









B树原理及其分析
在大规模数据存储方面,大量数据存储在外存磁盘中,而在外存磁盘中读取/写入块(block)中某数据时,首先需要定位到磁盘中的某块,如何有效地查找磁盘中的数据,需要一种合理高效的外存数据结构,就是下面所要重点阐述的B-tree结构,以及相关的变种结构:B+-tree结构和B*-tree结构。
一 B-树
B-是不是二叉树,而是一种多路搜索树,所有节点的孩子节点树最大值称为B-树的阶m,一般m>2,一般m阶的B-树要么空树要么满足以下:
1 每个节点至多m个孩子;
2 根节点孩子数目[2,m],除根节点外非叶子节点的孩子树[m/2,m];
3 每个节点的结构:
| n | p0 | k1 | p1 | k2 | p2 | ...... | kn | pn |
4 每个节点存放[upper(m/2-1),m-1]个关键子字
5 非叶子节点的关键字个数=指向孩子的指针个数-1;
6 所有叶子节点同一层,故B-树是所有结点平衡因子均等于0的多路查找树。
例如m=3:
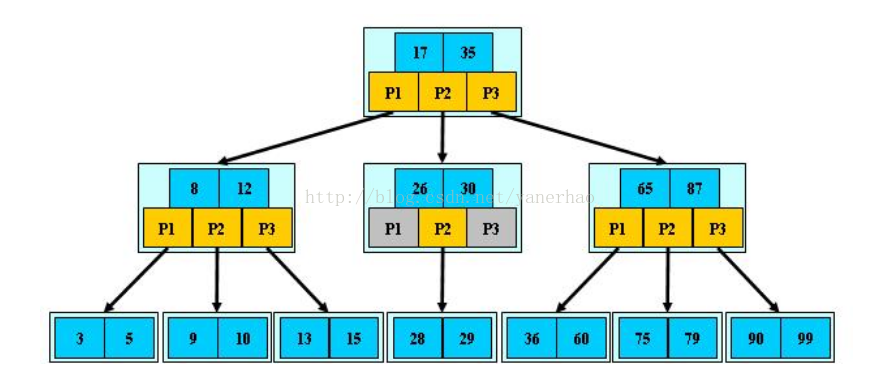
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为:
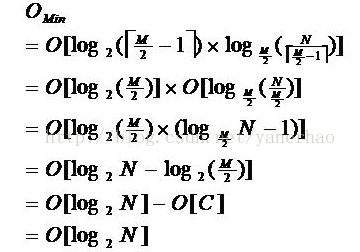
其中M为非叶子结点最多的子树个数,N为关键字总数。可以看到B-树性能总是与二分查找相似,且与M无关,无需考虑平衡问题。
定义每个节点左含关键字个数[min,max]
B-树的查找:
B-树的查找类似BST的查找,但不同的是在查找路径不是二路而是多路。而且每个记录(节点)内的关键字序列是有序的,故可以顺序查找:
若k==key[i],查找成功
若k<key[1],则沿着指针ptr[0]所指子树继续查找
若key[i]<k<key[i+1],则沿着ptr[i]所指子树继续查找
若k>key[n],沿着ptr[n]所指子树路径继续查找
B-树的插入:
插入分为两部:
1 利用B-树算法先找到该关键字插入的位置(B-树插入的节点一定是叶子)
2 判断该节点是否还有位置,即判断该结点关键字数目n<m-1?
2.1 若小于,则直接把k插入到合适位置(插入后保持有序就行)
2.2 若n==m-1,则需要进行分裂:把原节点上关键字和k按照升序排序后,从中间位置把关键字分成两份,左部分所含关键字放在旧节点,右部分关键字放在新节点,中间位置的关键字连同新节点的存储位置插入到父节点,若父节点也超过m-1则继续分裂继续上插,直到根节点为止。
B-树的删除:
B-树的删除类似B-树的插入,涉及合并问题:
1 利用B-树查栈算法找出关键字所在的节点;
2 删除k存在两种情况,一种是在叶子节点;一种在非叶子节点
3 在非叶子节点删除:
假设要删除的关键字key[i](1<=i<=n),在删除该关键字后,以该节点ptr[i]所指子树的最小关键字keymin来代替被删关键字(ptr[i]所指子树的最小关键字一定在叶子上),然后再以ptr[i]所指节点为根节点进行查找并删除keymin,这样就把删除节点在非叶子节点上转换为删除节点在叶子节点上问题
4 在叶子节点删除:
4.1 若被删关键字所在节点的关键字个数大于Min,直接删除即可;
4.2 若被删关键字所在节点的关键字个数等于Min,说明删除后不能满足B-树定义,此时若左或者右兄弟关键字个数大于Min,则把该结点左或者右兄弟的最大或者最小关键字上移至父节点,同时把父节点关键字中大于或者小于上移的关键字的关键字下移到要删除的关键字的节点中;
4.3 若被删关键字所在节点的关键字个数等于Min并且左右兄弟也是如此,这时需要把要删除的关键字的节点与左或者右节点以及父节点中分割两者的关键字合并成一个新节点,如果这样使得父节点关键字个数小于Min,则继续对双亲节点类似操作,直到根节点。
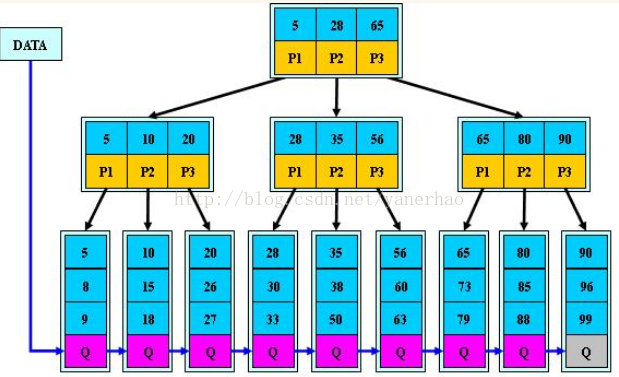
二 B+树
B+树是B-树的变体,也是一种多路搜索树。其与B-树的不同:
1 非叶子节点上子树指针与关键字个数一致;
2 所有叶子节点增加了链指针
3 所有关键字都在叶子上(而非B-树也在非叶子上)
其特点是:非叶子节点相当于叶子节点的索引,叶子节点相当于存储数据的数据层。一般应用于RDBMS数据库的索引。
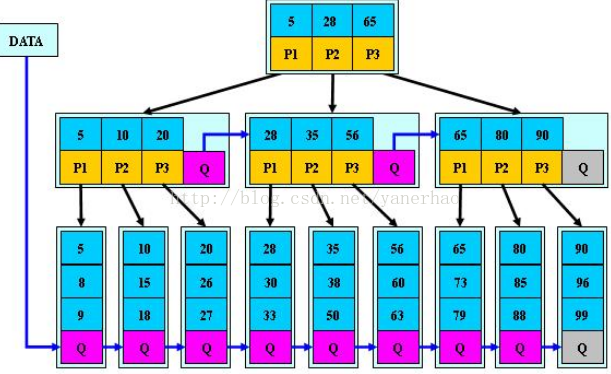
三 B*树
又是B+树的变体,在B+树基础上增加了非叶子节点间的兄弟指针。














 5808
5808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









