







上一篇介绍了线性可分的数据如何利用支持向量机做超平面,如果非线性的数据能否利用支持向量机来划分?结果是肯定的,需要引入核函数。
核函数:
在当前空间无法做线性划分时往往会映射到一个更高维的空间,在新的高维度空间中可以线性的概率将大大增加。这种从某个特征空间到另一个特征空间的映射是通过核函数来实现的。核函数可以被理解为这种转化的封装和解封装的过程,它能把数据从很难处理的方式转化成容易被处理的方式。
用公式标识就是当f(x)=W*X+b不能被线性化时,构建一个新的高维的公式:f(x)=W*F(x)+b
原决策点x在新的公式中可以用测试点和训练集合的内积来表示<F(Xi),F(X)>
前面推理过w的值是:
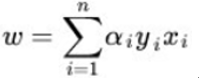
将决策点做替换后转化成:
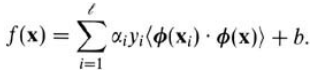
我们用K来代替内积:
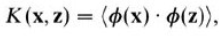
要做的就很简单了,在原来的代码中定义好转化的核函数,将算法中X内积换成用K来表达和计算,这样避开了复杂代码在高维空间的运算。
那么有了这些比较好理解的理论基础和改造方案后,现在的核心问题就集中在如何实现这个核函数。幸运的是已经有了成型的直接使用的核函数解法,有线性内核,多项式内核,径向基内核(RBF),sigmoid核,其中高斯核是应用最广泛的核函数之一,可以将原始空间映射为无穷维空间。
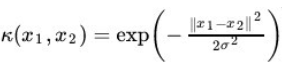
σ为函数的宽度参数,控制了函数的径向作用范围
简单总结核函数就是:高维度转化,低维度运算。至于核函数的选择,需要自己花大量时间去慢慢研究。
与上一篇代码比较主要的变化有2个,一个是引入了核函数k1,一个是对x求内积的部分都换成了k(I,j)的样式
代码如下:
#将X映射到高维的K上,用K参与smo计算
class optStrutsKernel :
def __init__(self,dataMatIn,labelMatIn, C, toler, kTup):
self.X = dataMatIn
self.Y = labelMatIn
self.C = C
self.toler = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
#误差缓存,第一列为是否有效(0无效,1有效),第二列为缓存的值
self.eCache = mat(zeros((self.m,2)))
self.K = mat(zeros((self.m,self.m)))
for i in range(self.m) :
self.K[:,i] = kernelTrans(self.X,self.X[i,:],kTup)
def kernelTrans(X,A,kTup) :
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin' :
K=X*A.T
elif kTup[0]=='rbf' :
for j in range(m) :
deltaRow = X[j,:]-A
tmpRow = deltaRow * deltaRow.T
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2))
else :
raise NameError('This kernel is not recognized')
return K
#用于选择第二个α,也就是αj
#保证选择的αj可以优化最大的步长,参考前面的公式labelMat[j] * (Ei-Ej)/eta
def selectJ(i, os, Ei):
maxK = -1
maxDeleteE = 0
Ej = 0
#1标识设置缓存为有效
os.eCache[i] = [1,Ei]
#构造非零E值所对应的alpha值构造的列表
validateEcacheList = nonzero(os.eCache[:,0].A)[0]
if len(validateEcacheList) >1 :
for k in validateEcacheList :
#配对优化,不能优化自己
if k==i :continue
#挨个算误差
Ek = calcEk(os, k)
deltaE = abs(Ei-Ek)
if deltaE>maxDeleteE :
maxK = k
maxDeleteE = deltaE
Ej = Ek
#返回具有最大误差的α坐标和误差Ek
return maxK, Ej
else :
#都为零,说明是起步阶段,随便选个非i的运算即可。
j = selectJrand(i,os.m)
Ej = calcEk(os, j)
return j, Ej
#算k的误差,并设置为有效
def updateEk(os , k) :
Ek = calcEk(os, k)
os.eCache[k] = [1, Ek]
#求k列的误差
def calcEk(os, k):
fXk = float(multiply(os.alphas,os.Y).T * (os.K[:,k]) + os.b)
#误差
ek = fXk - os.Y[k]
return ek
def innerL (i, os) :
#获取i的误差
Ei = calcEk(os,i)
if ((Ei*os.Y[i]<-os.toler) and (os.alphas[i]<os.C)) or \
((Ei*os.Y[i]>os.toler) and (os.alphas[i]>0)) :
j, Ej = selectJ(i, os, Ei)
alphas_i_old = os.alphas[i].copy()
alphas_j_old = os.alphas[j].copy()
if os.Y[i] != os.Y[j] :
L = max(0,os.alphas[j]-os.alphas[i])
H = min(os.C,os.C+os.alphas[j]-os.alphas[i])
else :
L = max(0, os.alphas[j] + os.alphas[i] - os.C)
H = min(os.C, os.alphas[j] + os.alphas[i])
if H==L : return 0
eta = 2.0*os.K[i,j]-os.K[i,i]-os.K[j,j]
if eta>=0 : return 0
os.alphas[j] -= os.Y[j]*(Ei-Ej)/eta
os.alphas[j] = clipAlpha(os.alphas[j],H,L)
