







阅读文档\linux-2.6.35\Documentation\x86\boot.txt
传统支持Image和zImage内核的启动装载内存布局(2.4以前的内核装载就是这样的布局):
| |
0A0000 +------------------------+
| Reserved for BIOS | Do not use. Reserved for BIOS EBDA.
09A000 +------------------------+
| Command line |
| Stack/heap | For use by the kernel real-mode code.
098000 +------------------------+
| Kernel setup | The kernel real-mode code.
090200 +------------------------+
| Kernel boot sector | The kernel legacy boot sector.
090000 +------------------------+
| Protected-mode kernel | The bulk of the kernel image.
010000 +------------------------+
| Boot loader | <- Boot sector entry point 0000:7C00
001000 +------------------------+
| Reserved for MBR/BIOS |
000800 +------------------------+
| Typically used by MBR |
000600 +------------------------+
| BIOS use only |
000000 +------------------------+
当使用bzImage时,保护模式的内核会被重定位到0x1000000(高端内存),内核实模式的代码(boot sector,setup和stack/heap)会被编译成可重定位到0x100000与低端内存底端之间的任何地址处。不幸的是,在2.00和2.01版的引导协议中,0x90000+的内存区域仍然被使用在内核的内部。2.02版的引导协议解决了这个问题。boot loader应该使BIOS的12h中断调用来检查低端内存中还有多少内存可用。
人们都希望“内存上限”,即boot loader触及的低端内存最高处的指针,尽可能地低,因为一些新的BIOS开始分配一些相当大的内存,所谓的扩展BIOS数据域,几乎快接近低端内存的最高处了。
不幸的是,如果BIOS 12h中断报告说内存的数量太小了,则boot loader除了报告一个错误给用户外,什么也不会做。因此,boot loader应该被设计成占用尽可能少的低端内存。对zImage和以前的bzImage,这要求数据能被写到x090000段,boot loader应该确保不会使用0x9A000指针以上的内存;很多BIOS在这个指针以上会终止。
对一个引导协议>=2.02的现代bzImage内核,其内存布局使用以下格式:
| Protected-mode kernel |
100000 +------------------------+
| I/O memory hole |
0A0000 +------------------------+
| Reserved for BIOS | Leave as much as possible unused
~ ~
| Command line | (Can also be below the X+10000 mark)
X+10000 +------------------------+
| Stack/heap | For use by the kernel real-mode code.
X+08000 +------------------------+
| Kernel setup | The kernel real-mode code.
| Kernel boot sector | The kernel legacy boot sector.
X +------------------------+
| Boot loader | <- Boot sector entry point 0000:7C00
001000 +------------------------+
| Reserved for MBR/BIOS |
000800 +------------------------+
| Typically used by MBR |
000600 +------------------------+
| BIOS use only |
000000 +------------------------+
这里程序段地址是由grub的大小来决定的。地址X应该在bootloader所允许的范围内尽可能地低。
2、BIOS POST过程
传统意义上,由于CPU加电之后,CPU只能访问ROM或者RAM里的数据,而这个时候是没有计算机操作系统的,所以需要有一段程序能够完成加载存储在非易失性存储介质(比如硬盘)上的操作系统到RAM中的功能。这段程序存储在ROM里,BIOS就是这类程序中的一种。对于BIOS,主要由两家制造商制造,驻留在主板的ROM里。有了BIOS,硬件制造商可以只需要关注硬件而不需要关注软件。BIOS的服务程序,是通过调用中断服务程序来实现的。BIOS加载bootloader程序,Bootloader也可以通过BIOS提供的中断,向BIOS获取系统的信息。整个过程如下:
(1)电源启动时钟发生器并在总线上产生一个#POWERGOOD的中断。
(2)产生CPU的RESET中断(此时CPU处于8086工作模式)。
(3)进入BIOS POST代码处:%ds=%es=%fs=%gs=%ss=0,%cs=0xFFFF0000,%eip = 0x0000FFF0 (ROM BIOS POST code,指令指针eip,数据段寄存器ds,代码段寄存器cs)。
(4)在中断无效状态下执行所有POST检查。
(5)在地址0初始化中断向量表IVT。
(6)0x19中断:以启动设备号为参数调用BIOS启动装载程序。这个程序从启动设备(硬盘)的0扇面1扇区读取数据到内存物理地址0x7C00处开始装载。这个0扇面1扇区称为Boot sector(引导扇区),共512字节,也称为MBR。
就是说,CPU 在 BIOS 的入口(CS:IP=FFFF:0000)处执行BIOS的汇编程序,BIOS程序功能有系统硬件的检测,提供中断访问接口以访问硬件。而后被BIOS程序通过中断0x19调用磁盘MBR上的bootloader程序,将bootloader程序加载到ox7c00处,而后跳转到0x7c00,这样,位于 0x7c00处的bootloader程序,就可以执行了。
从BIOS执行MBR中的bootloader程序开始,就是linux的代码在做的事情了。
3、Bootloader过程
bootloader程序是为计算机加载(load)计算机操作系统的。boot(引导)是bootstrap的简写,bootstrap是引导指令的意思。bootloader程序通常位于硬盘上,被BIOS调用,用于加载内核。在PC机上常见的bootloader主要有grub、lilo、syslinux等。
GRUB(GRand Unified Bootloader)是当前linux诸多发行版本默认的引导程序。嵌入式系统上,最常见的bootloader是U-BOOT。这样的bootloader一般位于MBR的最前部。在linux系统中,bootloader也可以写入文件系统所在分区中。比如,grub程序就非常强大。Gurb运行后,将初始化设置内核运行所需的环境。然后加载内核镜像。
grub磁盘引导全过程:
(1)stage1: grub读取磁盘第一个512字节(硬盘的0道0面1扇区,被称为MBR(主引导记录),也称为bootsect)。MBR由一部分bootloader的引导代码、分区表和魔数三部分组成。
(2)stage1_5: 识别各种不同的文件系统格式。这使得grub识别到文件系统。
(3)stage2: 加载系统引导菜单(/boot/grub/menu.lst或grub.lst),加载内核vmlinuz和RAM磁盘initrd。
4、内核启动过程
内核映像文件vmlinuz:包含有linux内核的静态链接的可执行文件,传统上,vmlinux被称为可引导的内核镜像。vmlinuz是vmlinux的压缩文件。其构成如下:
(1)第一个512字节(以前是在arch/i386/boot/bootsect.S);
(2)第二个,一段代码,若干个不多于512字节的段(以前是在arch/i386/boot/setup.S);
(3)保护模式下的内核代码(在arch/x86/boot/main.c)。
bzImage文件:使用make bzImage命令编译内核源代码,可以得到采用zlib算法压缩的zImage文件,即big zImage文件。老的zImage解压缩内核到低端内存,bzImage则解压缩内核到高端内存(1M(0x100000)以上),在保护模式下执行。bzImage文件一般包含有vmlinuz、bootsect.o、setup.o、解压缩程序misc.o、以及其他一些相关文件(如piggy.o)。注意,在Linux 2.6内核中,bootsect.S和setup.S被整合为header.S。
initramfs(或initrd)文件:initrd是initialized ram disk的意思。主要用于加载硬件驱动模块,辅助内核的启动,挂载真正的根文件系统。
例如,我电脑上的grub启动项如下(在/boot/grub/grub.lst中):
title Fedora (2.6.35.10-74.fc14.i686)
root (hd0,0)
kernel /vmlinuz-2.6.35.10-74.fc14.i686 ro root=/dev/mapper/VolGroup-lv_root rd_LVM_LV=VolGroup/lv_root rd_LVM_LV=VolGroup/lv_swap rd_NO_LUKS rd_NO_MD rd_NO_DM LANG=zh_CN.UTF-8 KEYBOARDTYPE=pc KEYTABLE=us rhgb quiet
