









R-FCN: Object Detection via Region-based Fully Convolutional Networks (NIPS 16), Arxiv 16.05
=====
blogs:
论文阅读]R-FCN: Object Detection via Region-based Fully Convolutional Networks:
http://blog.csdn.net/u012361214/article/details/51507590
论文笔记 | R-FCN: Object Detection via Region-based Fully Convolutional Networks:
http://blog.csdn.net/bea_tree/article/details/51817263
R-FCN: Object Detection via Region-based Fully Convolutional Networks:
http://blog.csdn.net/surgewong/article/details/51873372
=====
论文:
R-FCN - Object Detection via Region-based Fully Convolutional Networks
=====
开源代码:
现在有开源的py code:
py-R-FCN:
https://github.com/Orpine/py-R-FCN
py-R-FCN-multiGPU:
https://github.com/bharatsingh430/py-R-FCN-multiGPU/

=====
如何将R-FCN整合到py-faster-rcnn?
成功将rfcn的matlab代码整合到py-faster-rcnn中,跑出来的实验为:
train:07+12 trainval
test: 07 test
resnet50:74.24%mAP (0.10s~0.12s per image)
resnet101: 76.23% mAP
(0.14s~0.16s per image)
----------------------------------------------------------------------------------------------
笔者将继续做论文里提到的multi-scale training和OHEM (
持续更新ing)
resnet50 + OHEM(end2end style):76.91%/76.83%/76.93%/76.32%mAP (0.10s~0.12s per image) -- 离论文里的77.4%还有一点差距
resnet50 + multi-scale training: 74.46%mAP (0.10s~0.12s per image) -- 貌似不起效果,笔者打算邮件问下论文作者。
resnet50 + OHEM(end2end style)+ multi-scale training:77.20%/77.77%/77.88mAP (0.10s~0.12s per image)
resnet101(end2end style):75.91%/76.23%/76.4%mAP (0.14s~0.17s per image)
resnet101 + OHEM(end2end style)
:
78.62%/78.39%/78.93%/78.51%
mAP (0.14s~0.17s per image)
resnet101 + OHEM(end2end style)+ multi-scale training:79.4%/79.48%mAP (0.14s~0.17s per image)
