







 本文介绍了强化学习的主要方法,包括基于价值的Q-learning,适用于连续场景的Policy Gradient,以及结合两者的Actor-Critic算法。Q-learning在离散空间中寻找最优策略,Policy Gradient则直接优化策略,而Actor-Critic算法结合了价值函数和策略搜索,实现策略的稳定优化。
本文介绍了强化学习的主要方法,包括基于价值的Q-learning,适用于连续场景的Policy Gradient,以及结合两者的Actor-Critic算法。Q-learning在离散空间中寻找最优策略,Policy Gradient则直接优化策略,而Actor-Critic算法结合了价值函数和策略搜索,实现策略的稳定优化。
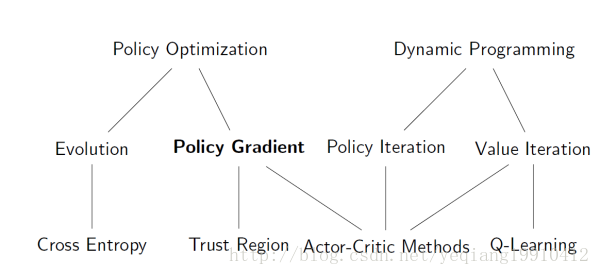
图1 强化学习算法的分类
强化学习方法主要包括:基于价值的方法,如Q-learning,DQN;基于策略搜索的方法(Policy Gradient);以及两者的结合行为-评判模型(actor-critic)等。
一、强化学习算法基本思想
Q-learning一般针对离散空间,采用值迭代方法。以value推policy。Q-learning通过计算每一个状态动作的价值,然后选择价值最大的动作执行.
Policy Gradient针对连续场景,直接在策略空间求解,泛化更好,直推policy。不通过分析奖励值, 直接输出行为的方法.
注:对比起以值为基础的方法,Policy Gradients 直接输出动作的最大好处就是, 它能在一个连续区间内挑选动作, 而基于值的, 比如 Q-learning, 它如果在无穷多的动作中计算价值, 从而选择行为, 这, 它可吃不消.
actor-critic可以看作是一个共轭,互相作用,策略也更稳定。
二、策略梯度方法(Policy-G
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2182
2182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