initrd /initramfs-2.6.35.10-74.fc14.i686.img启动过程是和体系结构相关的,对于2.6内核,x86体系结构,CPU在上电初始化时,指令寄存器CS:EIP总是被初始化为固定值,这就是CPU复位后的第一条指令的地址。对于32位地址总线的系统来说,4GB的物理空间至少被划分为两个部分,一部分是内存的地址空间,另外一部分地址空间用于对BIOS芯片存储单元进行寻址。x86复位后工作在实模式下,该模式下CPU的寻址空间为1MB。CS:IP的复位值是FFFF:0000,物理地址为FFFF0。主板设计者必须保证把这个物理地址映射到BIOS芯片上,而不是RAM上。
装载Linux内核的第一步应该是加载实模式代码(boot sector和setup代码),然后检查偏移0x01f1处的头部(header)中的各个参数值。实模式的代码总共有32K,但是boot loader可以选择只装载前面的两个扇区(1K),然后检查bootup扇区的大小。
header中各个域的格式如下:
Offset/Size Proto Name Meaning
01F1/1 ALL(1 setup_sects The size of the setup in sectors
01F2/2 ALL root_flags If set, the root is mounted readonly
01F4/4 2.04+ syssize The size of the 32-bit code in 16-byte paras
01F8/2 ALL ram_size DO NOT USE - for bootsect.S use only
01FA/2 ALL vid_mode Video mode control
01FC/2 ALL root_dev Default root device number
01FE/2 ALL boot_flag 0xAA55 magic number
0200/2 2.00+ jump Jump instruction
0202/4 2.00+ header Magic signature "HdrS"
0206/2 2.00+ version Boot protocol version supported
0208/4 2.00+ realmode_swtch Boot loader hook (see below)
020C/2 2.00+ start_sys_seg The load-low segment (0x1000) (obsolete)
020E/2 2.00+ kernel_version Pointer to kernel version string
0210/1 2.00+ type_of_loader Boot loader identifier
0211/1 2.00+ loadflags Boot protocol option flags
0212/2 2.00+ setup_move_size Move to high memory size (used with hooks)
0214/4 2.00+ code32_start Boot loader hook (see below)
0218/4 2.00+ ramdisk_image initrd load address (set by boot loader)
021C/4 2.00+ ramdisk_size initrd size (set by boot loader)
0220/4 2.00+ bootsect_kludge DO NOT USE - for bootsect.S use only
0224/2 2.01+ heap_end_ptr Free memory after setup end
0226/1 2.02+ ext_loader_ver Extended boot loader version
0227/1 2.02+ ext_loader_type Extended boot loader ID
0228/4 2.02+ cmd_line_ptr 32-bit pointer to the kernel command line
022C/4 2.03+ ramdisk_max Highest legal initrd address
0230/4 2.05+ kernel_alignment Physical addr alignment required for kernel
0234/1 2.05+ relocatable_kernel Whether kernel is relocatable or not
0235/1 2.10+ min_alignment Minimum alignment, as a power of two
0236/2 N/A pad3 Unused
0238/4 2.06+ cmdline_size Maximum size of the kernel command line
023C/4 2.07+ hardware_subarch Hardware subarchitecture
0240/8 2.07+ hardware_subarch_data Subarchitecture-specific data
0248/4 2.08+ payload_offset Offset of kernel payload
024C/4 2.08+ payload_length Length of kernel payload
0250/8 2.09+ setup_data 64-bit physical pointer to linked list of struct setup_data
0258/8 2.10+ pref_address Preferred loading address
0260/4 2.10+ init_size Linear memory required during initializationBIOS把Boot Loader加载到0x7C00的地方并跳转到这里继续执行之后,BootLoader就会把实模式代码setup加载到0x07C00之上的某个地址上,其中setup的前512个字节是boot sector(引导扇区),现在这个引导扇区的作用并不是用来引导系统,而是为了兼容及传递一些参数。之后Boot Loader跳转到setup的入口点,入口点为_start例程(根据arch/x86/boot/setup.ld可知)。
注意,bzImage由setup和vmlinux两部分组成,setup是实模式下的代码,vmlinux是保护模式下的代码。
实模式设置(setup)阶段用于体系结构相关的硬件初始化工作,涉及的文件有arch/x86/boot/header.S、链接脚本setup.ld、arch/x86/boot/main.c。header.S第一部分定义了bstext、.bsdata、.header这3个节,共同构成了vmlinuz的第一个512字节(即引导扇区的内容)。常量BOOTSEG和SYSSEG定义了引导扇区和内核的载入地址。下面是header.S的代码:
BOOTSEG = 0x07C0 /* 引导扇区的原始地址 */
SYSSEG = 0x1000 /* 历史的载入地址>>4 */
#ifndef SVGA_MODE
#define SVGA_MODE ASK_VGA
#endif
#ifndef RAMDISK
#define RAMDISK 0
#endif
#ifndef ROOT_RDONLY
#define ROOT_RDONLY 1
#endif
.code16
.section ".bstext", "ax"
.global bootsect_start
bootsect_start:
# 使开始地址正常化
ljmp $BOOTSEG, $start2
start2:
movw %cs, %ax
movw %ax, %ds
movw %ax, %es
movw %ax, %ss
xorw %sp, %sp
sti
cld
movw $bugger_off_msg, %si
msg_loop:
lodsb
andb %al, %al
jz bs_die
movb $0xe, %ah
movw $7, %bx
int $0x10
jmp msg_loop
bs_die:
# 允许用户按一个键,然后重启
xorw %ax, %ax
int $0x16
int $0x19
# 0x19中断绝不会返回,无论它做什么
# 调用BIOS复位代码,便CPU工作在实模式下
ljmp $0xf000,$0xfff0
.section ".bsdata", "a"
bugger_off_msg:
.ascii "Direct booting from floppy is no longer supported.\r\n"
.ascii "Please use a boot loader program instead.\r\n"
.ascii "\n"
.ascii "Remove disk and press any key to reboot . . .\r\n"
.byte 0
# 下面设置内核的一些属性,setup需要。这是header的第一部分,来自以前的boot sector
.section ".header", "a"
.globl hdr
hdr:
setup_sects: .byte 0 /* 被build.c填充 */
root_flags: .word ROOT_RDONLY
syssize: .long 0 /* 被build.c填充 */
ram_size: .word 0 /* 已过时 */
vid_mode: .word SVGA_MODE
root_dev: .word 0 /* 被build.c填充 */
boot_flag: .word 0xAA55
# 偏移512处,setup的入口点
.globl _start
_start:
# Explicitly enter this as bytes, or the assembler
# tries to generate a 3-byte jump here, which causes
# everything else to push off to the wrong offset.
.byte 0xeb # short (2-byte) jump
.byte start_of_setup-1f
1:
# header的第二部分,来自以前的setup.S:设置头部header,包括大量的bootloader参数,如header版本、内核版本字符串指针、bootloader类型、
# 内核装载时的很多标志、堆栈尾部地址指针、内核命令行地址指针和大小、32位保护模式入口地址、ramdisk地址和大小等
code32_start: # 这里对32位的代码,装载器可以设置可设置一个不同的入口地址
.long 0x100000 # 0x100000 = 为大内核的默认入口地址(保护模式)
# ............ (省略)
# End of setup header #####################################################
.section ".entrytext", "ax"
start_of_setup:
#ifdef SAFE_RESET_DISK_CONTROLLER
# 重置磁盘控制器
movw $0x0000, %ax # 重置磁盘控制器
movb $0x80, %dl # 所有的的磁盘控制器All disks
int $0x13
#endif
# ............(省略)
# 让%ss无效,创建一个新的栈
movw $_end, %dx
testb $CAN_USE_HEAP, loadflags
jz 1f
movw heap_end_ptr, %dx
1: addw $STACK_SIZE, %dx
jnc 2f
xorw %dx, %dx # Prevent wraparound
2: # 现在%dx应该指向我们栈空间的尾部
andw $~3, %dx # dword对齐
jnz 3f
movw $0xfffc, %dx # 确保不是0
3: movw %ax, %ss
movzwl %dx, %esp # 清除%esp的上半部分
sti # 现在我们应该有一个工作空间
# 我们将进入%cs=%ds+0x20,设置好%cs
pushw %ds
pushw $6f
lretw
6:
# 在setup终止时检查签名
cmpl $0x5a5aaa55, setup_sig
jne setup_bad
# 对BSS(Block Started by Symbol)清零
movw $__bss_start, %di
movw $_end+3, %cx
xorl %eax, %eax
subw %di, %cx
shrw $2, %cx
rep; stosl
# 跳转到C代码(不会返回)
calll main
# ............(省略)实模式的protected_mode_jump执行后,跳出了bzImage的第一部分,BootLoader默认把第二部分放在0x100000处,这个入口处是startup_32,先执行arch/x86/boot/compressed/head_32.S中的startup_32(保护模式下的入口函数),然后执行arch/x86/kernel/head_32.S中的startup_32(32位内核的入口函数),这里会拷贝boot_params以及boot_command_line, 初始化页表,开启分页机制。
startup_32()函数会调用head32.c:i386_start_kernel()函数,它会调用init/main.c:start_kernel()函数,这是Linux内核的启动函数。init/main.c文件是整个Linux内核的中央联结点。每种体系结构都会执行一些底层设置函数,然后执行名为start_kernel的函数(在init/main.c中可以找到这个函数)。可以认为main.c是内核的“粘合剂(glue)”,之前执行的代码都是各种体系结构相关的代码,一旦到达start_kernel(),就与体系结构无关了。
start_kernel()会调用一系列初始化函数来设置中断,执行进一步的内存配置,解析内核命令行参数。然后调用fs/dcache.c:vfs_caches_init()--->fs/namespace.c:mnt_init()创建基于内存的rootfs文件系统(是一个虚拟的内存文件系统,称为VFS),这是系统初始化时的根结点,即"/"结点,后面VFS会指向真实的文件系统。注意在Linux系统中,目录结构与Windows上有较大的不同。系统中只有一个根目录,路径是“/”,而其它的分区只是挂载在根目录中的一个文件夹内,如“/proc”和“/sys”等,这里的“/”就是Linux中的根目录。
下面是mnt_init()的代码:
void __init mnt_init(void)
{
unsigned u;
int err;
init_rwsem(&namespace_sem);
mnt_cache = kmem_cache_create("mnt_cache", sizeof(struct vfsmount),
0, SLAB_HWCACHE_ALIGN | SLAB_PANIC, NULL);
mount_hashtable = (struct list_head *)__get_free_page(GFP_ATOMIC);
if (!mount_hashtable)
panic("Failed to allocate mount hash table\n");
printk("Mount-cache hash table entries: %lu\n", HASH_SIZE);
for (u = 0; u < HASH_SIZE; u++)
INIT_LIST_HEAD(&mount_hashtable[u]);
err = sysfs_init();
if (err)
printk(KERN_WARNING "%s: sysfs_init error: %d\n",
__func__, err);
fs_kobj = kobject_create_and_add("fs", NULL);
if (!fs_kobj)
printk(KERN_WARNING "%s: kobj create error\n", __func__);
init_rootfs();
init_mount_tree();
}为什么不直接把真实的文件系统配置为根文件系统?答案很简单,内核中没有真实根文件系统设备(如硬盘,USB)的驱动,而且即便你将根文件系统的设备驱动编译到内核中,此时它们还尚未加载,实际上所有内核中的驱动是由后面的kernel_init线程进行加载。另外,我们的root设备都是以设备文件的方式指定的,如果没有根文件系统,设备文件怎么可能存在呢?
