







基于《【Mapreduce】以逗号为分隔符的WordCount词频统计》(点击打开链接)中Mapreduce的处理过程,由于Mapreduce会在Map~reduce中,将重复的Key合并在一起,所以Mapreduce很容易就去除重复的行。
Map无须做任何处理,设置Map中写入context的东西为不作任何处理的行,也就是Map中最初处理的value即可,
而Reduce同样无须做任何处理,写入输出文件的东西就是,最初得到的Key,
因此其代码比WordCount还要简单,具体如下:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MyMapReduce {
public static class MyMapper extends
Mapper<Object, Text, Text, IntWritable> {
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
context.write(value, new IntWritable());// 这里不能为NULL,只能是new
// IntWritable(),不然会报空指针异常
}
}
public static class MyReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
context.write(key, null);// 这里则可以是为null,写入文件的value值为空,也就就是什么都不写,只写键
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "");
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}以下是输入文件:

以下是输出文件:
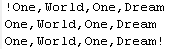















 4958
4958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