总觉得和论文里相差1%,是不是因为end2end方式的原因?
(笔者觉得应该是训练时batchsize的原因,论文里面是8 GPUs的并行训练,而笔者是1 GPU的训练)
=====
支持1080P和cudnn v5
Maybe you can try to merge caffe master branch into origin.
cd R-FCN/external/caffe/
git remote add bvlc https://github.com/BVLC/caffe.git
git fetch bvlc
git merge bvlc/master
Remove "self_.attr("phase") = static_cast<int>(this->phase_);"from `include/caffe/layers/python_layer.hpp`after merging.
=====
论文概述:
论文的核心在于:
在whole-image上,怎么将translate-invariance的object classifer(如ResNet)转为translate-variance的object detector,
来提高performaces的同时,还能降低训练测试的时间。
(至于其他的论文是如何耗时的,如RCNN,Fast-RCNN,Faster-RCNN等,以及该论文是怎么做的,可以参考上面的blogs,都有较为详细的讲述)
=====
Key idea of R-FCN (
cls-net
)
论文的关键之处在于提出了:能够编码position information的score maps,以及对score map进行的position-sensitive的RoI Pooling。
具体而言:
1 在最后一层map之后,再使用卷积计算产生一个k*k*(C+1)的maps(k*k代表总共的grid数目,C代表class num,+1代表加入一个背景类)。
2 每一个proposal的位置信息都需要编码,那么先把proposal分成k*k个grid(这里k就是Faster-RCNN里面的roi pooling的kernel size)
3 然后对每一个grid进行编码,其中每个grid对应一个score map(如下面的
Visualization所示)。
4 每个grid的pooling操作为average pooling。
5 进行vote(同样采用average的方式)
对于cls-net和det-net的操作类似。
具体可以参考上述的
博文1.
PS,博文3更为详细,极力推荐。
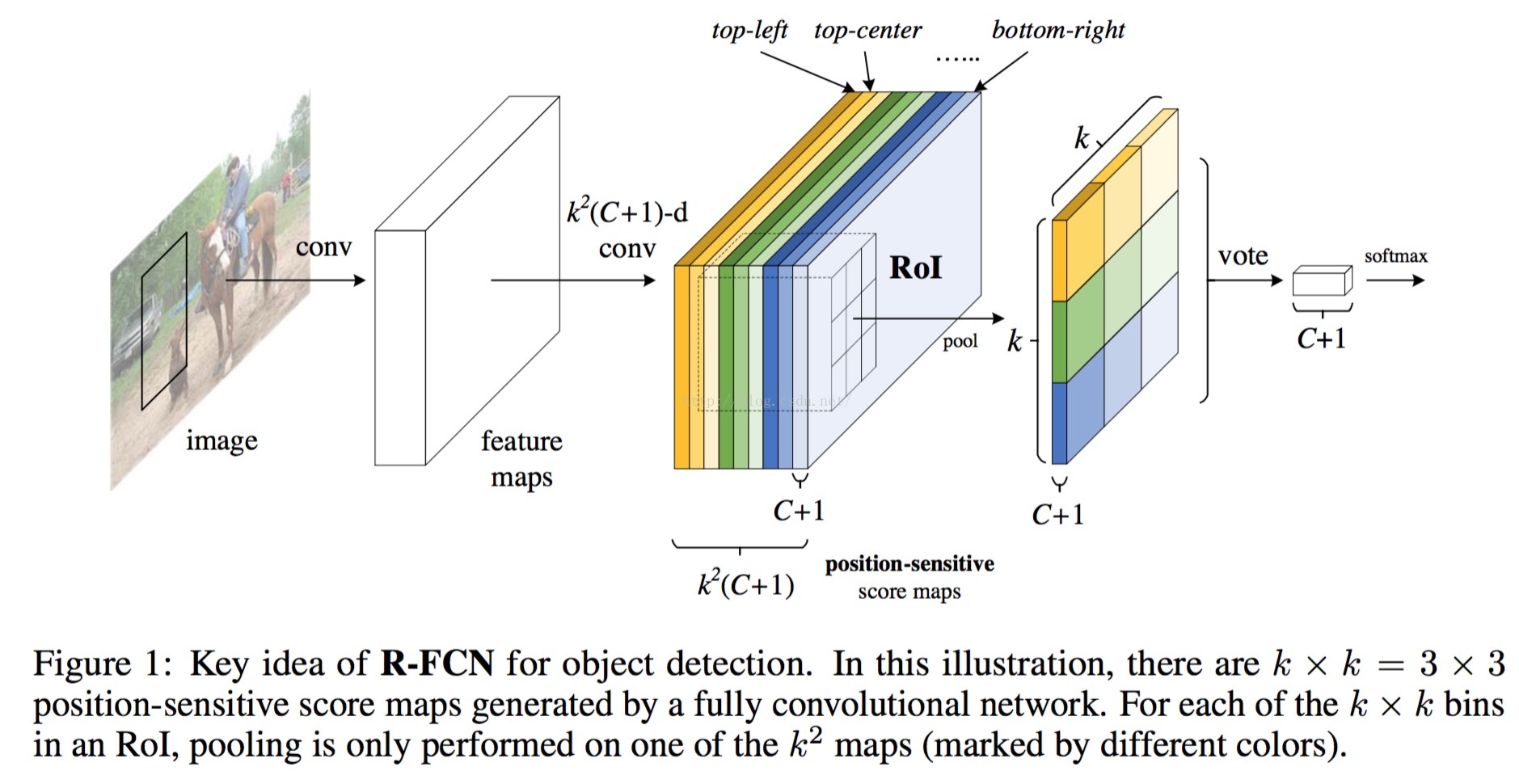
=====
Framework of R-FCN
引入了RPN,其中RPN来自于Faster-RCNN,RPN接在conv4和conv5之间,其stride为16。
而position-sensitive score maps和position-sensitive RoI Pooling接在最后一个卷积层后,并有cls-net和det-net(类似于Faster-RCNN,只不过其没有可学习的参数)
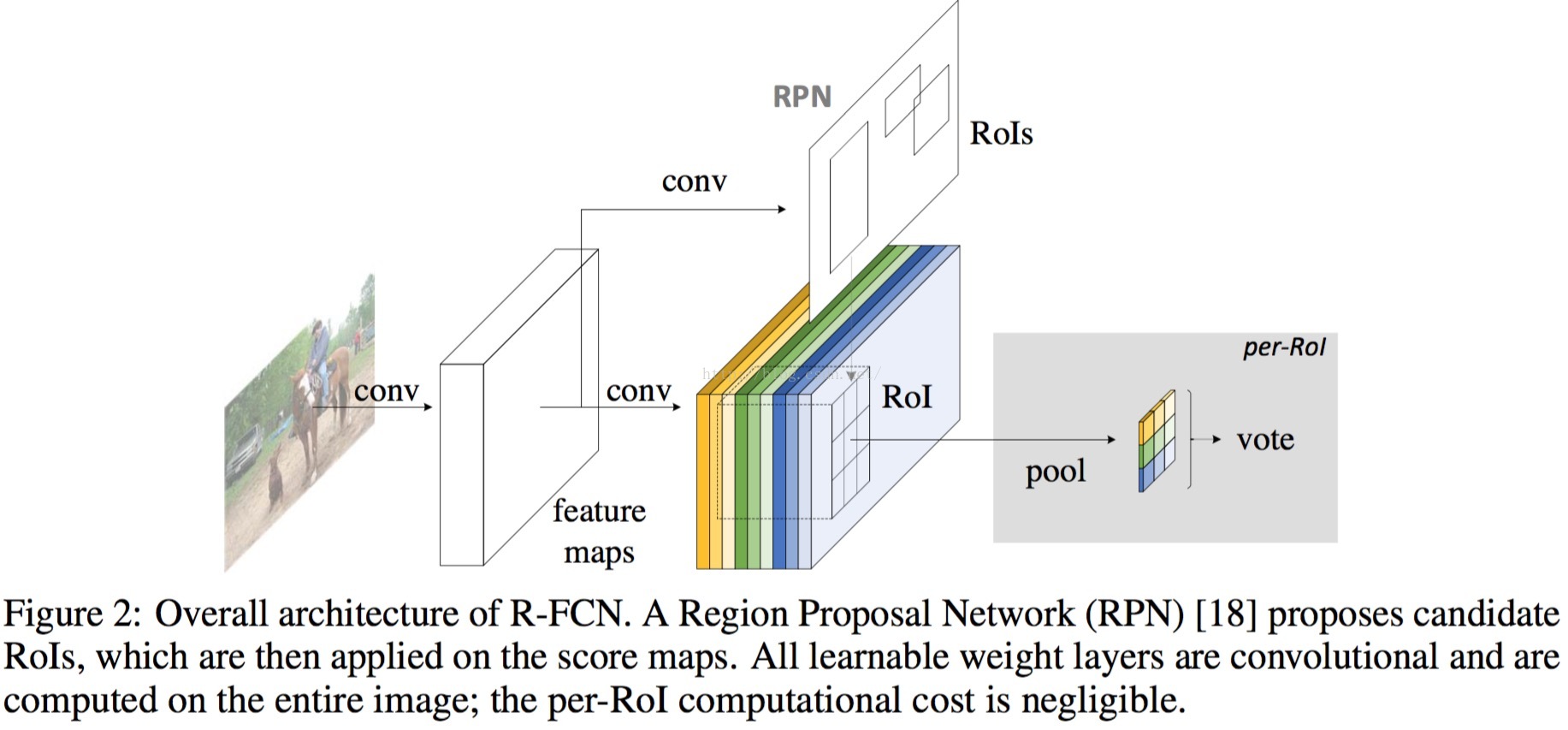
=====
position-sensitive score maps & position sensitive RoI Pooling -> bounding box classification
如下图,详细说了position-sensitive score maps & position sensitive RoI Pooling的操作,以及vote操作。


