







没办法,掉进了Deep Learn的大坑,慢慢爬吧,你懂得!
想要了解DBN想让我们来搞一搞RBM吧
RBM中文名字叫受限制的玻尔兹曼机,英文全称
R
estricted Boltzmann Machine. 其实在这个兄弟出来之前,有个叫Boltzmann Machine的东东。也即是玻尔兹曼机的意思,这是一种基于热力学统计方法。已经在多个领域里应用起来,以前做过煤方法的工作,也接触过BM这东东,那个时候还是用了研究流体。命名玻尔兹曼可能是为了纪念下面这位仁兄。(其实这种天才科学家什么的最讨厌了。发明出来这么多东西要学.)

下面让我们来看看RBM和他的兄弟BM的区别吧,先上图

这样就一目了然了,之所以说他是受限,是应为在RBM内取消了可见层和隐含层的层内连接,虽然BM具有强大的无监督学习能力,能过学习复杂的规则,但是因为层内连接,使得整个学习过程消耗漫长的时间。所以Smolensky发明了RBM是学习时间大大缩减。也为后面的DBN奠定了基础。
让我们来看看RBM的单独图
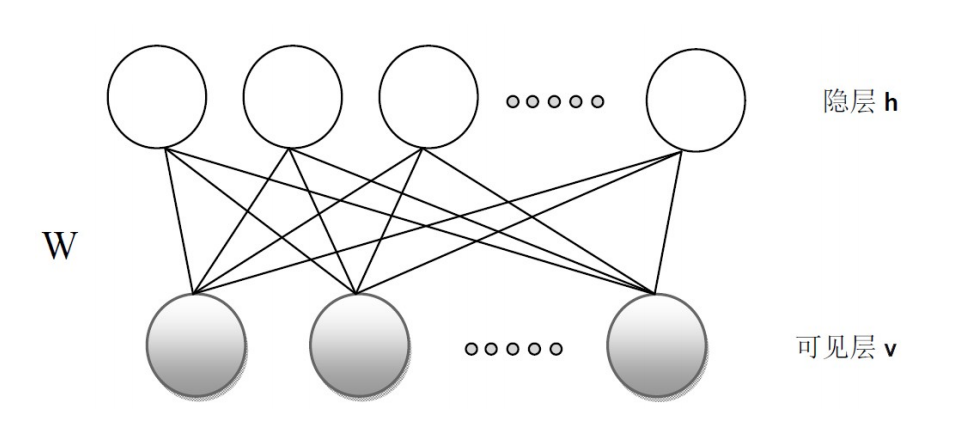
RBM有一个可见层和一个隐含层,通过上面的BM到RBM的转变使得RBM具有了一个很好的特性:在给定可见层单元状态时,各隐含单元的激活条件独立,反之,在给定隐含层单元的状态时,各隐含层激活条件也是独立的。虽然这样RBM所表示的分布仍是无法有效计算的,但是我们可以通过Gibbs采样使其得到服从RBM分布的随机样本。
下面我们说一说关于RBM的结构,他有一个可见层和一个隐含层和中间的链接。可见层用于观测数据,隐含层用来提取特征。他们中的单元可以为任意指数族单元,当然神经网络最爱sigmoid函数啦!
接下来就是讨厌的公式了:
定义RBM的能量为:

基于该能量函数我们可以得到隐含层和可见层的联合分布:

接下来我们便可得到边界分布,即似然函数:

这里的右边式子前面的系数就是我们说的sigmoid函数啦!
因为前面我们提到过各单元独立的特性和RBM自身的对称性,我们可以推导出可见单元的激活概率:
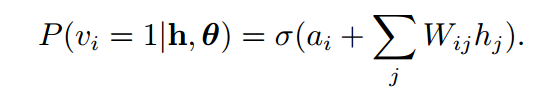
RBM中的权值更新变量,采用的是随机梯度上升算法:
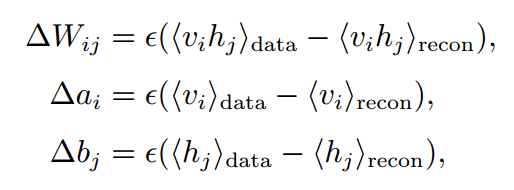
其中等式右面的系数是增量的学习效率。
好了现在我们就可以来看看RBM是怎么自我学习的了:

下面我们来用MATLAB的代码实现他吧:
epsilonw = 0.01; % 权值学习效率
epsilonvb = 0.01; % 可见层偏置
epsilonhb = 0.01; % 隐含层偏置
weightcost = 0.001;
initialmomentum = 0.5;
finalmomentum = 0.9;
[numcases numdims numbatches]=size(batchdata);
% 初始化权值和偏置
vishid = 0.1*randn(numdims, numhid);
hidbiases = zeros(1,numhid);
visbiases = zeros(1,numdims);
poshidprobs = zeros(numcases,numhid);
neghidprobs = zeros(numcases,numhid);
posprods = zeros(numdims,numhid);
negprods = zeros(numdims,numhid);
vishidinc = zeros(numdims,numhid);
hidbiasinc = zeros(1,numhid);
visbiasinc = zeros(1,numdims);
batchposhidprobs=zeros(numcases,numhid,numbatches);
for epoch = epoch:maxepoch, %重建次数
errsum=0;
for batch = 1:numbatches, %对数据进行分批在处理
%从可见层向隐含层运算
data = batchdata(:,:,batch);
poshidprobs = 1./(1 + exp(-data*vishid - repmat(hidbiases,numcases,1))); %生成隐含成的概率
batchposhidprobs(:,:,batch)=poshidprobs;
posprods = data' * poshidprobs;
poshidact = sum(poshidprobs);
posvisact = sum(data);
poshidstates = poshidprobs > rand(numcases,numhid); %可见层到隐含层的激活状态
%从隐含层到可见层的解码过程,调整权值
negdata = 1./(1 + exp(-poshidstates*vishid' - repmat(visbiases,numcases,1)));
neghidprobs = 1./(1 + exp(-negdata*vishid - repmat(hidbiases,numcases,1))); %生成可见层的概率
negprods = negdata'*neghidprobs;
neghidact = sum(neghidprobs);
negvisact = sum(negdata);
err= sum(sum( (data-negdata).^2 )); %计算误差
errsum = err + errsum;
%调整学习效率
if epoch>5,
momentum=finalmomentum;
else
momentum=initialmomentum;
end;
%更新权值和偏置
vishidinc = momentum*vishidinc + ...
epsilonw*( (posprods-negprods)/numcases - weightcost*vishid);
visbiasinc = momentum*visbiasinc + (epsilonvb/numcases)*(posvisact-negvisact);
hidbiasinc = momentum*hidbiasinc + (epsilonhb/numcases)*(poshidact-neghidact);
vishid = vishid + vishidinc;
visbiases = visbiases + visbiasinc;
hidbiases = hidbiases + hidbiasinc;
end;
end;TO BE CONTINUE....爬坑中....
参考文献:
[1] An Introduction to Restricted Boltzmann Machines
[2] Learning Deep Architectures for AI
[3] A Practical Guide to Training Restricted Boltzmann Machines
[4] A learning Algorithm for Boltzmann Machines

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









