









一概要
YARN采用了Maser/Slave结构,其中Master实现为ResourceManager,负责整个集群的资源管理与调度; Slave实现为NodeManager,负责单个节点的资源管理与任务启动。
ResourceManager是整个YARN集群中最重要的组件之一,它的设计直接决定了系统的可扩展性、可用性和容错性等特点,它的功能较多,包括ApplicationMaster管理(启动、停止等)、NodeManager管理、Application管理、状态机管理等。
在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接受来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(即ApplicationMaster)。
注:ResourceManager主要完成一下几个功能:
1.与客户端交互,处理来自客户端的请求。
2.启动和管理ApplicatinMaster,并在它运行失败时重新启动它。
3.管理NodeManager,接受来自NodeManager的资源管理汇报信息,并向NodeManager下达管理命令(比如杀死Contanier)等。
4.资源管理与调度,接收来自ApplicationMaster的资源申请请求,并为之分配资源(核心)。
二 ResourceManager 内部结构
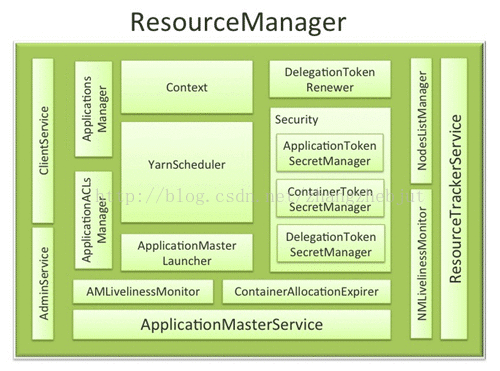
ResourceManager 内部组件
2.1.用户交互模块
RM分别针对普通用户(ClientRMService)、管理员(AdminService)和Web提供了三种对外服务。普通用户和管理员这两类请求通过两个不同的通信通道发送给RM,是因为要避免普通用户请求过多导致管理员请求被阻塞而迟迟得不到处理。
2.2 NodeManager 管理模块
NodeManagerLivelinessMonitor
监控NodeManager是否活着,如果一个NodeManager在一定时间内(10min)未回报心跳信息,则认为它死掉了,需将其从集群中移除。
NodeListManager
管理exclude和include节点列表,维护正常节点和异常节点列表。
ResourceTrackerService
处理来自NodeManager的请求,主要包括注册和心跳两种请求。注册是NodeManager启动时发生的行为,请求包中包含节点的ID、可用资源的上限等信息;心跳是周期性的行为,包含各个Container运行状态,运行的Application列表、节点健康状况等信息,作为请求的应答,ResourceTrackService可为NM返回释放Container列表、Application列表等信息。
2.3 ApplicationMaster 管理模块
AMLivelinessMonitor
监控ApplicationMaster是否还活着,如果一个ApplicationMaster在一定时间(10min)内未汇报心跳信息,则认为它死掉了,它上面的所有正在运行的Container将被设置为失败状态,而ApplicationMaster本身会被重新分配到另一个节点上(默认尝试运行2次)。
ApplicationMasterLaucher
与某个NM 通信,要求它为某个应用程序启动ApplicationMaster。
ApplicationMasterService
负责处理来自ApplictionMaster的请求,请求主要包括注册、心跳和清理三种。
注册是AM 启动时发生的行为,注册请求包中包含AM启动节点,对外的RPC端口号和tracking URL等信息。
心跳是周期性的行为,汇报信息包括所需资源的描述、待释放的Container列表、黑名单列表,ApplicationMasterService则为之返回新分配的Container、失败的Container、待抢占的Container列表等信息。