注意根据调用链do_kern_mount()--->vfs_kern_mount(type)--->type->get_sb()--->fs/ramfs/inode.c:rootfs_get_sb()--->ramfs_fill_super()--->fs/dcache.c:d_alloc_root(),函数d_alloc_root分配最终的根结点,代码如下:
struct dentry * d_alloc_root(struct inode * root_inode)
{
struct dentry *res = NULL;
if (root_inode) {
static const struct qstr name = { .name = "/", .len = 1 };
res = d_alloc(NULL, &name);
if (res) {
res->d_sb = root_inode->i_sb;
res->d_parent = res;
d_instantiate(res, root_inode);
}
}
return res;
}start_kernel()在最后会调用rest_init(),这个函数会启动一个内核线程来运行kernel_init(),自己则调用cpu_idle()进入空闲循环,让调度器接管控制权。抢占式的调度器就可以周期性地接管控制权,从而提供多任务处理能力。
kernel_init()用于完成初始化rootfs、加载内核模块、挂载真正的根文件系统。根据Documentation/early-userspace/README的描述,目前2.6的kernel支持三方式来挂载最终的根文件系统:
(1)所有需要的设备和文件系统驱动被编译进内核,没有initrd。通过“root="参数指定的根设备,init/main.c:kernel_init()将调用prepare_namespace()直接在指定的根设备上挂载最终的根文件系统。通过可选的"init="选项,还可以运行用户指定的init程序。
(2)一些设备和文件驱动作为模块来构建并存放的initrd中。initrd被称为ramdisk,是一个独立的小型文件系统。它需要包含/linuxrc程序(或脚本),用于加载这些驱动模块,并挂载最终的根文件系统(结合使用pivot_root系统调用),然后initrd被卸载。initrd由prepare_namespace()挂载和运行。内核必须要使用CONFIG_BLK_DEV_RAM(支持ramdisk)和CONFIG_BLK_DEV_INITRD(支持initrd)选项进行编译才能支持initrd。
initrd文件通过在grub引导时用initrd命令指定。它有两种格式,一种是类似于linux2.4内核使用的传统格式的文件系统镜像,称之为image-initrd,它的制作方法同Linux2.4内核的initrd一样,其核心文件就是 /linuxrc。另外一种格式的initrd是cpio格式的,这种格式的initrd从linux 2.5起开始引入,使用cpio工具生成,其核心文件不再是/linuxrc,而是/init,这种 initrd称为cpio-initrd。为了向后兼容,linux2.6内核对cpio-initrd和image-initrd这两种格式的initrd 均支持,但对其处理流程有着显著的区别。cpio-initrd的处理与initramfs类似,会直接跳过prepare_namespace(),image-initrd的处理则由prepare_namespace()进行。
(3)使用initramfs。prepare_namespace()调用会被跳过。这意味着必须有一个程序来完成这些工作。这个程序是通过修改usr/gen_init_cpio.c的方式,或通过新的initrd格式(一个cpio归档文件)存放在initramfs中的,它必须是"/init"。这个程序负责prepare_namespace()所做的所有工作。为了保持向后兼容,在现在的内核中,/init程序只有是来自cpio归档的情况才会被运行。如果不是来自cpio归档,init/main.c:kernel_init()将运行prepare_namespace()来挂载最终的根文件系统,并运行一个预先定义的init程序(或者是用户通过init=指定的,或者是/sbin/init,/etc/init,/bin/init)。
initramfs是从2.5 kernel开始引入的一种新的实现机制。顾名思义,initramfs只是一种RAM filesystem而不是disk。initramfs实际是一个包含在内核映像内部的cpio归档,启动所需的用户程序和驱动模块被归档成一个文件。因此,不需要cache,也不需要文件系统。 编译2.6版本的linux内核时,编译系统总会创建initramfs,然后通过连接脚本arch\x86\kernel\vmlinux.lds.S把它与编译好的内核连接成一个文件,它被链接到地址__initramfs_start~__initramfs_end处。内核源代码树中的usr目录就是专门用于构建内核中的initramfs的。缺省情况下,initramfs是空的,X86架构下的文件大小是134个字节。实际上它的含义就是:在内核镜像中附加一个cpio包,这个cpio包中包含了一个小型的文件系统,当内核启动时,内核将这个cpio包解开,并且将其中包含的文件系统释放到rootfs中,内核中的一部分初始化代码会放到这个文件系统中,作为用户层进程来执行。这样带来的明显的好处是精简了内核的初始化代码,而且使得内核的初始化过程更容易定制。
注意initramfs和initrd都可以是cpio包,可以压缩也可以不压缩。但initramfs是包含在内核映像中的,作为内核的一部分存在,因此它不会由bootloader(如grub)单独地加载,而initrd是另外单独编译生成的,是一个独立的文件,会由bootloader单独加载到RAM中内核空间以外的地址处。目前initramfs只支持cpio包格式,它会被populate_rootfs--->unpack_to_rootfs(&__initramfs_start, &__initramfs_end - &__initramfs_start, 0)函数解压、解析并拷贝到根目录。initramfs被解析处理后原始的cpio包(压缩或非压缩)所占的空间(&__initramfs_start - &__initramfs_end)是作为系统的一部分直接保留在系统中,不会被释放掉。而对于initrd镜像文件,如果没有在命令行中设置"keepinitd"命令,那么initrd镜像文件被处理后其原始文件所占的空间(initrd_end - initrd_start)将被释放掉。
下面看kernel_init的代码:
static int __init kernel_init(void * unused)
{
/* ......(省略) */
do_basic_setup();
/* Open the /dev/console on the rootfs, this should never fail */
if (sys_open((const char __user *) "/dev/console", O_RDWR, 0) < 0)
printk(KERN_WARNING "Warning: unable to open an initial console.\n");
(void) sys_dup(0);
(void) sys_dup(0);
/*
* check if there is an early userspace init. If yes, let it do all
* the work
*/
if (!ramdisk_execute_command)
ramdisk_execute_command = "/init";
if (sys_access((const char __user *) ramdisk_execute_command, 0) != 0) {
ramdisk_execute_command = NULL;
prepare_namespace();
}
/*
* Ok, we have completed the initial bootup, and
* we're essentially up and running. Get rid of the
* initmem segments and start the user-mode stuff..
