






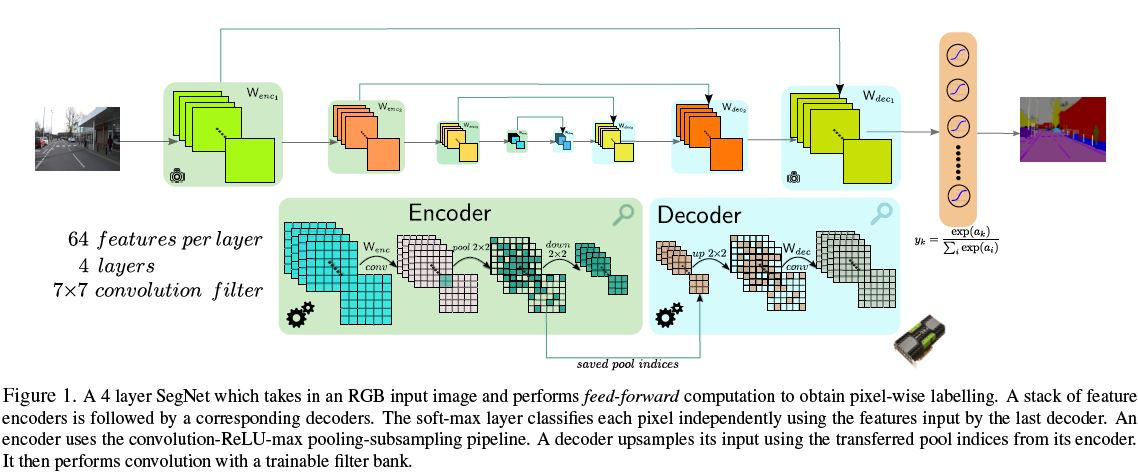
框架:SegNet, a deep convolutional encoder-decoder architecture
框架组成部分:A stack of encoders
+ a corresponding decoder stack
+ then feed into a softmax classification layer
应用:semantic pixel wise image labeling
三个亮点:1、only require forward evaluation of a fully learnt function to obtain smooth label predictions
(仅需要一个前向估计函数就可以获得平滑标签预测)
2、with increasing depth (of neural network), a larger context is considered for pixel labeling which improves accuracy.
(网络深度增加,像素点context信息能够考虑到)
3、be easy to visualizes the effect of feature activations in the pixel labels space at any depth.
(在网络的任何一层,都可以可视化特征)
Framework
















 1832
1832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