updateEk(os,j)
if (abs(os.alphas[j]-alphas_j_old)<0.0001) : return 0
os.alphas[i] += os.Y[i]*os.Y[j] * (alphas_j_old - os.alphas[j])
updateEk(os, i)
b1 = os.b - Ei - os.Y[i] * (os.alphas[i] - alphas_i_old) * os.K[i, i] \
- os.Y[j] * (os.alphas[j] - alphas_j_old) * os.K[i, j]
b2 = os.b - Ej - os.Y[i] * (os.alphas[i] - alphas_i_old) * os.K[i, j] \
- os.Y[j] * (os.alphas[j] - alphas_j_old) * os.K[j, j]
if (0 < os.alphas[i]) and (os.alphas[i] < os.C):
os.b = b1
elif (0 < os.alphas[j]) and (os.alphas[j] < os.C):
os.b = b2
else:
os.b = (b1 + b1) / 2.0
return 1
else :
return 0
def smop(dataMatIn,labelMatIn, C, toler, maxInter, kTup=('lin',0)) :
#构造os辅助对象
os = optStrutsKernel(mat(dataMatIn),mat(labelMatIn).transpose(), C, toler,kTup)
iter = 0
entireSet = True
alphaPairsChanged = 0
while (iter<maxInter) and (entireSet or (alphaPairsChanged>0)) :
alphaPairsChanged = 0
if entireSet :
for i in range(os.m) :
alphaPairsChanged += innerL(i,os)
iter +=1
else :
nonBoundIds = nonzero((os.alphas.A>0)*(os.alphas.A<C))[0]
for i in nonBoundIds :
alphaPairsChanged += innerL(i, os)
iter +=1
if entireSet :
entireSet = False
elif alphaPairsChanged==0 :
entireSet = True
return os.b, os.alphas
def testRbf(k1=1.3) :
dataArr, labelArr = loadDataSet('C:\\2017\\提高\\机器学习\\训练样本\\svm\\testSetRBF.txt')
b, alphas = smop(dataArr, labelArr, 2, 0.0001, 10000,['rbf',k1])
dataMat = mat(dataArr)
labelMat = mat(labelArr).transpose()
svInd = nonzero(alphas.A>0)[0]
svs=dataMat[svInd]
labelSV = labelMat[svInd]
print('there are %d support vectors' % shape(svs)[0])
m,n = shape(dataMat)
errorCount = 0
for i in range(m) :
# 注意,这里的kernelEval和 kernelEval.T * multiply(labelSV, alphas[svInd])对应线性中的w,
# 用于预测时除开dataMat(代表入参特性)其它不能变
kernelEval = kernelTrans(svs,dataMat[i,:],['rbf',k1])
predic = kernelEval.T * multiply(labelSV,alphas[svInd])+b
if sign(predic)!=sign(labelArr[i]) : errorCount +=1
print('Training error rate is %f' %float(errorCount/m))
dataArr, labelArr = loadDataSet('C:\\2017\\提高\\机器学习\\训练样本\\svm\\testSetRBF2.txt')
dataMatTest = mat(dataArr)
labelMatTest = mat(labelArr).transpose()
m,n = shape(dataMat)
errorCount = 0
for i in range(m) :
kernelEval = kernelTrans(svs,dataMatTest[i,:],['rbf',k1])
predic = kernelEval.T * multiply(labelSV,alphas[svInd])+b
if sign(predic)!=sign(labelMatTest[i]) : errorCount +=1
print('Test error rate is %f' % float(errorCount / m))测试用例在git上:
https://github.com/yejingtao/forblog/blob/master/MachineLearning/trainingSet/svm/testSetRBF.txt
https://github.com/yejingtao/forblog/blob/master/MachineLearning/trainingSet/svm/testSetRB2F.txt
格式如下:
-0.214824 0.662756 -1.000000
-0.061569 -0.091875 1.000000
0.406933 0.648055 -1.000000
0.223650 0.130142 1.000000
0.231317 0.766906 -1.000000
-0.748800 -0.531637 -1.000000
当σ为1时,测试结果:
there are 16 support vectors
Training error rate is 0.030000
Test error rate is 0.110000
从k的最终结果可以看的出是沿中间径向对称的。
看到整个解题的思路已经有了,只剩下2个参数需要我们自己去确认,一个是C一个是σ