*/
init_post();
return 0;
}static void __init do_basic_setup(void)
{
init_workqueues();
cpuset_init_smp();
usermodehelper_init();
init_tmpfs();
driver_init();
init_irq_proc();
do_ctors();
do_initcalls();
}
do_initcalls()用来启动所有在__initcall_start和__initcall_end段之间的函数,而静态编译进内核的模块会将其初始化函数放置在这段区间里。其中与rootfs相关的初始化函数都会由rootfs_initcall()所引用。在init/initramfs.c中就有rootfs_initcall(populate_rootfs)的引用,这是用来初始化rootfs的,因此do_initcall()最终会调用到populate_rootfs()。需要特别指出的是initramfs.c模块的入口函数populate_rootfs()是否执行取决于Kernel的编译选项,参考init/Makefile,内核编译时必须配置CONFIG_BLK_DEV_INITRD选项才会执行这个函数。代码如下:
static int __init populate_rootfs(void)
{
char *err = unpack_to_rootfs(__initramfs_start,
__initramfs_end - __initramfs_start);
if (err)
panic(err); /* Failed to decompress INTERNAL initramfs */
if (initrd_start) {
#ifdef CONFIG_BLK_DEV_RAM
int fd;
printk(KERN_INFO "Trying to unpack rootfs image as initramfs...\n");
err = unpack_to_rootfs((char *)initrd_start,
initrd_end - initrd_start);
if (!err) {
free_initrd();
return 0;
} else {
clean_rootfs();
unpack_to_rootfs(__initramfs_start,
__initramfs_end - __initramfs_start);
}
printk(KERN_INFO "rootfs image is not initramfs (%s)"
"; looks like an initrd\n", err);
fd = sys_open("/initrd.image", O_WRONLY|O_CREAT, 0700);
if (fd >= 0) {
sys_write(fd, (char *)initrd_start,
initrd_end - initrd_start);
sys_close(fd);
free_initrd();
}
#else
printk(KERN_INFO "Unpacking initramfs...\n");
err = unpack_to_rootfs((char *)initrd_start,
initrd_end - initrd_start);
if (err)
printk(KERN_EMERG "Initramfs unpacking failed: %s\n", err);
free_initrd();
#endif
}
return 0;
}(2)if(initrd_start)判断是否加载了initrd。无论哪种格式的initrd,都会被boot loader加载到地址initrd_start处。当然,如果是initramfs的情况下,该值肯定为空了。
(3)第二个unpack_to_rootfs()把cpio-initrd镜像释放到rootfs,以此作为initramfs。这其中有/init脚本程序。
(4)如果不是cpio-initrd,则认为是一个image-initrd,将其内容保存到/initrd.image中。image-initrd由prepare_namespace()函数来处理。传统的image-initrd中使用/linuxrc脚本程序进行初始化。
回到kernel_init,接下来的工作是打开控制台设备/dev/console并设为标准输入,有了这个设备,启动信息才能显示到终端上。后续的两个sys_dup(0)是复制标准输入为标准输出和标准错误输出。然后,如果rootfs中存在init文件(用户通过rdinit=指定,或者默认的/init,保存在ramdisk_execute_command中),说明是加载了initramfs(包括cpio-initrd的情形),直接跳过prepare_namespace(),转向init_post(),它会调用run_init_process(ramdisk_execute_command)运行这个/init文件,替换当前进程,这样内核的工作全部结束,后续的初始化和挂载真正根文件系统的工作都交给/init程序。读者可能会问如果加载了cpio-initrd, 那么真实文件系统中的init进程不是没有机会运行了吗?确实,如果加载了cpio-initrd,那么内核就不负责执行用户空间的init进程了,而是将这个执行任务交给了cpio-initrd的init进程。
如果rootfs中没有init文件,说明是image-initrd的情形,就会转入到prepare_namespace(),这个函数加载image-initrd,并运行它的/linuxrc文件。prepare_namespace()的代码如下:
void __init prepare_namespace(void)
{
int is_floppy;
if (root_delay) {
printk(KERN_INFO "Waiting %dsec before mounting root device...\n",
root_delay);
ssleep(root_delay);
}
/*
* wait for the known devices to complete their probing
*
* Note: this is a potential source of long boot delays.
* For example, it is not atypical to wait 5 seconds here
* for the touchpad of a laptop to initialize.
*/
wait_for_device_probe();
md_run_setup();
if (saved_root_name[0]) {
root_device_name = saved_root_name;
if (!strncmp(root_device_name, "mtd", 3) ||
!strncmp(root_device_name, "ubi", 3)) {
mount_block_root(root_device_name, root_mountflags);
goto out;
}
ROOT_DEV = name_to_dev_t(root_device_name);
if (strncmp(root_device_name, "/dev/", 5) == 0)
root_device_name += 5;
}
if (initrd_load())
goto out;
/* wait for any asynchronous scanning to complete */
if ((ROOT_DEV == 0) && root_wait) {
printk(KERN_INFO "Waiting for root device %s...\n",
saved_root_name);
while (driver_probe_done() != 0 ||
(ROOT_DEV = name_to_dev_t(saved_root_name)) == 0)
msleep(100);
async_synchronize_full();
}
is_floppy = MAJOR(ROOT_DEV) == FLOPPY_MAJOR;
if (is_floppy && rd_doload && rd_load_disk(0))
ROOT_DEV = Root_RAM0;
mount_root();
out:
devtmpfs_mount("dev");
sys_mount(".", "/", NULL, MS_MOVE, NULL);
sys_chroot(".");
}(2)wait_for_device_probe(),从字面的意思来看,这里也是来等待根文件系统所在的设备探测函数的完成。
(3)用户通过“root=”指定的根设备名会被保存在saved_root_name中,如果用户指定了以mtd开始的字串做为它的根设备。就会直接调用mount_block_root()去挂载它并goto到out。这个文件是mtdblock的设备文件。否则将设备结点文件转换为ROOT_DEV即设备节点号。然后,转向initrd_load(),去加载image-initrd,执行其中的/linuxrc,挂载最终和根文件系统。
(4)initrd_load()会把/dev/ram0作为默认的根设备并把image-initrd加载到这里。如果用户通过root=指定了实际根设备(不是/dev/ram0),则说明image-initrd只是作为临时的文件系统而存在,转向handle_initrd(),对image-initrd进行具体的处理。它执行其中的/linuxrc,挂载最终的根文件系统。
(5)如果用户没有指定根设备(或指定为默认的/dev/ram0),说明直接把image-initrd作为最终的真实文件系统(在无盘工作站和很多嵌入式Linux系统中,initrd通常作为永久的根文件系统而存在),prepare_namespace()会设置好ROOT_DEV为/dev/ram0,并调用mount_root()挂载这个image-initrd,作为最终的文件系统而存在。
(6)挂载完真正的根文件系统后,goto到out,将挂载点从当前目录移到"/",并把"/"作为系统的根目录,至此虚拟文件系统切换到了实际的根文件系统。
initrd_load()的代码如下:
int __init initrd_load(void)
{
if (mount_initrd) {
create_dev("/dev/ram", Root_RAM0);
/*
* Load the initrd data into /dev/ram0. Execute it as initrd
* unless /dev/ram0 is supposed to be our actual root device,
* in that case the ram disk is just set up here, and gets
* mounted in the normal path.
*/
if (rd_load_image("/initrd.image") && ROOT_DEV != Root_RAM0) {
sys_unlink("/initrd.image");
handle_initrd();
return 1;
}
}
sys_unlink("/initrd.image");
return 0;
}(2)创建一个Root_RAM0的设备节点/dev/ram,调用rd_load_image将image-initrd的数据加载到/dev/ram0。rd_load_image会打开/dev/ram0,先是用identify_ramdisk_image()识别image-initrd的文件系统类型,确定是romfs、squashfs、minix,还是ext2。然后用crd_load()为image-initrd分配空间、计算循环冗余校验码(CRC)、解压,并将其加载到内存中。
(3)判断ROOT_DEV!=Root_RAM0的含义是,如果你在grub或者lilo里配置的root=不指定为/dev/ram0,则转向handle_initrd(),由它来挂载实际的文件系统。例如我电脑上的Fedora启动指定root=/dev/mapper/VolGroup-lv_root,肯定就不是Root_RAM0了。如果没有指定根设备(或指定为默认的/dev/ram0),则会跳过handle_initrd(),直接返回到prepare_namespace()。
下面是handle_initrd()的代码:
static void __init handle_initrd(void)
{
int error;
int pid;
real_root_dev = new_encode_dev(ROOT_DEV);
create_dev("/dev/root.old", Root_RAM0);
/* mount initrd on rootfs' /root */
mount_block_root("/dev/root.old", root_mountflags & ~MS_RDONLY);
sys_mkdir("/old", 0700);
root_fd = sys_open("/", 0, 0);
old_fd = sys_open("/old", 0, 0);
/* move initrd over / and chdir/chroot in initrd root */
sys_chdir("/root");
sys_mount(".", "/", NULL, MS_MOVE, NULL);
sys_chroot(".");
/*
* In case that a resume from disk is carried out by linuxrc or one of
* its children, we need to tell the freezer not to wait for us.
