







 本文介绍了散列表中的直接寻址技术和两种散列方法:乘法散列法和全域散列。乘法散列法通过h(k) = m * (k * A mod 1) (0<A<1)实现,全域散列则是随机选择散列函数以优化平均查找时间。在查找长度为n的链表中具有特定关键字k的元素时,可以通过元素的散列值h(k)进行快速定位。对于长度为r的字符串,使用除法散列法时,可以在占用常数个机器字的情况下计算其散列值,通过分别对每个字母取模再求和的方式利用模运算性质。
本文介绍了散列表中的直接寻址技术和两种散列方法:乘法散列法和全域散列。乘法散列法通过h(k) = m * (k * A mod 1) (0<A<1)实现,全域散列则是随机选择散列函数以优化平均查找时间。在查找长度为n的链表中具有特定关键字k的元素时,可以通过元素的散列值h(k)进行快速定位。对于长度为r的字符串,使用除法散列法时,可以在占用常数个机器字的情况下计算其散列值,通过分别对每个字母取模再求和的方式利用模运算性质。
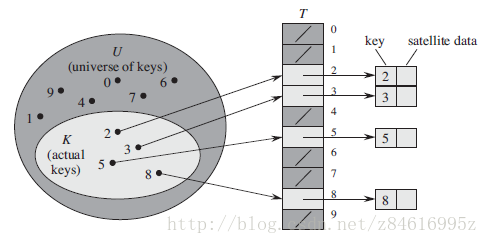
11.1直接寻址表
关键字集合U = { 0, 1, ..., m - 1 },实际的关键字集合K。
用一个数组T[0..m - 1],其中每个位置对应U中的一个关键字k。
把关键字k映射到槽T(k)上的过程称为散列。
散表表仅支持INSERT、SEARCH、DELETE操作。
11.1-1假设一动态集合S用一个长度为m的直接寻址表T表示。请给出一个查找S中最大元素的过程。你所给的过程在最坏情况下的运行时间是多少?
查找指定元素所用时间为O(1),如果找表中最大值,那么最坏情况下需要循环遍历散列表中所有有效值以确定最大值。运行时间为O(m).
struct Hash* direct_address_search(struct Hash *T[], int key)
{
int Max=0;
while (key!=MAX)//MAX表示散列表容量最大值
{
if (T[key]!=NULL&&Max<T[key]->key)
{
Max=T[key]->key;
}
key++;//key既可以表示直接寻址表T的下标,也可以表示关键字
}
}
11.1-2位向量是一个仅包含0和1的数组。长度为m的位向量所占空间要比包含m个指针的数组少得多,请说明如何用一个位向量表示一个包含不同元素(无卫星数据)的动态集合。字典操作的运行时间应为O(1).
核心思想:如果插入元素x,那么把位向量的第x位设置为1,否则为0. 如果删除元素x,那么把位向量的第x位设置为0。
#include <stdio.h>
#include <stdlib.h>
#define INT_BIT 32
typedef struct {
unsigned int *table;
int size;
} BitMap;
BitMap * bitmap_create(int max)
{
BitMap *bitmap = (BitMap *)malloc(sizeof(BitMap));
bitmap->size = max / INT_BIT + 1;
bitmap->table =(unsigned int *) calloc(sizeof(int), bitmap->size);
return bitmap;
}
void bitmap_insert(BitMap *bitmap, int key)
{
bitmap->table[key / INT_BIT] = bitmap->table[key / INT_BIT] |(1 << (key % INT_BIT));
}
void bitmap_delete(BitMap *bitmap, int key)
{
bitmap->table[key / INT_BIT] &= ~(1 << (key % INT_BIT));
}
int bitmap_search(BitMap *bitmap, int key)
{
return bitmap->table[key / INT_BIT] & (1 << (key % INT_BIT));
}
void bitmap_print(BitMap *bitmap)
{
printf("-----\n");
int i;
for (i = 0; i < bitmap->size; i++)
if (bitmap->table[i] != 0)
printf("%d: %d\n ", i, bitmap->table[i]);
printf("-----\n");
}
int main(void)
{
BitMap *bitmap = bitmap_create(1024);
bitmap_insert(bitmap, 15);
bitmap_insert(bitmap, 10);
bitmap_insert(bitmap, 520);
bitmap_insert(bitmap, 900);
bitmap_delete(bitmap, 10);
bitmap_print(bitmap);
printf("%d\n", bitmap_search(bitmap, 68));
printf("%d\n", bitmap_search(bitmap, 520));
return 1;
}
参考资料来自:
直接寻址表的位向量表示
直接寻址表的位向量表示
11.1-3试说明如何实现一个直接寻址表,表中各元素的关键字不必都不相同,且各元素可以有卫星数据。所有三种字典操作(INSERT,DELETE和SEARCH)的运行时间应为O(1)
(不要忘记DELETE要处理的是被删除对象的指针变量,而不是关键字)。
#include <stdio.h>
#include <stdlib.h>
#define LEN sizeof(struct Hash)
#define MAX 6
struct Hash{
int key;
int satellite;
}Data; //元素结构体,有关键字和卫星数据
