







MapReduce是一种分布式并行编程。分布式程序运行在大规模计算机集群上,可以并行执行大规模数据任务,从而获得海量的计算能力。
MapReduce相对传统的并行计算框架
| 传统并行计算框架 | MapReduce |
|---|---|
| 集群架构容错性 | 共享式(共享内存/g共享存储).容错性差 |
| 硬件/价格/扩展性 | 刀片服务器、高速网、SAN、价格贵、扩展性差 |
| 编程/学习难度 | 难 |
| 适用场景 | 实时、细粒度计算、计算密集型 |
MapReduce框架
- MapReduce将复杂的,运行大规模集群上的并行计算过程高度地抽象两个函数:Map和Reduce+ + MapReduce采用“分而治之”策略,将一个分布式文件系统中的大规模数据集,分成许多独立的分片。这些分片可以被多个Map任务并行处理。
- MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,原因是,移动数据需要大量的网络传输开销
- MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave,Master上运行JobTracker,Slave运行TaskTracker
- Hadoop框架是用JAVA来写的,但是,MapReduce应用程序则不一定要用Java来写。
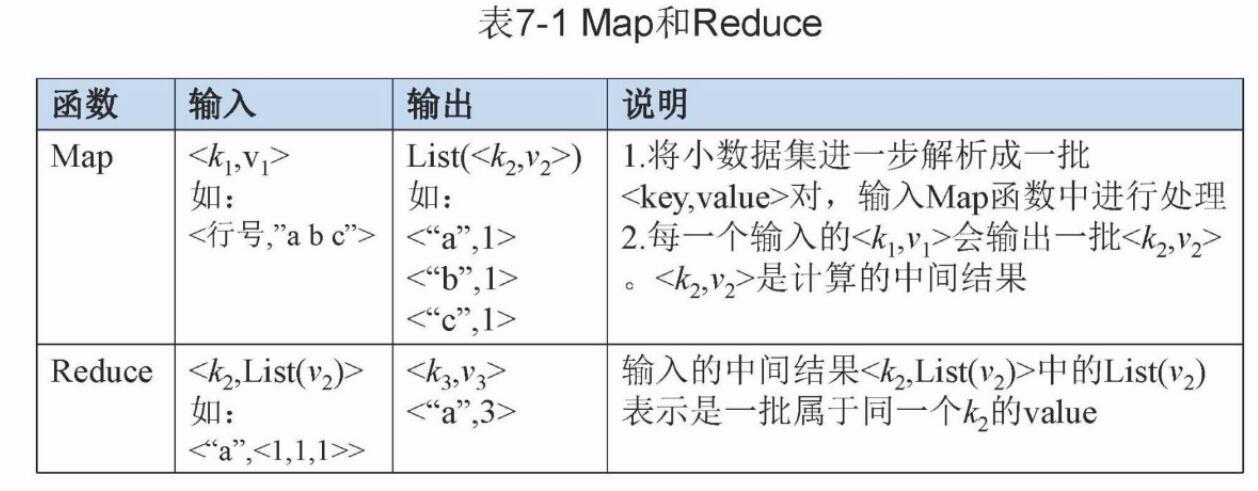
Map函数和Reduce函数
MapReduce体系架构
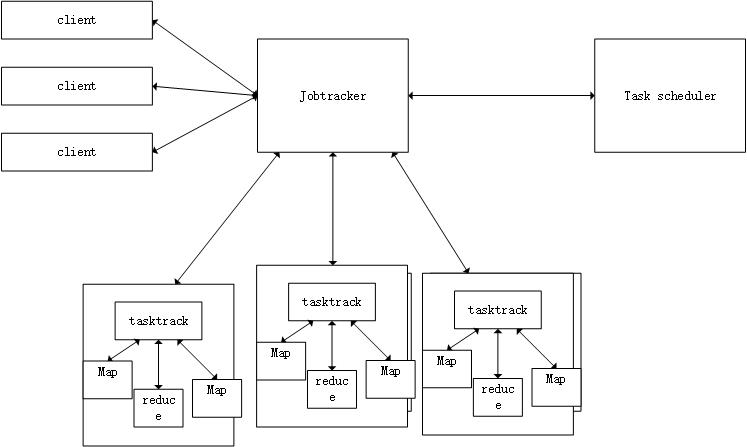
MapReduce主要有以下4个部分组成:
- 1.Client
- 用户编写的MapReduce程序通过Client提交到JobTracker
- 用户可通过Client提供一些接口查看作业的运行状态
- JobTracker
- Jobtracker负责资源监控和作业调度
- JobTracker监控所有TaskTracker与job的健康情况
+ JobTracker会跟踪任务的执行进度、资源使用量等消息,并将这些消息告知(TaskScheduler)
而任务调度器会在资源出现空闲时,选择合适的任务去执行。
- Tasktracker
+ TaskTracker会周期性通过“心跳”把资源使用情况和任务进度汇报给JobTracker,同时接收JobTracker发送过来的命令执行相应的操作
- TaskTracker使用“slot”等量划分本节点的资源量,一个Task获得slot后才执行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用,slot分为 Map slot和reduce slot两种,分别给相应的MapTask和reduceTask使用
- Task
Task分为Map Task和Reduce Task两种,均由TaskTracker启动
















 6284
6284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











