







从上周开始,突然想起了正则化这么个东西,一直都听到加个范数就可以防止过拟合,正则化为什么这么神奇呢?
断断续续地看了一周的相关书籍,博客,决定先来个短暂的总结,以后有了更深入的理解再来补充。
什么是过拟合
先来一张图:
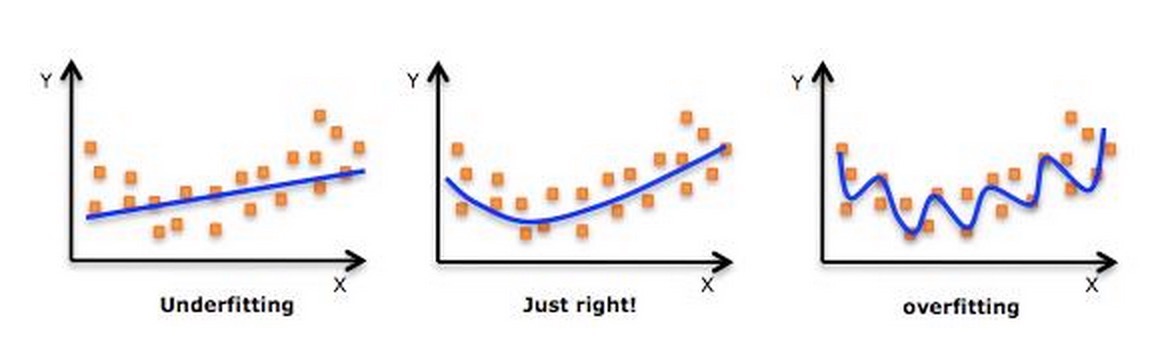
过拟合指的是模型学习时过于复杂,以至于出现这一模型对已知的数据预测得很好,但是对未知数据预测得很差的现象。换言之,就是模型在训练集上表现的很好(均方差优化到1e-10了),可是在预测集上表现相当糟糕。从上面的图我们可以看到,右侧的图明显是过拟合了,模型在训练集上的优化目标可以优化到很优秀,可是对于接下来要预测的数据来说,并没有什么用。
接下来,我们以 logistic regression 模型作为basis,看下正则化项是怎么通过看似简单的范数来影响我们的模型得到防止过拟合的。
第一范数正则化项
定义:
第一范数定义 L1:∑ni=1|wi| ,简而言之,就是每个参数的绝对值只和。
模型变化:
原来的 LR 模型优化目标是最小化损失函数,即:
L(w)=1N∑N1(f(xi,w)−yi)2
现在我们给它加上一个一范数正则化项,有:
L(w)=1N∑N1(f(xi,w)−yi)2+λ||w||1
基于 Occam’s razor 的解释
为什么加上这么一个项就可以了呢,我们先来引入奥卡姆剃刀原理:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单的模型才是最好的模型,也就是应该选择的模型。从拉格朗日乘子法的计算过程我们可以把后面加的那个一范数正则化项当做一个限制,现在,让我们通过一张图来看下这项是怎么调整我们的模型来降低过拟合的:
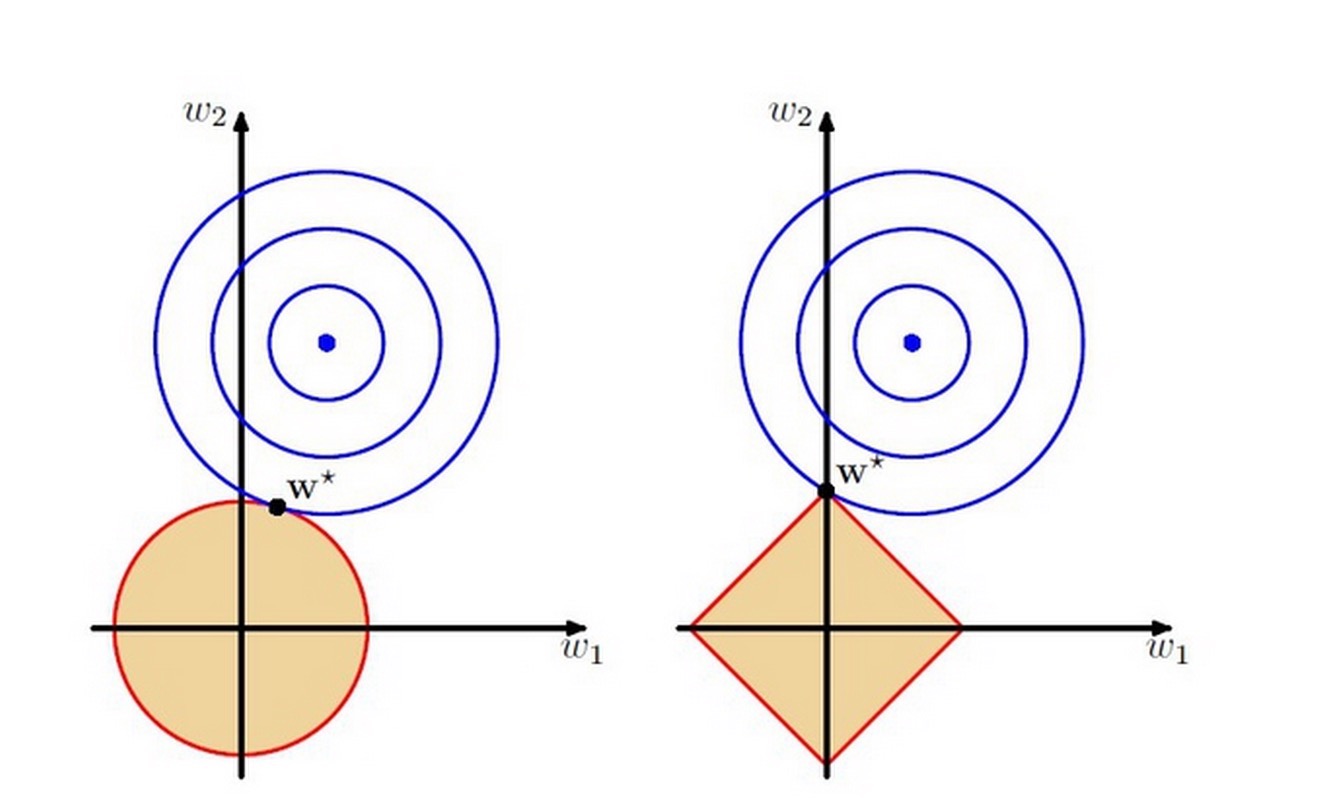
图片来自 PRML 的第三章。
上图中的模型是线性回归,有两个特征,要优化的参数分别是w1和w2,左图的正则化是l2,右图是l1。蓝色线就是原始目标函数优化过程中遇到的等高线,一圈代表一个目标函数值,受限条件就是红色边界(就是正则化那部分),二者第一次相交处,就是我们要找的最优化参数。
可以看到
L1
范数的限制区域比较尖,优化目标和限制区域相交的时候更大概率在尖尖的部分,可以这么想,你把一个圆往一个正方形移动,肯定更大概率先撞到正方形的角。
相交点落在坐标轴上表明什么:有0的权值产生!
好了,突然一下子就明朗了,
L1
范数会使我们的模型在优化目标函数的过程中偏向模型稀疏(某些特征对应的权重为0),这完全符合剃须刀原理,都一样的优化结果,模型越简单越好。
