







 这篇论文介绍了SegNet,一个用于图像语义分割的深度卷积编码-解码架构。它基于VGG16,通过对称网络结构和去池化方法实现端到端训练,尽管增加了一些计算复杂性,但提高了准确性。与其他去卷积网络如FCN和U-Net相比,SegNet的网络规模更小,但在运行速度上较慢。
这篇论文介绍了SegNet,一个用于图像语义分割的深度卷积编码-解码架构。它基于VGG16,通过对称网络结构和去池化方法实现端到端训练,尽管增加了一些计算复杂性,但提高了准确性。与其他去卷积网络如FCN和U-Net相比,SegNet的网络规模更小,但在运行速度上较慢。
论文链接:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
caffe代码:https://github.com/TimoSaemann/caffe-segnet-cudnn5
工程主页:http://mi.eng.cam.ac.uk/projects/segnet/
本篇论文使用了对称的Encoder-Decoder网络结构来实现语义分割,如下图:
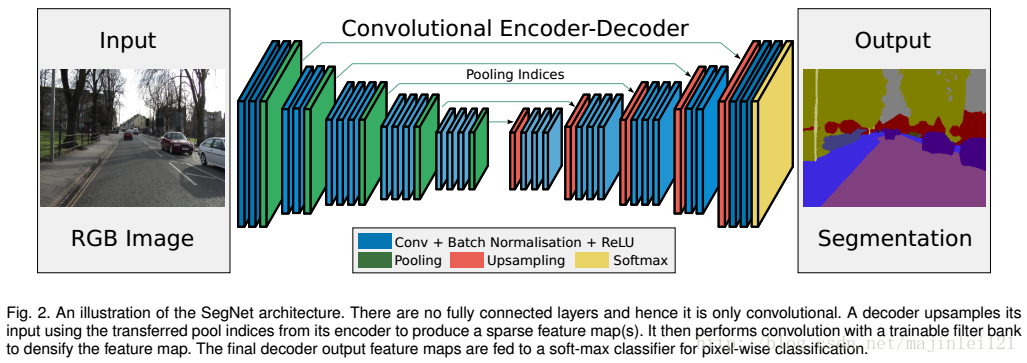
基于VGG16的对称网络结构,网络把全卷积层去掉了,这样就可实现end-to-end的训练,节省计算时间。
论文中提到如果把encoder卷积层的信息加入到decoder中会提高准确率,但是运算消耗增加,因此作者并没有这么做,采用了一种Unpooling的方法,如下图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1832
1832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