*/
current->flags |= PF_FREEZER_SKIP;
pid = kernel_thread(do_linuxrc, "/linuxrc", SIGCHLD);
if (pid > 0)
while (pid != sys_wait4(-1, NULL, 0, NULL))
yield();
current->flags &= ~PF_FREEZER_SKIP;
/* move initrd to rootfs' /old */
sys_fchdir(old_fd);
sys_mount("/", ".", NULL, MS_MOVE, NULL);
/* switch root and cwd back to / of rootfs */
sys_fchdir(root_fd);
sys_chroot(".");
sys_close(old_fd);
sys_close(root_fd);
if (new_decode_dev(real_root_dev) == Root_RAM0) {
sys_chdir("/old");
return;
}
ROOT_DEV = new_decode_dev(real_root_dev);
mount_root();
printk(KERN_NOTICE "Trying to move old root to /initrd ... ");
error = sys_mount("/old", "/root/initrd", NULL, MS_MOVE, NULL);
if (!error)
printk("okay\n");
else {
int fd = sys_open("/dev/root.old", O_RDWR, 0);
if (error == -ENOENT)
printk("/initrd does not exist. Ignored.\n");
else
printk("failed\n");
printk(KERN_NOTICE "Unmounting old root\n");
sys_umount("/old", MNT_DETACH);
printk(KERN_NOTICE "Trying to free ramdisk memory ... ");
if (fd < 0) {
error = fd;
} else {
error = sys_ioctl(fd, BLKFLSBUF, 0);
sys_close(fd);
}
printk(!error ? "okay\n" : "failed\n");
}
}(2)调用mount_block_root将initrd挂载到rootfs的/root下,设备节点为/dev/root.old。提取rootfs的根目录描述符并将其保存到root_fd。它的作用就是为了在进入到initrd文件系统并处理完initrd之后,还能够返回rootfs。
(3)进入到/root中的initrd文件系统,调用kernel_thread(do_linuxrc, "/linuxrc", SIGCHLD)启动一个内核线程来运行/linuxrc文件,等待它完成的后续的初始化工作。
(4)把initrd文件系统移动到rootfs的/old下。然后通过root_fd重新进入到rootfs,如果real_root_dev在linuxrc中重新设成Root_RAM0,说明直接把image-initrd直接作为真正的根文件系统,initrd_load()返回1,而后prepare_namespace()直接goto到out,改变当前目录到initrd中,不作后续处理直接返回。
(5)如果使用用户指定的根设备,则调用mount_root将真正的文件系统挂载到VFS的/root目录下。通过调用链mount_root()--->mount_block_root()--->do_mount_root()--->sys_mount(name,"/root")可知,指定的根设备用设备节点/dev/root表示,挂载点为VFS的/root,并将当前目录切换到了这个挂载点下。
(6)如果真实文件系统中有/initrd目录,那么会把/old中的initrd移动到真实文件系统的/initrd下。如果没有/initrd目录,则用sys_umount()卸载initrd,并释放它的内存。
prepare_namspace执行完后,真正的文件系统就挂载成功。转入init_post(),它用来运行用户空间的第一个进程,即众所周知的init进程。代码如下:
static noinline int init_post(void)
__releases(kernel_lock)
{
/* ...... */
if (ramdisk_execute_command) {
run_init_process(ramdisk_execute_command);
printk(KERN_WARNING "Failed to execute %s\n",
ramdisk_execute_command);
}
if (execute_command) {
run_init_process(execute_command);
printk(KERN_WARNING "Failed to execute %s. Attempting "
"defaults...\n", execute_command);
}
run_init_process("/sbin/init");
run_init_process("/etc/init");
run_init_process("/bin/init");
run_init_process("/bin/sh");
panic("No init found. Try passing init= option to kernel. "
"See Linux Documentation/init.txt for guidance.");
}(1)noinitrd方式,则直接运行用户空间中的/sbin/init(或/etc/init,/bin/init),作为第一个用户进程。
(2)传统的image-initrd方式。运行的第一个程序是/linuxrc脚本,由它来启动用户空间中的init进程。
(3)cpio-initrd和initramfs方式。运行的第一个程序是/init脚本,由它来启动用户空间中的init进程。
我电脑上Fedora的/boot目录下有initramfs-2.6.35.10-74.fc14.i686.img,它就是启动Fedora时指定的cpio-initrd(经过了压缩,可以用file命令查看其文件类型)。先加上.gz后缀,用gunzip解压,然后用cpio -i --make-directories < initramfs-2.6.35.10-74.fc14.i686.img命令导出它的文件。我们可以看到根目录下有/init脚本,./bin目录中有一组很少但却非常必要的应用程序,包括dash(一个脚本解释器,比bash体积小速度快,兼容性高,以前的initrd用的是nash)、plymouth、sed等。./sbin下有dmraid、kpartx、loginit脚本、lvm(逻辑卷管理器)、modprobe、switch_root、udevd等核心程序。
/init设置$PATH环境变量,挂载procfs和sysfs、启动udev(动态设备管理进程,通过监视sysfs按照规则动态创建/dev目录中的设备,已经逐渐取代了hotplug和coldplug)、挂载真正的根文件系统、用switch_root切换到根分区并运行/sbin/init。
下面给出内核映像完整的启动过程:
arch/x86/boot/header.S:
--->header第一部分(以前的bootsector.S): 载入bootloader到0x7c00处,设置内核属性
--->_start() bzImage映像的入口点(实模式),header的第二部分(以前的setup.S)
--->code32_start=0x100000 0x100000为解压后的内核的载入地址(1M高端地址)
--->设置大量的bootloader参数、创建栈空间、检查签名、清空BSS
--->arch/x86/boot/main.c:main() 实模式内核的主函数
--->copy_boot_params() 把位于第一个扇区的参数复制到boot_params变量中,boot_params位于setup的数据段
--->检查内存布局、设置键盘击键重复频率、查询Intel SpeedStep(IST)信息
--->设置视频控制器模式、解析命令行参数以便传递给decompressor
--->arch/x86/boot/pm.c:go_to_protected_mode() 进入保护模式
--->屏蔽PIC中的所有中断、设置GDT和IDT
--->arch/x86/boot/pmjump.S:protected_mode_jump(boot_params.hdr.code32_start,...) 跳转到保护模式
--->in_pm32() 跳转到32位保护模式的入口处(即0x100000处)
--->jmpl *%eax 跳转到arch/i386/boot/compressed/head_32.S:startup_32()处执行
arch/i386/boot/compressed/head_32.S:startup_32() 保护模式下的入口函数
--->leal boot_stack_end(%ebx), %esp 设置堆栈
--->拷贝压缩的内核到缓冲区尾部
--->清空BSS
--->compressed/misc.c:decompress_kernel() 解压内核
--->lib/decompress_bunzip2.c:decompress()
--->lib/decompress_bunzip2.c:bunzip2()
--->lib/decompress_bunzip2.c:start_bunzip() 解压动作
