




 Mean-Shift算法是一种非参数化的多模型分割方法,通过分析图像的特征空间和聚类达到分割目的。它直接估计特征空间概率密度函数的局部极大值,以确定密度模式并进行聚类。本文介绍其在图像平滑和分割的应用原理。
Mean-Shift算法是一种非参数化的多模型分割方法,通过分析图像的特征空间和聚类达到分割目的。它直接估计特征空间概率密度函数的局部极大值,以确定密度模式并进行聚类。本文介绍其在图像平滑和分割的应用原理。
Mean shift主要用在图像平滑和图像分割(那个跟踪我现在还不清楚),先介绍一下平滑的原理:
输入是一个5维的空间,2维的(x,y)地理坐标,3维的(L,u,v)的颜色空间坐标,当然你原理也可以改写成rgb色彩空间或者是纹理特征空间。
先介绍一下核函数,有uniform的,也有高斯的核函数,不管是哪个的,其基本思想如下:简单的平滑算法用一个模板平均一下,对所有的像素,利用周围的像素平均一下就完事了,这个mean shift的是基于概率密度分布来的,而且是一种无参的取样。有参的取样就是假设所有的样本服从一个有参数的概率分布函数,比如说泊松分布,正态分布等等,高中生都知道概率公式里面是有参数的,在说一下特征空间是一个5维的空间,距离用欧几里德空间就可以了,至少代码里就是这样实现的,而本文的无参取样是这样的:在特征空间里有3维的窗口(想象一下2维空间的窗口),对于一个特征空间的点,对应一个5维的向量,可以计算该点的一个密度函数,如果是有参的直接带入该点的坐标就可以求出概率密度了,基于窗函数的思想就是考虑它邻近窗口里的点对它的贡献, 它假设密度会往密集一点的地方转移,算出移动之后的一个5维坐标,该坐标并会稳定,迭代了几次之后,稳定的地方是modes。这样每一个像素点都对应一个这么一个modes,用该点的后3维的值就是平滑的结果了,当然在算每个点的时候,有些地方可能重复计算了,有兴趣的化你可以参考一下源代码,确实是可以优化的。总结一下mean shift的平滑原理就是在特征空间中向密度更高的地方shift(转移)。
其次是怎么利用mean shift分割图像.先对图像进行平滑,第2步利用平滑结果建立区域邻接矩阵或者区域邻接链表,就是在特征空间比较近的二间在2维的图像平面也比较接近的像素算成一个区域,这样就对应一个区域的邻接链表,记录每个像素点的label值。当然代码中有一个传递凸胞的计算,合并2个表面张力很接近的相邻区域,这个我还没想怎么明白,希望比较清楚的朋友讲一讲。最后还有一个合并面积较小的区域的操作,一个区域不是对应一个modes值嘛,在待合并的较小的那个区域中,寻找所有的邻接区域,找到距离最小的那个区域,合并到那个区域就ok了。
Mean-Shift分割原理
Mean-Shift是一种非参数化的多模型分割方法,它的基本计算模块采用的是传统的模式识别程序,即通过分析图像的特征空间和聚类的方法来达到分割的目的。它是通过直接估计特征空间概率密度函数的局部极大值来获得未知类别的密度模式,并确定这个模式的位置,然后使之聚类到和这个模式有关的类别当中。下面对Mean-Shift算法进行简介。
设S是n维空间X中的一个有限集合,K表示X空间中λ球体的一个特征函数,则其表达式为:
![]()
其中,x∈X,那么在向量x点处的样本均值为:
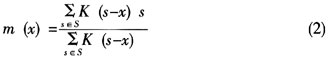
