




 本文详细介绍了Apriori算法的基本原理及其在关联规则挖掘中的应用。包括算法的主要步骤:连接步和剪枝步,以及如何利用先验性质压缩搜索空间。此外,还提供了一个Java实现的例子,展示了如何通过实际代码找出频繁项集。
本文详细介绍了Apriori算法的基本原理及其在关联规则挖掘中的应用。包括算法的主要步骤:连接步和剪枝步,以及如何利用先验性质压缩搜索空间。此外,还提供了一个Java实现的例子,展示了如何通过实际代码找出频繁项集。
一些基本概念
支持度:support(A=>B)=P(A并B)
置信度:confidence(A=>B)=P(B|A)
频繁k项集:如果项集I的支持度满足预定义的最小支持度阈值,则称I为频繁项集,包含k个项的项集称为k项集。
算法思想
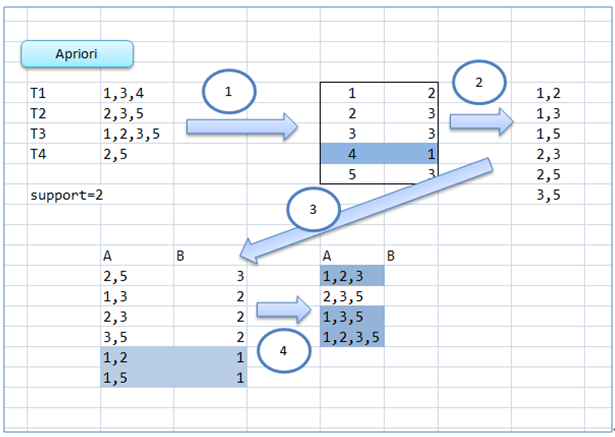
Apriori算法是Agrawal和R. Srikant于1994年提出,为布尔关联规则挖掘频繁项集的原创性算法。通过名字可以看出算法基于这样一个事实:算法使用频繁项集性质的先验知识。apriori算法使用一种成为逐层搜索的迭代算法,其中k项集用于探索(k+1)项集。首先,通过扫描数据库,累计每个项的计数,并搜集满足最小支持度的项,找出频繁1项集的集合。该集合记为L1。然后,使用L1找出频繁2项集的集合L2,使用L2找出L3,如此下去,直到不能再找到频繁k项集。
可以想象,该算法基本思路计算复杂度是非常大的。为了提高频繁项集的产生效率,使用先验性质(频繁项集的所有非空子集也一定是频繁的;换句话说,若某个集合存在一个非空子集不是频繁项集,则该集合不是频繁项集)来压缩搜索空间。
如何在算法中使用先验性质?为了理解这一点,我们考察如何使用Lk-1找出Lk,其中k>=2。主要由两步构成:连接步和剪枝步。
连接步:为找出Lk,通过将Lk-1与自身相连接产生候选集k项集的集合。该候选集的集合记为Ck。设l1和l2是Lk-1中的项集。记号li[j]表示li的第j项(例如,l1[k-2]表示l1的倒数第2项)。为了有效实现,apriori算法假定事务或项集中的项按字典序排列。对于(k-1)项集li,这意味着把项排序,使得li[1]<li[2]<...<li[k-1]。连接Lk-1和Lk-1;其中Lk-1的元素是可连接的,如果它们前(k-2)项相同。即Lk-1的元素l1和l2是可连接的,如果(l1[1]=l2[1])^(l1[2]=l2[2])^...^(l1[k-2]=l2[k-2])^(l1[k-1]<l2[k-1])。条件l1[k-1]<l2[k-1]是简单保证不产生重复。连接l1和l2产生的结果项集是{l1[1],l1[2],...,l1[k-1],l2[k-1]}
剪枝步: CK是LK的超集,也就是说,CK的成员可能是也可能不是频繁的。通过扫描所有的事务(交易),确定CK中每个候选的计数,判断是否小于最小支持度计数,如果不是,则认为该候选是频繁的。为了压缩Ck,可以利用Apriori性质:任一频繁项集的所有非空子集也必须是频繁的,反之,如果某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其从CK中删除。(该步利用了标红的先验性质)
图例
伪代码
算法:Apriori
输入:D - 事务数据库;min_sup - 最小支持度计数阈值
输出:L - D中的频繁项集
方法:
L1=find_frequent_1-itemsets(D); // 找出所有频繁1项集
For(k=2;Lk-1!=null;k++){
Ck=apriori_gen(Lk-1); // 产生候选,并剪枝
For each 事务t in D{ // 扫描D进行候选计数
Ct =subset(Ck,t); // 得到t的子集
For each 候选c 属于 Ct
c.count++;
}
Lk={c属于Ck | c.count>=min_sup}
}
Return L=所有的频繁集;
Procedure apriori_gen(Lk-1:frequent(k-1)-itemsets)
For each项集l1属于Lk-1
For each项集 l2属于Lk-1
If((l1[1]=l2[1])&&( l1[2]=l2[2])&&…….
