




 PCA(主成分分析)用于处理高维数据,通过线性变换减少特征冗余。本文深入探讨PCA的动机、定义、相关知识、处理流程及特征值的重要性,揭示PCA如何增强数据的表征能力并进行有效的降维。
PCA(主成分分析)用于处理高维数据,通过线性变换减少特征冗余。本文深入探讨PCA的动机、定义、相关知识、处理流程及特征值的重要性,揭示PCA如何增强数据的表征能力并进行有效的降维。
转载请注明出处:blog.csdn.net/yobobobo
最近自学的重点是特征工程,首当其冲的当然是PCA,可是看了好几篇国内搜索靠前的博客大部分都是做法而不是原理,为什么协方差矩阵的特征值最大就说明投影到这个特征向量上比其他的好呢?对于机器学习大部分时间都是调用别人写好的库就像是个用着黑盒子的感觉,特来一发原理,附上完整的数学推导。
Motivation———PCA的作用是什么,我们为什么要用PCA
你手上有一批数据,但是特征太多,你感觉数据太稀疏了
你选了一堆特征,但是感觉某些特征之间的相关性太高了,比如用户月消费预测的时候,你选了用户身高以及用户性别这两个特征,一般男生的身高比较高,你觉得特征有点冗余
你的小霸王内存不够,内存只有4个G,装不下太大的矩阵,但是你又不想减少训练数据,N*M的数据集,你不想减少N,下一步只有减少M了
你想减少M了,可是你又不知道哪些特征该扔掉,就算你选出了一些看起来不是那么好的特征扔掉你又怕这些特征扔掉后对模型的影响很大
Definition———PCA是啥?
- wiki翻译----PCA是一门数据统计方案,通过一个正交转换把可能线性相关的变量转换为几乎线型无关的变量(这些变量称作主成分)。主成分的数量比原来的变量数量更少或者一致。
- 通俗地讲,PCA就是把N维的向量经过线型变换转化为K维的向量(K<=N),需要注意的是,并不是把N-K维的特征扔掉了。
Related knowledge———要预备的知识
- 向量点积的几何意义
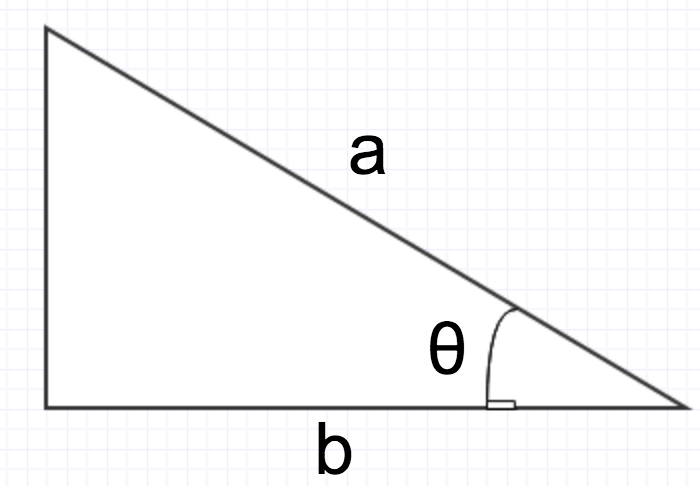
- a∗b=∥a∥∗∥b∥∗cosθ
- ∥a∥∗cosθ 相当于把a投影到b向量上的长度 当 ∥b∥ 为1的时候,a*b就相当于把a投影到向量b上的长度
- 协方差矩阵
- 方差足够了吗?
- 以前上小学的时候,老师经常把某个学生的成绩记录作为讲解方差的经典例子,A的成绩均值和B的成绩均值一样,这时候怎么区分谁更好呢?
- 答日:A的方差比B的方差更小,说明A的成绩更加稳定。
- 然而这是小学,处理一维的数据已经足够了。
- 现实中的数据都是远远超过一维的,现在广告推荐的大规模LR训练特征可达上亿维度,方差已经不能再像以前一样:“较均值,取方差”。
- 协方差登场
- 定义: cov(a,b)=∑ni=1(Xi−X⎯⎯)(Yi−Y⎯⎯)n−1
- 意义:表示两个数据的线型相关性,当 cov(a,b) > 0的时候,说明 a 和
b 的是正相关的, a 越大b 越大,反之时负相关的,为0则说明两者线型无关。 - 协方差矩阵
顾名思义,就是不同变量之间的协方差组成的矩阵
cov(a,a)cov(b,a)cov(c,a)cov(a,b)cov(b,b)cov(c,b)cov(a,c)cov(b,c)cov(c,c)
Main Process———处理流程
- 均值置0,把每一维度的特征都减去该维特征的均值,为了接下来的运算以及解释方便点
- 求出数据集X的协方差矩阵M
- 求解M的特征值对角阵以及特征向量矩阵
- 选取前K大的特征值,将其对应的特征向量作为列向量,组成一个矩阵T
- X*T,得到降维之后的矩阵,完毕。
Why———为什么特征值这么神奇
- 核心:方差越大,数据的表征能力越强
- 给你两组数据,一组数据基本集中于某个点,另一组数据零零散散的,你认为哪个数据更好?一般都认为后者更好,因为前者可能是数据太少了,数据都集中于某一个点,这样的数据训练出来的模型泛化能力很差,后者的数据可以认为比较样本空间覆盖度高,训练出来的模型泛化能力更强。
- 从上一个例子,我们可以认为:方差越大,数据的表征能力越强
详细———线型变换
- 我认为当前数据的方差还不够大,可以把数据投影到另一个向量空间后以增大数据的方差,提升数据的表征能力
- 根据第3节,数据投影可以表示为乘以一个模为1的向量,根据方差最大的思想,可以得到这样的目标函数
- w(1)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1025
1025






 到【灌水乐园】发言
到【灌水乐园】发言







