






随着技术的不断进步,LLM 带来了前所未有的机遇,吸引了开发者和组织纷纷尝试利用其强大的能力构建应用程序。然而,当预训练的 LLM 在实际应用中无法达到预期的性能水平时, 人们就会思考到底使用什么样技术进行改善特定场景LLM的表现, 其中微调和RAG方案都是优化LLM的重要方案。
微调和RAG都是作为现在LLM优化的重要技术, 孰优孰劣?一直是开发者们常常争论的话题, 同时作为一名刚入门的开发者也分不清要使用微调还是RAG来优化自己的应用场景, 也有一些初学者常常将这两个概念混淆起来。在对比之前,我们先简单了解微调和RAG。
01 微调
微调(Fine-Tuning)过程的核心,是在新的任务和数据集上对预训练模型的参数进行微小的调整,使其能精准契合目标场景的需求。不同于完全从头训练一个全新模型,Fine-Tuning (微调)巧妙地利用了 PLM 在大规模语料上学习到的通用语义表征,在此基础上进行"权重调校",从而大幅提高了模型收敛的速度和效率, 微调本质是将特定领域知识记忆纳入到模型的参数中, 经过微调后,模型可以为你提供更准确、更接近你特定领域的答案。
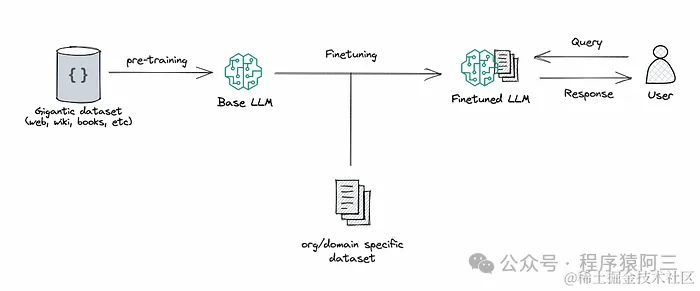
之前《研究篇| 一款深入浅出的微调框架》介绍的微调框架,可以很方便帮助大家快速微调一个新模型出来, 微调方式也有其优势和弊端:
1.1 优点:
-
自定义:微调允许广泛的自定义,使模型能够生成针对特定领域或风格的响应。
-
提高准确性:通过在专门的数据集上进行训练,模型可以产生更准确、更相关的响应。
-
适应性:经过微调的模型可以更好地处理原始训练过程中未涵盖的小众主题或最新信息
1.2 缺点:
-
成本:微调需要大量计算资源,可以从我之前文章《》去预估微调模型所需的资源。
-
技术技能:这种方法需要更深入地了解机器学习和语言模型架构, 要求从业必须深刻了解底层模型原理以及参数配置。
数据要求:有效的微调工作需要大量且精心策划的数据集,数据集是微调模型的必然要求, 收集自己领域的数据并非易事, 虽然现在也出现一些数据集是利用chatgpt方式生成, 但是总体要生成高质量数据集也非易事。
02 RAG
之前在《应用篇| 深入浅出LLM应用之RAG》文章全面介绍过RAG(Retrieval-Augmented Generation),本质是利用外挂的知识库作为模型的记忆扩充,RAG 无需重新训练模型,便能扩展 LLM 已有的强大能力,让其能够适用于新的领域或组织的内部知识库。这是一种经济高效的方式,能够提升 LLM 输出的准确性、相关性和实用性,使其在各种环境中依然保持出色表现。
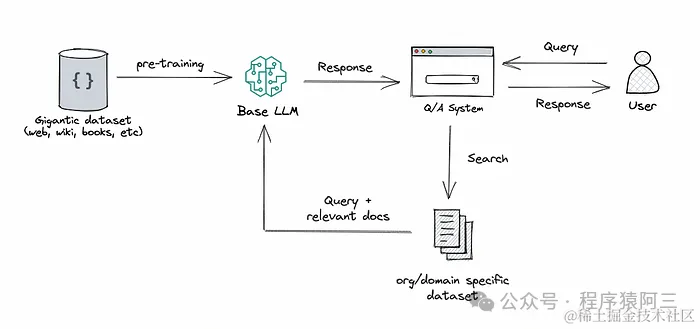
2.1优点:
-
动态信息:通过利用外部数据源,RAG 可以提供最新且高度相关的信息。
-
平衡:在提示的简易性和微调的定制能力之间提供了中庸之道。
-
上下文相关性:通过附加的上下文来增强模型的响应,从而产生更明智和更细致的输出。
2.2 缺点:
-
复杂性:RAG 实现起来可能很复杂,需要语言模型和检索系统之间做好集成。RAG 系统的成本、速度和响应质量严重依赖于矢量数据库,所以这种数据库成为了 RAG 系统中非常重要的一部分。
-
资源密集型:虽然 RAG 的资源密集程度低于完全微调的方法,但它仍然需要相当大的计算能力。
-
数据依赖性:输出的质量在很大程度上取决于检索到的信息的相关性和准确性。所以RAG检索效果对入库的数据质量也有要求。
03 微调 VS RAG
| 特性 | 微调 | RAG |
| 所需技能等级 | 中等到高等:需要了解机器学习原理和模型架构。 | 中等:需要了解机器学习和信息检索系统。 |
| 成本与资源 | 高:训练需要大量计算资源。 | 中等:需要检索系统和模型交互的资源,但需求少于微调。 |
| 可定制性 | 高:允许对特定域或样式进行广泛的定制。 | 中等:可通过外部数据源进行定制,但定制自由度取决于其质量和相关性。 |
| 数据需求 | 高:需要大量相关的数据集才能进行有效的微调。 | 中等:需要访问相关的外部数据库或信息源。 |
| 升级频率 | 变量:取决于何时使用新数据重新训练模型。 | 高:可以纳入最新的信息。 |
| 质量 | 高:针对特定数据集进行定制,从而获得更相关、更准确的响应。 | 高:利用上下文相关的外部信息增强响应。 |
| 用例 | 专业应用、特定行业需求、定制任务。 | 需要最新信息的情况以及涉及上下文的复杂查询。 |
| 实现难度 | 高:需要深入的设置和训练过程。 | 中等:需要将语言模型与检索系统相结合。 |
总结来说,微调在时间、成本、以及复杂度几个维度而言,都是大于RAG:

对于初级应用者,可以优先考虑RAG, 这样前期投入相对少一点,也不是说选择RAG就完全放弃了微调, 在建立RAG系统时候,也要考虑收集用户对话信息和反馈,后面可以利用这些真实数据, 为后续微调做好“粮食”准备. 两者并非顾此失彼, 选其一而必须放弃另外一方,现在也有RAG系统结合微调的方式出现:
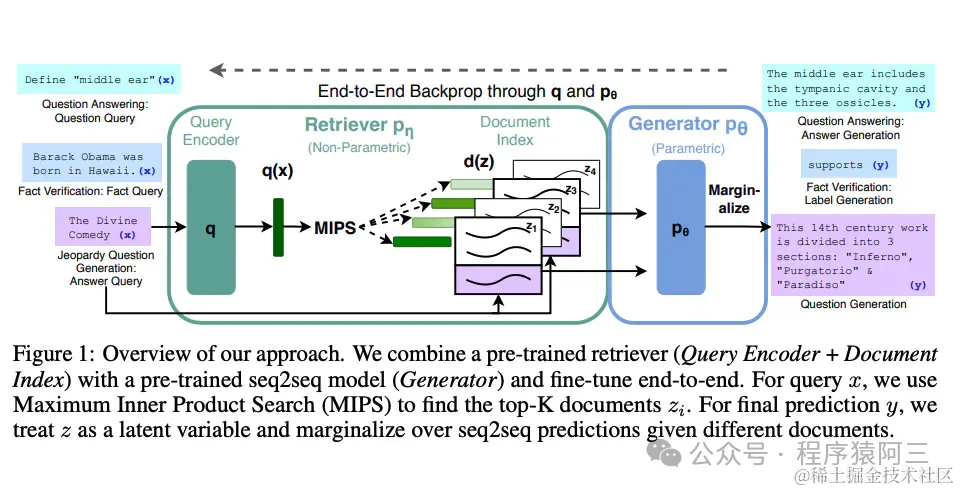
Lewis 等人(2021)提出一个通用的 RAG 微调方法。这种方法使用预训练的 seq2seq 作为参数记忆,用维基百科的密集向量索引作为非参数记忆(使通过神经网络预训练的检索器访问)。
04 总结
微调是一种让预先训练好的模型适应特定任务或数据集方法。这种情况下,模型会学习开发者提供的微调数据。
知识库是使用向量数据库(或者其他数据库)存储数据,可以外挂,作为LLM的行业信息提供方。简单理解, 微调相当于让大模型去学习了新的一门学科,在回答的时候完成闭卷考试。知识库相当于为大模型提供了新学科的课本,回答的时候为开卷考试。 知识库和微调并不是冲突的,它们是两种相辅相成的行业解决方案。开发者可以同时使用两种方案来优化模型。例如:使用微调的技术微调ChatGLM3-6B大模型模拟客服的回答的语气和基础的客服思维。接着,外挂知识库将最新的问答数据外挂给ChatGLM3-6B,不断更新客服回答的内容信息。
现在将两者结合起来的方案也开始逐渐流行起来, 所以成年人不做选择, 而是都要, 两者都可以为我们所用。
推荐阅读:
更多合集文章请关注我的公众号,一起学习一起进步:
















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