&& (l1[k-2]=l2[k-2])&&(l1[k-1]<l2[k-1])) then{
c=l1连接l2 //连接步:产生候选
if has_infrequent_subset(c,Lk-1) then
delete c; //剪枝步:删除非频繁候选
else add c to Ck;
}
Return Ck;
Procedure has_infrequent_sub(c:candidate k-itemset; Lk-1:frequent(k-1)-itemsets)
For each(k-1)-subset s of c
If s不属于Lk-1 then
Return true;
Return false;Java实现
该java代码基本上是严格按照伪代码的流程写的,比较容易理解。
package com.zhyoulun.apriori;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class Apriori2
{
private final static int SUPPORT = 2; // 支持度阈值
private final static double CONFIDENCE = 0.7; // 置信度阈值
private final static String ITEM_SPLIT = ";"; // 项之间的分隔符
private final static String CON = "->"; // 项之间的分隔符
/**
* 算法主程序
* @param dataList
* @return
*/
public Map<String, Integer> apriori(ArrayList<String> dataList)
{
Map<String, Integer> stepFrequentSetMap = new HashMap<>();
stepFrequentSetMap.putAll(findFrequentOneSets(dataList));
Map<String, Integer> frequentSetMap = new HashMap<String, Integer>();//频繁项集
frequentSetMap.putAll(stepFrequentSetMap);
while(stepFrequentSetMap!=null && stepFrequentSetMap.size()>0)
{
Map<String, Integer> candidateSetMap = aprioriGen(stepFrequentSetMap);
Set<String> candidateKeySet = candidateSetMap.keySet();
//扫描D,进行计数
for(String data:dataList)
{
for(String candidate:candidateKeySet)
{
boolean flag = true;
String[] strings = candidate.split(ITEM_SPLIT);
for(String string:strings)
{
if(data.indexOf(string+ITEM_SPLIT)==-1)
{
flag = false;
break;
}
}
if(flag)
candidateSetMap.put(candidate, candidateSetMap.get(candidate)+1);
}
}
//从候选集中找到符合支持度的频繁项集
stepFrequentSetMap.clear();
for(String candidate:candidateKeySet)
{
Integer count = candidateSetMap.get(candidate);
if(count>=SUPPORT)
stepFrequentSetMap.put(candidate, count);
}
// 合并所有频繁集
frequentSetMap.putAll(stepFrequentSetMap);
}
return frequentSetMap;
}
/**
* find frequent 1 itemsets
* @param dataList
* @return
*/
private Map<String, Integer> findFrequentOneSets(ArrayList<String> dataList)
{
Map<String, Integer> resultSetMap = new HashMap<>();
for(String data:dataList)
{
String[] strings = data.split(ITEM_SPLIT);
for(String string:strings)
{
string += ITEM_SPLIT;
if(resultSetMap.get(string)==null)
{
resultSetMap.put(string, 1);
}
else {
resultSetMap.put(string, resultSetMap.get(string)+1);
}
}
}
return resultSetMap;
}
/**
* 根据上一步的频繁项集的集合选出候选集
* @param setMap
* @return
*/
private Map<String, Integer> aprioriGen(Map<String, Integer> setMap)
{
Map<String, Integer> candidateSetMap = new HashMap<>();
Set<String> candidateSet = setMap.keySet();
for(String s1:candidateSet)
{
String[] strings1 = s1.split(ITEM_SPLIT);
String s1String = "";
for(String temp:strings1)
s1String += temp+ITEM_SPLIT;
for(String s2:candidateSet)
{
String[] strings2 = s2.split(ITEM_SPLIT);
boolean flag = true;
for(int i=0;i<strings1.length-1;i++)
{
if(strings1[i].compareTo(strings2[i])!=0)
{
flag = false;
break;
}
}
if(flag && strings1[strings1.length-1].compareTo(strings2[strings1.length-1])<0)
{
//连接步:产生候选
String c = s1String+strings2[strings2.length-1]+ITEM_SPLIT;
if(hasInfrequentSubset(c, setMap))
{
//剪枝步:删除非频繁的候选
}
else {
candidateSetMap.put(c, 0);
}
}
}
}
return candidateSetMap;
}
/**
* 使用先验知识,判断候选集是否是频繁项集
* @param candidate
* @param setMap
* @return
*/
private boolean hasInfrequentSubset(String candidateSet, Map<String, Integer> setMap)
{
String[] strings = candidateSet.split(ITEM_SPLIT);
//找出候选集所有的子集,并判断每个子集是否属于频繁子集
for(int i=0;i<strings.length;i++)
{
String subString = "";