清理是应用程序结束时发生的。ApplicationMaster向RM发送清理应用程序的请求,以回收资源和清理各种内存空间。
2.4 Applicatin 管理模块
ApplicationACLsManager
负责管理应用程序的访问权限,包含两部分权限:查看权限和修改权限。查看权限主要用于查看应用程序基本信息,而修改权限则主要用于修改应用程序的优先级、杀死应用程序等。
RMAppManager
负责管理应用程序的启动和关闭。ClientRMService收到来自客户端的提交应用程序的请求后,将调用函数RMAppManager#submitAppication创建一个RMApp对象,它将维护整个应用程序生命周期,从开始运行到最终结束。
注:RM不负责ApplicationMaster内部任务的执行以及容错,只负责资源的分配和状态的跟踪。
ContainerAllocationExpirer
当一个ApplicationMaster获得一个Container后,YARN不允许ApplicationMaster长时间不对其使用,这样会降低整个集群的利用率。当ApplicationMaster收到RM新分配的一个Container后,必须再一定的时间内(默认为10min)内在对应的NM上启动该Container,否则RM将强制回收该Container,而一个已经分配的Container是否被回收则是由ContinerAllocationExpier决定和执行的。
2.5 状态机管理模块
负责维护应用程序的整个运行周期,包括维护同一个Application启动的所有运行实例的生命周期(RMApp)、维护一次运行尝试的整个生命周期(RMAppAttempt)、维护一个Contaner的运行周期(RMContainer)、维护一个NodeManager的生命周期(RMNode)。
注:1. RMContainer维护了一个Container的运行周期,包括从创建到运行的整个过程。RM将资源封装成Container发送给应用程序的ApplicationMaster,而ApplicationMaster则会在Container描述的环境中启动任务,因此,从这个层面上讲,Container和任务的生命周期是一致的(目前YARN不支持Container的重用,一个Container用完后会立刻释放,将来可能会增加Container的重用机制)。
2. RMNode状态机是ResourceManager中用于维护一个节点生命周期的数据结构,它的实际是RMNodeImple类,该类维护了一个节点状态机,记录了节点可能存在的各个状态。例如,当一个应用程序执行完成时候,会触发一个CLEANUP_APP事件,以清理应用程序占用的资源。当一个Container执行完成时候,会触发一个CLEANUP_CONTAINER事件,以清理Container占用的资源。
3.在YARN中,根据应用程序需求,资源被切分成大小不同的资源块,每份资源的基本信息由Container描述,而具体的使用状态追踪则是由RMContainer完成。RMContainer是ResoueceManager中用于维护一个Container生命周期的数据结构,它的实现是RMContianerImpl类,该类维护了一个Container状态机,记录了一个Container可能存在的各个状态以及导致状态转换的事件,当某个事件发生的时候,RMContainerImpl会根据实际情况进行Container状态的转移,同时触发一个行为。
4. ApplicationMaster通过RPC函数ApplicationMasterProtocol#allocate拉取分配给它的Container后,将与对应的NodeManager通信以启动这些Container,接着NodeManager通过心跳机制将这些Container状态汇报给ResourceManager,最终ResourceManager将这些Container状态置为RUNNING.