--->parse_elf() 将解压后的内核ELF文件(.o文件)解析到内存中
--->计算vmlinux编译时的运行地址与实际装载地址的距离
--->jmp *%ebp 跳转到解压后的内核的arch/x86/kernel/head_32.S:startup_32()处运行
arch/x86/kernel/head_32.S:startup_32() 32位内核的入口函数,即进程0(也称为清除进程)
--->拷贝boot_params以及boot_command_line
--->初始化页表:这会创建PDE和页表集
--->开启内存分页功能
--->为可选的浮点单元(FPU)检测CPU类型
--->head32.c:i386_start_kernel()
--->init/main.c:start_kernel() Linux内核的启动函数,包含创建rootfs,加载内核模块和cpio-initrd
--->很多初始化操作
--->setup_command_line() 把内核启动参数复制到boot_command_line数组中
--->parse_early_param() 体系结构代码会先调用这个函数,做时期的参数检查
--->parse_early_options()
--->do_early_param() 检查早期的参数
--->parse_args() 解析模块的参数
--->fs/dcache.c:vfs_caches_init() 创建基于内存的rootfs(一个VFS)
--->fs/namespace.c:mnt_init()
--->fs/ramfs/inode.c:init_rootfs()
--->fs/filesystems.c:register_filesystem() 注册rootfs
--->fs/namespace.c:init_mount_tree()
--->fs/super.c:do_kern_mount() 在内核中挂载rootfs
--->fs/fs_struct.c:set_fs_root() 将rootfs配置为当前内存中的根文件系统
--->rest_init()
--->arch/x86/kernel/process.c:kernel_thread(kernel_init,...) 启动一个内核线程来运行kernel_init函数,进行内核初始化
--->cpu_idle() 进入空闲循环
--->调度器周期性的接管控制权,提供多任务处理
init/main.c:kernel_init() 内核初始化过程入口函数,加载initramfs或cpio-initrd,或传统的image-initrd,把工作交给它
--->sys_open("/dev/console",...) 启动控制台设备
--->do_basic_setup()
--->do_initcalls() 启动所有静态编译进内核的模块
--->init/initramfs.c:populate_rootfs() 初始化rootfs
--->unpack_to_rootfs() 把initramfs或cpio-initrd解压释放到rootfs
--->如果是image-initrd则拷贝到/initrd.image
####################################### 传统的image-initrd情形 ###########################################
--->rootfs中没有/init文件
--->do_mounts.c:prepare_namespace() 加载image-initrd,并运行它的/linuxrc文件,以挂载实际的文件系统
--->do_mounts_initrd.c:initrd_load() 把image-initrd数据加载到默认设备/dev/ram0中
--->do_mounts_rd.c:rd_load_image() 加载image-initrd映像
--->identify_ramdisk_image() 识别initrd,确定是romfs、squashfs、minix,还是ext2
--->crd_load() 解压并为ramdisk分配空间,计算循环冗余校验码
--->lib/inflate.c:gunzip() 对gzip格式的ramdisk进行解压
--->do_mounts_initrd.c:handle_initrd() 指定的根设备不是/dev/ram0,由initrd来挂载真正的根文件系统
--->mount_block_root("/dev/root.old",...) 将initrd挂载到rootfs的/root下
--->arch/x86/kernel/process.c:kernel_thread(do_linuxrc, "/linuxrc",...) 启动一个内核线程来运行do_linuxrc函数
--->do_mounts_initrd.c:do_linuxrc()
--->arch/x86/kernel/sys_i386_32.c:kernel_execve() 运行image-initrd中的/linuxrc
--->将initrd移动到rootfs的/old下
--->若在linuxrc中根设备重新设成Root_RAM0,则返回,说明image-initrd直接作为最终的根文件系统
--->do_mounts.c:mount_root() 否则将真正的根文件系统挂载到rootfs的/root下,并切换到这个目录下
--->mount_block_root()
--->do_mount_root()
--->fs/namespace.c:sys_mount() 挂载到"/root"
--->卸载initrd,并释放它的内存
--->do_mounts.c:mount_root() 没有指定另外的根设备,则initrd直接作为真正的根文件系统而被挂载
--->fs/namespace.c:sys_mount(".", "/",...) 根文件挂载成功,移动到根目录"/"
########################################################################################################
--->init/main.c:init_post() 启动用户空间的init进程
--->run_init_process(ramdisk_execute_command) 若加载了initramfs或cpio-initrd,则运行它的/init
--->run_init_process("/sbin/init") 否则直接运行用户空间的/sbin/init
--->arch/x86/kernel/sys_i386_32.c:kernel_execve() 运行用户空间的/sbin/init程序,并分配pid为1
--->run_init_process("/bin/sh") 当运行init没成功时,可用此Shell来代替,以便恢复机器
/init cpio-initrd(或initramfs)中的初始化脚本,挂载真正的根文件系统,启动用户空间的init进程
--->export PATH=/sbin:/bin:/usr/sbin:/usr/bin 设置cpio-initrd的环境变量$PATH
--->挂载procfs、sysfs
--->解析命令行参数
--->udevd --daemon --resolve-names=never 启动udev
--->/initqueue/*.sh 执行/initqueue下的脚本完成对应初始化工作(现在该目录下为空)
--->/initqueue-settled/*.sh 执行/initqueue-settled下的脚本(现在该目录下为空)
--->/mount/*.sh 挂载真正的根文件系统
--->/mount/99mount-root.sh 根据/etc/fstab中的选项挂载根文件系统
--->/lib/dracut-lib.sh 一系列通用函数
--->把根文件系统挂载到$NEWROOT下
--->寻找真正的根文件系统中的init程序并存放在$INIT中 /sbin/init, /etc/init, /bin/init, 或/bin/sh
--->从/proc/cmdline中获取启动init的参数并存放在$initargs中
--->switch_root "$NEWROOT" "$INIT" $initargs 切换到根分区,并启动其中的init进程从以上分析可以看出,如果使用新的cpio-initrd(或initramfs),kernel_init只负责内核初始化(包括加载内核模块、创建基于内存的rootfs以及加载cpio-initrd)。后续根文件系统的挂载、init进程的启动工作都交给cpio-initrd来完成。cpio-initrd相对于image-initrd承担了更多的初始化责任,这种变化也可以看作是内核代码的用户层化的一种体现,实际上精简内核代码,将部分功能移植到用户层必然是linux内核发展的一个趋势。如果是使用传统的image-initrd的话,根文件系统的挂载也会放在kernel_init()中,其中prepare_namespace完成挂载根文件系统,init_post()完成运行/sbin/init,显然这样内核的代码不够精简。
5、init进程
init是第一个调用的使用标准C库编译的程序。在此之前,还没有执行任何标准的C应用程序。在桌面Linux系统上,第一个启动的程序通常是/sbin/init,它的进程号为1。init进程是所有进程的发起者和控制者,它有两个作用:
(1)扮演终结父进程的角色:所有的孤儿进程都会被init进程接管。
(2)系统初始化工作:如设置键盘、字体,装载模块,设置网络等。
在完成系统初始化工作之后,init进程将在控制台上运行getty(登录程序)等任务,我们熟悉的登录界面就出现了!