第二范数正则项
定义:
第一范数定义 L1:∑ni=1(wi)2 ,简而言之,就是个参数的绝对值只和。
模型变化
现在我们给它加上一个一范数正则化项,有:
L(w)=1N∑N1(f(xi,w)−yi)2+λ||w||2
condition number
从 zouxy 的博客里面了解到这个keyword,Wiki 了一下:In the field of numerical analysis, the condition number of a function with respect to an argument measures how much the output value of the function can change for a small change in the input argument. This is used to measure how sensitive a function is to changes or errors in the input, and how much error in the output results from an error in the input.condition number 用来衡量一个模型对输入的敏感程度,当输入变化稍微变化一点点的时候,如果输出变化很大,说明我们的模型对输入的数据很敏感,这并不是一个好的现象,在做 Titanic 的时候,年龄更小的存活率更加高(小孩子可以优先逃生),如果我们的模型对数据比较敏感,10岁和11岁预测出来的存活概率相差特别大,这显然是我们不愿意看到的。因此,我们在优化的过程中希望我们训练出来的模型很稳定,不会因为输入数据的稍微一点点变化而导致预测结果的天翻地覆。
再遇贝叶斯
在上一节中,我们提到模型的稳定性问题,我们希望模型足够稳定,所以我们在优化的过程中加入这么个先验,

我们相当于是给模型参数w 添加了一个协方差为
1α
的零均值高斯分布先验。 对于
α=0
,也就是不添加正则化约束,则相当于参数的高斯先验分布有着无穷大的协方差,那么这个先验约束则会非常弱,模型为了拟合所有的训练数据,w可以变得任意大不稳定。
α
越大表明先验的高斯协方差越小,w 的波动范围越小,模型越趋于稳定, 相对的variance也越小。
总结
又一次近距离接触到贝叶斯的强大,可以这么说,正则化项对英语模型的先验概率,可以假设复杂不稳定的模型有较小的先验概率,简单稳定的模型有较大的先验概率。















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









