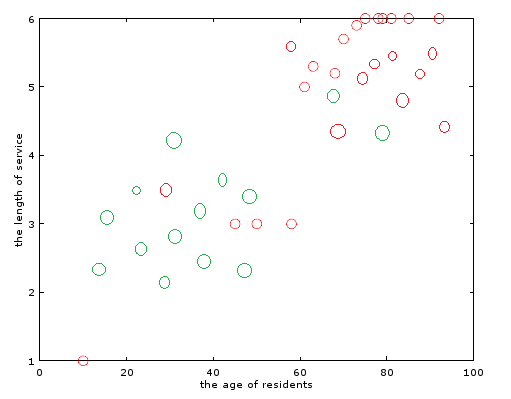
图6:对应二位图
看着这个我把他们分成2类,如下图7.

图7:分类后的图
看着这图,我惊奇的发现,在A超市购买的人群主要是年龄大的,而且销售工龄也比较长。所以能很好的卖出该保健品。而B超市购买的人群,普遍年龄小些,销售也都是新手为主。仔细一分析才知道。原来是B超市开在新开发区,都是上班族年轻人。A超市开在老城区,而且开业时间远比B要就,所以员工工龄也普遍大些。
通过分析,最后我决定,减少B超市的保健品货架,添加更多的年轻人消费品的货架。
总结:这个例子展现的就是聚类方法,属于无监督学习的一种。我手上只有一组数据,也不知道能得到什么结果,只能通过分析发现,这组数据间的规律。
3.对比
下面对监督学习和无监督学习做具体比较。
监督学习:目标是学习从输入到输出的映射关系,其中输出的正确值已经由指导者提供。
无监督学习:学习中没有指导者给出输出的正确值,只有输入数据,目标就是发现输入数据中的规律。
XianMing















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