struct Hash* direct_address_search(struct Hash *T[], int key); //散列表查找操作
void direct_address_insert(struct Hash *T[], struct Hash *x); //散列表插入操作
void direct_address_delete(struct Hash *T[], struct Hash *x); //散列表删除操作
void print_table(struct Hash *T[]); //打印散列表(为了方便查看删除操作后,散列表的变化)
int main(){
int i, key, satellite;
struct Hash *data[MAX];
struct Hash *d;
for(i = 0; i < MAX; i++){
data[i] =new struct Hash [LEN];
data[i] = NULL;
}
for(i = 0; i <= 3; i++){
d = new struct Hash[LEN];
printf("Input the key_value:\n");
scanf("%d", &key);
printf("Input the satellite:\n");
scanf("%d", &satellite);
d->key = key;
d->satellite = satellite;
direct_address_insert(data, d);
}
print_table(data);
printf("请输入待查找的元素\n");
scanf("%d", &key);
d = direct_address_search(data, key);
if (d)
{
printf("the key is %d, and its satellite is %d\n", d->key, d->satellite);
}
else
{
printf("没有找到\n");
}
if (d)
{
direct_address_delete(data, d);
}
print_table(data);
delete d;
for(i = 0; i < MAX; i++)
delete data[i];
print_table(data);
return 0;
}
//直接返回下标为key的元素
struct Hash* direct_address_search(struct Hash *T[], int key){
return T[key];
}
//直接将元素插入下标key的位置里
void direct_address_insert(struct Hash *T[], struct Hash *x){
T[x->key] = x;
}
// 将要删除的元素所在的位置指向空指针
void direct_address_delete(struct Hash *T[], struct Hash *x){
T[x->key] = NULL;
}
//打印直接寻址表
void print_table(struct Hash *T[]){
int i;
for(i = 0; i < MAX; i++){
if(T[i] != NULL){
printf("key is %d, and its satellite is %d\n", T[i]->key, T[i]->satellite);
}
}
}
参考资料来自:
直接寻址表的字典操作
11.1-4我们希望在一个非常大的数组上,通过利用直接寻址的方式来实现一个字典。开始时,该数组中可能包含一些无用信息,但要对整个数组进行初始化是不太实际的,因为该数组的规模太大。请给出在大数组上实现直接寻址字典的方案。每个存储对象占用O(1)空间;SEARCH,INSERT和DELETE操作的时间均为O(1);并且对数据结构初始化的时间为O(1).(提示:可以利用一个附加数组,处理方式类似于栈,其大小等于实际存储在字典中的关键字数目,以帮助确定大数组中某个给定的项是否有效)
思路:我们用T表示大数组,用S表示含有所有有效数据的数组作为辅助栈。T的关键字作为下标,而数组T的值为数组S的下标,相反地,数组S的值为关键字,同时也是数组T的下标。这是一种循环形式 。设有关键字x,如果T[x]=y,那么S[y]=x.
#include <iostream>
using namespace std;
#define MAX 100
#define LEN sizeof(struct hash)
struct hash{
int key;
};
struct Stack
{
int STack[MAX];
int top;
};
void Init(struct Stack&s)
{
s.top=-1;
}
struct hash * search(struct hash Hash[],struct Stack&s,int k)
{
if (Hash[k].key>=0&&Hash[k].key<=s.top&&s.STack[Hash[k].key]==k)
{
cout<<"已经找到"<<endl;
return Hash+k;
}
else
{
cout<<"没有找到"<<endl;
return NULL;
}
}
void insert(struct hash Hash[],struct Stack&s,struct hash *x)
{
int k=x->key;
if (search(Hash,s,k))
{
cout<<"待插入的数据已经在散列表中!"<<endl;
return ;
}
else
{
s.top++;
s.STack[s.top]=k;
Hash[k].key=s.top;
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3846
3846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