for(int j=0;j<strings.length;j++)
{
if(j!=i)
{
subString += strings[j]+ITEM_SPLIT;
}
}
if(setMap.get(subString)==null)
return true;
}
return false;
}
/**
* 由频繁项集产生关联规则
* @param frequentSetMap
* @return
*/
public Map<String, Double> getRelationRules(Map<String, Integer> frequentSetMap)
{
Map<String, Double> relationsMap = new HashMap<>();
Set<String> keySet = frequentSetMap.keySet();
for(String key:keySet)
{
List<String> keySubset = subset(key);
for(String keySubsetItem:keySubset)
{
//子集keySubsetItem也是频繁项
Integer count = frequentSetMap.get(keySubsetItem);
if(count!=null)
{
Double confidence = (1.0*frequentSetMap.get(key))/(1.0*frequentSetMap.get(keySubsetItem));
if(confidence>CONFIDENCE)
relationsMap.put(keySubsetItem+CON+expect(key, keySubsetItem), confidence);
}
}
}
return relationsMap;
}
/**
* 求一个集合所有的非空真子集
*
* @param sourceSet
* @return
* 为了以后可以用在其他地方,这里我们不是用递归的方法
*
* 参考:http://blog.163.com/xiaohui_1123@126/blog/static/3980524020109784356915/
* 思路:假设集合S(A,B,C,D),其大小为4,拥有2的4次方个子集,即0-15,二进制表示为0000,0001,...,1111。
* 对应的子集为空集,{D},...,{A,B,C,D}。
*/
private List<String> subset(String sourceSet)
{
List<String> result = new ArrayList<>();
String[] strings = sourceSet.split(ITEM_SPLIT);
//非空真子集
for(int i=1;i<(int)(Math.pow(2, strings.length))-1;i++)
{
String item = "";
String flag = "";
int ii=i;
do
{
flag += ""+ii%2;
ii = ii/2;
} while (ii>0);
for(int j=flag.length()-1;j>=0;j--)
{
if(flag.charAt(j)=='1')
{
item = strings[j]+ITEM_SPLIT+item;
}
}
result.add(item);
}
return result;
}
/**
* 集合运算,A/B
* @param A
* @param B
* @return
*/
private String expect(String stringA,String stringB)
{
String result = "";
String[] stringAs = stringA.split(ITEM_SPLIT);
String[] stringBs = stringB.split(ITEM_SPLIT);
for(int i=0;i<stringAs.length;i++)
{
boolean flag = true;
for(int j=0;j<stringBs.length;j++)
{
if(stringAs[i].compareTo(stringBs[j])==0)
{
flag = false;
break;
}
}
if(flag)
result += stringAs[i]+ITEM_SPLIT;
}
return result;
}
public static void main(String[] args)
{
ArrayList<String> dataList = new ArrayList<>();
dataList.add("1;2;5;");
dataList.add("2;4;");
dataList.add("2;3;");
dataList.add("1;2;4;");
dataList.add("1;3;");
dataList.add("2;3;");
dataList.add("1;3;");
dataList.add("1;2;3;5;");
dataList.add("1;2;3;");
System.out.println("=数据集合==========");
for(String string:dataList)
{
System.out.println(string);
}
Apriori2 apriori2 = new Apriori2();
System.out.println("=频繁项集==========");
Map<String, Integer> frequentSetMap = apriori2.apriori(dataList);
Set<String> keySet = frequentSetMap.keySet();
for(String key:keySet)
{
System.out.println(key+" : "+frequentSetMap.get(key));
}
System.out.println("=关联规则==========");
Map<String, Double> relationRulesMap = apriori2.getRelationRules(frequentSetMap);
Set<String> rrKeySet = relationRulesMap.keySet();
for (String rrKey : rrKeySet)
{
System.out.println(rrKey + " : " + relationRulesMap.get(rrKey));
}
}
}计算结果
=数据集合==========
1;2;5;
2;4;
2;3;
1;2;4;
1;3;
2;3;
1;3;
1;2;3;5;
1;2;3;
=频繁项集==========
1;2; : 4
1;3; : 4
5; : 2
2;3; : 4
4; : 2
2;4; : 2
1;5; : 2
3; : 6
2; : 7
1; : 6
1;2;5; : 2
1;2;3; : 2
2;5; : 2
=关联规则==========
4;->2; : 1.0
5;->1;2; : 1.0
5;->1; : 1.0
1;5;->2; : 1.0
5;->2; : 1.0
2;5;->1; : 1.0
参考:
http://blog.csdn.net/zjd950131/article/details/8071414
http://www.cnblogs.com/zacard-orc/p/3646979.html
数据挖掘:概念与技术
转载请注明出处:http://blog.csdn.net/zhyoulun/article/details/41978401

















 5445
5445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