Fukunaga和Hostetle等人在其自己的论文中把m(x)-x的差叫做Mean-Shift。Mean-Shift算法实际上就是数据点到样本均值的重复移动,而且在算法的每一次迭代过程中,对于所有的s∈S,s←m (s)都是同时的。同时,模糊聚类算法还包括最大墒聚类算法以及常用的k均值聚类算法,它们都是Mean-Shift算法的一个有限的特例。Mean-Shift算法作为一种聚类分析方法,由于其密度估计器的梯度是递增的,而其收敛点即为密度梯度的局部极大值点,这个局部极大值即对应特征空间中的一个模式。
Mean-Shift算法对于概率密度函数的估计通常采用Parzen窗函数法,即核密度估计器。在d维空间Rd中,给定n个数据点xi,i=1,2…n,点x的多变量核密度估计器的计算式如式(3)所示。这个估计量可以由核K(x)和一个对称正定的d×d宽度的矩阵H来表示。
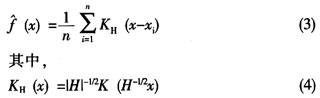
一般情况下,具有d个变量的核K(x)是一个满足以下条件的边界函数:
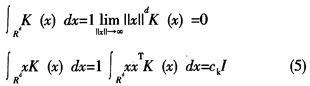
其中,ck是一个常量。从图像分割的目的出发,多变量核K (x)采用的是放射状对称核Ks(x)=ak,dK1(‖x‖),其中K1(z)是一个对称的单变量核,且K (x)满足下式:
![]()
其中,ck,d是可使K (x)等于1的归一化常量。
带宽矩阵H一般选择对角阵,H=diag[h12,…,h2d]或与单位矩阵H=h2I成比例。H=h2I情况下的一个明显优点是只需带宽参数h>0。然而,从式(4)可以看出,首先应确定用于特征空间的欧几里德矩阵的有效性。若使用一个宽度参数h,则式(3)就会变成如下典型的表示式:
![]()
将(6)式代入上式,就可以得到一个通用的、用核符号表示的核密度估计式:
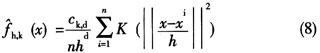
对有基本密度函数f(x)的一个特征空间,Mean-Shift算法分析的第一步是找到这个密度模式,然后对这个模式进行相关聚类。此模式应该在梯度▽f(x)=0的零点当中,而Mean-Shift程序是不用估计密度,而直接对密度的梯度进行估计,就能定位这些零点。
对于Mean-Shift算法的应用与分割,首先,可设xi和zi(i=1,2,…,n)分别为n维空间内的输人和联合的空值域内的滤波图像的像素,Li为分割后的图像中的第i个像素。那么,其操作可分为以下步骤:
(1)运行均值平移滤波程序对图像进行滤波,并存储所有d维空间内在zi处的收敛点zi=yi,c。
(2)在联合域中对所有的zi进行分组以描述类,这些类{Cp}p=1…m在空域内较hs较近,在值域内较hr较近。
(3)对于每一个i=1,…,n,并记为:
Li={p|zi∈Cp|}
(4)消除在空间区域内少于M个像素的区域。
1.2 Mean-Shift方法的分割结果
Mean-Shift算法分割的结果如图1~图3所示。
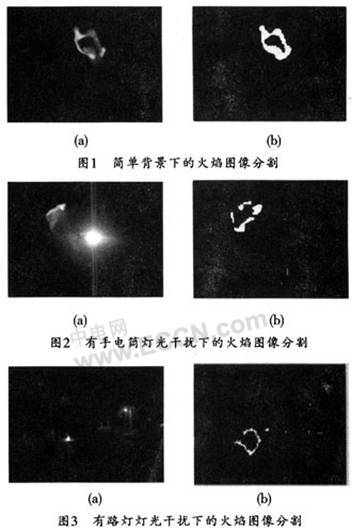
其中图1为背景较为简单的火焰图像的分割结果,图2为有手电筒光干扰下的火焰图像,图3为有路灯灯光干扰下的火灾图像。三幅图中的(a)均为原图,(b)为分割后的结果。可以看出,在三种情况下,该算法都能够有效的分割出火焰图像,从而确定火焰区域,以达到目标识别的目的

















 1641
1641




 到【灌水乐园】发言
到【灌水乐园】发言