σ是高斯核函数的函数宽度, σ越小训练需要的支持向量越多,训练错误率越低,但是测试错误略越高;σ越大训练需要的支持向量越少,训练错误率越高,测试的错误率越小。
C是惩罚系数,即对误差的宽容度。c越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差
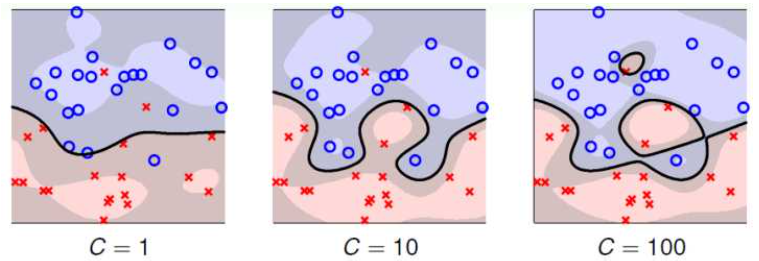
过拟合:在训练数据上表现良好,在未知数据上表现差。很好理解,就是太尊重训练集了,甚至把训练集的噪音等也当作正常数据在处理,这样算出来的结果对于训练集错误率肯定很低,但是不满足真正应用,所以在未知数据表现很差。
欠拟合:在训练数据和未知数据上表现都很差
训练过程中给定σ和C的固定值不断进行测试和优化,取其平衡。平衡点在哪?个人觉得当训练错误率与测试错误率相差不大而且错误率都不大时就可以,即能保证成功率又能保证实用性。
《机器学习实践》书中该章节给了个1024个特性的案例,图像识别,与k-近邻要干的事情一样(需要复习k-近邻的可参考k-近邻算法及代码),只不过不再每次都重新计算欧式距离权重后判断结果,而是事先经过训练将w、b保存起来,使用时省去了训练时间。这里的支持向量机是+1、-1二分的,所以训练集中只保留1和9两种样本,然后预测1和9的值。
代码如下:
#将图像文件32*32矩阵转化成1*1024矩阵
def image2Vector(fileName) :
#构建1维1024长度的0数组
returnVector = zeros((1,1024))
fi = open(fileName)
#读取每行文件内容,拼接到returnVector中
for i in range(32) :
lineSet = fi.readline()
for j in range(32) :
returnVector[0,32*i+j]=int(lineSet[j])
return returnVector
def loadImage(dir) :
from os import listdir
hwLabels = []
trainingFileList = listdir(dir)
m = len(trainingFileList)
trainingMat = zeros((m, 1024))
for i in range(m):
fileFileNameStr = trainingFileList[i]
fileName = fileFileNameStr.split('.')[0]
classNumStr = fileName.split('_')[0]
if classNumStr=='9' : hwLabels.append(-1)
else : hwLabels.append(1)
trainingFileName = dir + '\\' + fileFileNameStr
trainingMat[i, :] = image2Vector(trainingFileName)
return trainingMat, hwLabels
def testDigits(kTup=['rbf',10]) :
dataArr, labelArr = loadImage('C:\\2017\\提高\\机器学习\\训练样本\\svm\\digits\\trainingDigits')
b, alphas = smop(dataArr, labelArr, 200, 0.0001, 10000, kTup)
dataMat = mat(dataArr)
labelMat = mat(labelArr).transpose()
svInd = nonzero(alphas.A > 0)[0]
svs = dataMat[svInd]
labelSV = labelMat[svInd]
print('there are %d support vectors' % shape(svs)[0])
m, n = shape(dataMat)
errorCount = 0
for i in range(m):
#注意,这里的kernelEval和 kernelEval.T * multiply(labelSV, alphas[svInd])对应线性中的w,
#用于预测时除开dataMat(代表入参特性)其它不能变
kernelEval = kernelTrans(svs, dataMat[i, :], kTup)
predic = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
if sign(predic) != sign(labelArr[i]): errorCount += 1
print('Training error rate is %f' % float(errorCount / m))
dataArr, labelArr = loadImage('C:\\2017\\提高\\机器学习\\训练样本\\svm\\digits\\testDigits')
dataMatTest = mat(dataArr)
labelMatTest = mat(labelArr).transpose()
m, n = shape(dataMatTest)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(svs, dataMatTest[i, :], kTup)
predic = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
if sign(predic) != sign(labelMatTest[i]): errorCount += 1
print('Test error rate is %f' % float(errorCount / m))测试用例在git上:
https://github.com/yejingtao/forblog/tree/master/MachineLearning/trainingSet/svm/testDigits
https://github.com/yejingtao/forblog/tree/master/MachineLearning/trainingSet/svm/trainingDigits
there are 128 support vectors
Training error rate is 0.000000
Test error rate is 0.005376















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