=====
Visualization of position-sensitive RoI Pooling
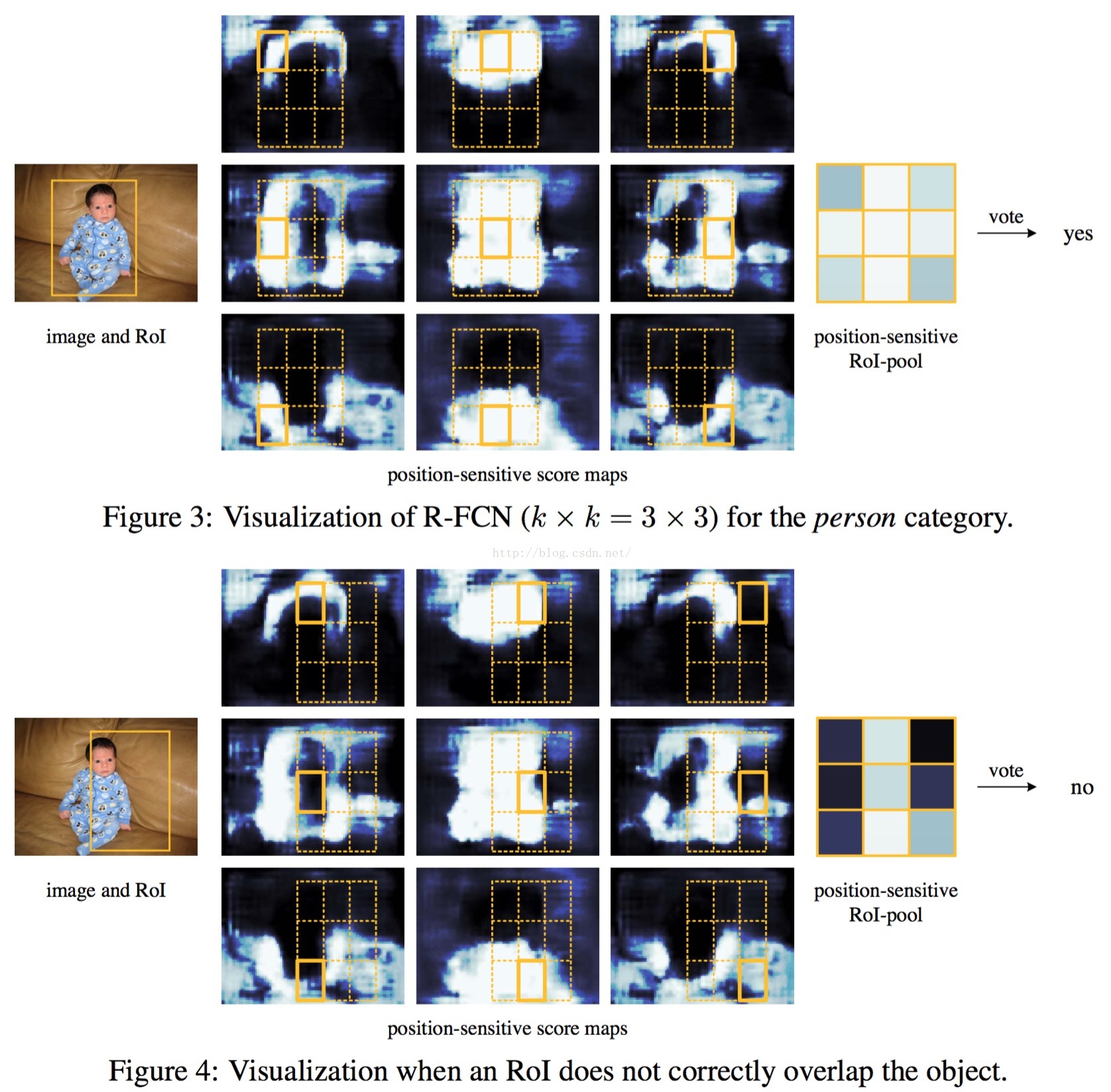
======
bounding box regession (class-agnostic) (
det-net
)
做法和Faster-RCNN类似,只是没有用到full connected layers,而是用full convolutional layers来替代,很是巧妙。
可以大大地提高speed。