5.当出现以下几种情况时,将导致Container置为KILLED状态。
a.资源调度器为了保持公平性或者更高优先级的应用程序的服务质量,不得不杀死一些应用占用的Container以满足另外一些应用程序的请求。
b.某个NodeManager在一定时间内未向ResourceManager汇报心跳信息,则ResourceManager认为它死掉了,会将它上面所在正在运行的Container状态设置为KILLED。
c.用户(使用API 或者 Shell命令)强制杀死一个RMAppAttempImpl实现时,会导致它所用的Container状态设置为KILLED。
2.6 安全管理模块
YARN自带了非常全面的权限管理机制,一般而言,系统安全机制由认证和授权两大部分组成。认证就是简单的对一个实体的身份进行判断;授权则是向实体授予对数据资源和信息访问权限的决策过程。
Hadoop认证机制的实现同时采用了Kerberos和Token两种技术,其中Kerberos用于用户与服务与服务之间的认证,他是一种基于可信任的第三方服务的认证机制,在高并发情况下,效率低。
2.7 资源分配模块
ResourceScheduler是资源调度器,它按照一定的约束条件(比如队列容量限制等)将集群中的资源分配给各个应用程序,当前主要考虑内存和CPU资源。ResourceScheduler是一个插拔式模块,YARN自带了一个批处理资源管理器-FIFO和两个多用户调度器--Fair Scheduler和Capacity Scheduler。
三 常见行为分析
3.1 ApplicationMaster 超时
AM向RM注册后,必须周期性通过RPC函数ApplicationMasterProtocol#allocate向ResrouceManager汇报心跳以表明自己还活着。如果一段时间按(默认是10min)内未汇报心跳,则ResourceMananger宣布它死亡,进而导致应用程序重新运行或者直接退出。
3.2 NodeManager 超时
NodeManger启动后通过RPC函数ResourceTracker#registerNodeManager向RM注册,之后将被加入到NMLivenessMonitor中进行监控。它必须周期性通过RPC函数ResourceTracker#nodeHeartBeat向RM汇报心跳以表明自己还活着,如果一段时间内(默认是10min)内为汇报心跳,则RM宣布它已经死亡,所以正在运行在它上面的Container将被回收。
3.3 Container 超时
在YARN中,存在两种类型的Container,分别是用于运行ApplicationMaster的Container(AM Container)和运行普通任务的Container(简称为 "普通Container")。第一种Container超时将导致整个Application运行失败,而第二种Container超时则会触发一次资源回收。而要注意的是,第二种Container超时导致任务运行失败后,YARN不会主动将其调度到另一个节点上运行,而是将状态告诉应用程序的ApplicationMaster,由它决定是否重新申请资源或者重新执行。
注:RM只负责资源的分配和回收以及应用程序状态的维护,它不会负责当任务失败的时候进行重启Container,即不负责容错处理。
3.4 AM超时
RMAppImpl收到超时事件后,如果未超过用户设置的运行次数上限,将尝试启动一个新的RMAppAttemptImp或者直接宣布该应用程序运行失败;ResourceScheduler收到事件后,会清理该应用相关信息。
四 高可用
Hadoop1.0中,HDFS和MapReduce均采用了Master/Slave结构,这种结构虽然具有设计非常简单的有点,但同时也存在Master单点故障问题。由于存在单点故障问题的系统不适合在线应用场景,这使得Hadoop在相当长时间内仅用于离线存储和计算。
在Hadoop2.0中,HDFS同样面临着单点故障问题,但由于每个MapReduce作业拥有自己的作业管理组件,因此不再存在单点故障问题,新引入的资源管理系统YARN也采用了Master/Slave结构 ,同样出现了单点故障问题。
在 Master/Slave架构中,为了解决Master的单点故障问题(也成为高可用问题,即HA,High Availability),通常采用
热备方案,即集群中存在一个对外服务的Active Master和若干个处于就绪状态的Standy Master,一旦Active Master出现故
障,立即采用一定的侧率选取某个Standy Master转换为Active Master以正常对外提供服务。
HDFS 和 YARN均采用了基于共享存储的HA 解决方案,即Active Master不断将信息写入一个共享存储系统,而Standy Master则不断读取这些信息,以与Active Master的内存信息保持同步。当需要主备切换时,选中Standby Master需先保证信息完全同步后,再将自己的角色切换至Active Master。
Zookeeper是一个针对大型文件分布式系统的可靠协调系统,提供的功能包括统一命名服务、配置管理、集群管理、共享锁和队列管理等。需要注意的是Zookeeper设计目的并不是数据存储,但它的确可以安全可靠地存储少量数据以解决分布式环境下多个服务之间的数据共享服务。
五 小结
在YARN中,ResourceManager扮演管理者角色,它负责整个集群的管理与调度。ResourceManager内部有多个功能管理模块,主要包括:ApplicatoinMaster管理(启动和停止)、NodeManager管理、Application管理、状态机管理等。














 1323
1323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