init程序的运行流程需要分专门的一节来讨论,因为它有不同的实现方式。传统的实现是基于UNIX System V init进程的,程序包为sysvinit(以前的RedHat/Fedora用的就是这个)。目前已经有多种sysvinit的替代产品了,这其中包括initng,它已经可以用于Debian了,并且在Ubuntu上也能工作。在同一位置上,Solaris使用SMF(Service Management Facility),而Mac OS则使用 launchd。现在广泛使用的是upstart init初始化进程,目前在Ubuntu和Fedora,还有其他系统中已经取代了sysvinit。
传统的Sysvinit daemon是一个基于运行级别的初始化程序,它使用了运行级别(如单用户、多用户等)并通过从/etc/rcX.d目录到/etc/init.d目录的初始化脚本的链接来启动与终止系统服务。Sysvinit无法很好地处理现代硬件,如热插拔设备、USB硬盘、网络文件系统等。upstart系统则是事件驱动的,事件可能被硬件改动触发,也可被启动或关机或任务所触发,或者也可能被系统上的任何其他进程所触发。事件用于触发任务或服务,统称为作业。比如连接到一个USB驱动器可能导致udev服务发送一个block-device-added事件,这可能引起一个预定任务检查/etc/fstab和挂载驱动器(如果需要的话)。再如,一个Apache web服务器可能只有当网络和所需的文件系统都可用时才能启动。
Upstart作业在/etc/init目录及其子目录下被定义。upstart系统兼容sysvinit,它也会处理/etc/inittab和System V init脚本(如果有的话)。在诸如近来的Fedora版本的系统上,/etc/inittab可能只含有initdefault操作的id项。目前Ubuntu系统默认没有/etc/inittab,如果您想要指定一个默认运行级别的话,您可以创建一个。Upstart也使用initctl命令来支持与upstart init守护进程的交互。这时您可以启动或终止作业、列表作业、以及获取作业的状态、发出事件、重启init进程,等等。
总的来说,x86架构的Linux内核启动过程分为6大步,分别为:
(1)实模式的入口函数_start():在header.S中,这里会进入众所周知的main函数,它拷贝bootloader的各个参数,执行基本硬件设置,解析命令行参数。
(2)保护模式的入口函数startup_32():在compressed/header_32.S中,这里会解压bzImage内核映像,加载vmlinux内核文件。
(3)内核入口函数startup_32():在kernel/header_32.S中,这就是所谓的进程0,它会进入体系结构无关的start_kernel()函数,即众所周知的Linux内核启动函数。start_kernel()会做大量的内核初始化操作,解析内核启动的命令行参数,并启动一个内核线程来完成内核模块初始化的过程,然后进入空闲循环。
(4)内核模块初始化的入口函数kernel_init():在init/main.c中,这里会启动内核模块、创建基于内存的rootfs、加载initramfs文件或cpio-initrd,并启动一个内核线程来运行其中的/init脚本,完成真正根文件系统的挂载。
(5)根文件系统挂载脚本/init:这里会挂载根文件系统、运行/sbin/init,从而启动众所周知的进程1。
(6)init进程的系统初始化过程:执行相关脚本,以完成系统初始化,如设置键盘、字体,装载模块,设置网络等,最后运行登录程序,出现登录界面。
如果从体系结构无关的视角来看,start_kernel()可以看作时体系结构无关的Linux main函数,它是体系结构无关的代码的统一入口函数,这也是为什么文件会命名为init/main.c的原因。这个main.c粘合剂把各种体系结构的代码“粘合”到一个统一的入口处。
整个内核启动过程如下图:
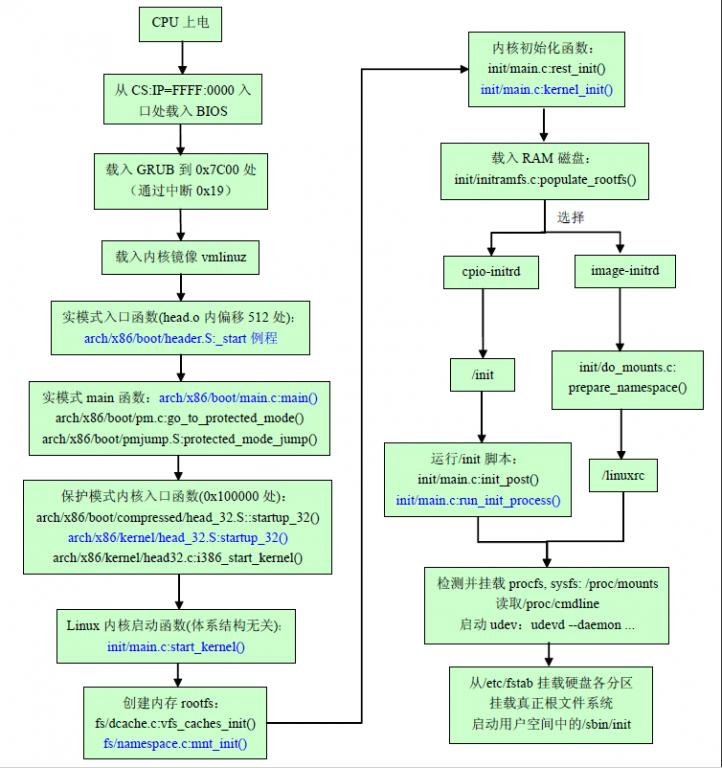
图1 Linux内核启动过程














 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