=====
inspiration by other papers

=====
Training
训练的过程和Fast-RCNN或者Faster-RCNN的做法差不多。
论文中提到multi-scale的training是有必要的,其short-side的取值为:[400, 500, 600, 700, 800]
论文采用4 stages的做法来训练R-FCN,其中RPN来自于Faster-RCNN。

=====
Testing
测试阶段,除了COCO数据外,都是single scale(为600)的testing。
=====
OHEM
[22]的论文笔记可以看笔者的
博文。
论文中的OHEM的做法很是巧妙,具体看源码的prototxt。值得关注的是,论文中proposals的个数不管是train还是test阶段,都是用300个。
另外,为了很好地生成proposals,而且生成的proposals的高质量和稳定性(笔者不知道用什么词来描述),
论文采用了faster-rcnn的4 stages的方式来训练,而不是end2end的方式。
(其实笔者做过[22]的基于faster-rcnn的end2end的实验,发现效果不佳,很可能是end2end的过程中,rpn生成的proposals的coverage和stable不够好导致)

=====
astrous algorithm
虽然笔者对astrous不甚了解,但是知道其效果很好。
具体的astrous请看论文的相关引用论文。
该论文的做法:
由ResNet101的32 p的stride变为16 pixels,增加了score map的分辨率,
前四个阶段的stride不变,
第五阶段由stride=2变为1,其filter使用hole algorithm修改
(即在conv_parm里面添加dilaton参数,具体看开源的prototxt的`res5a_branch2b`卷积层)
mAP可提高2.6个百分点:

=====
Depth and Region Proposal Method
嗯,这个实验对比很好,说明了depth的重要性,和解决了proposals method如何选择的问题。
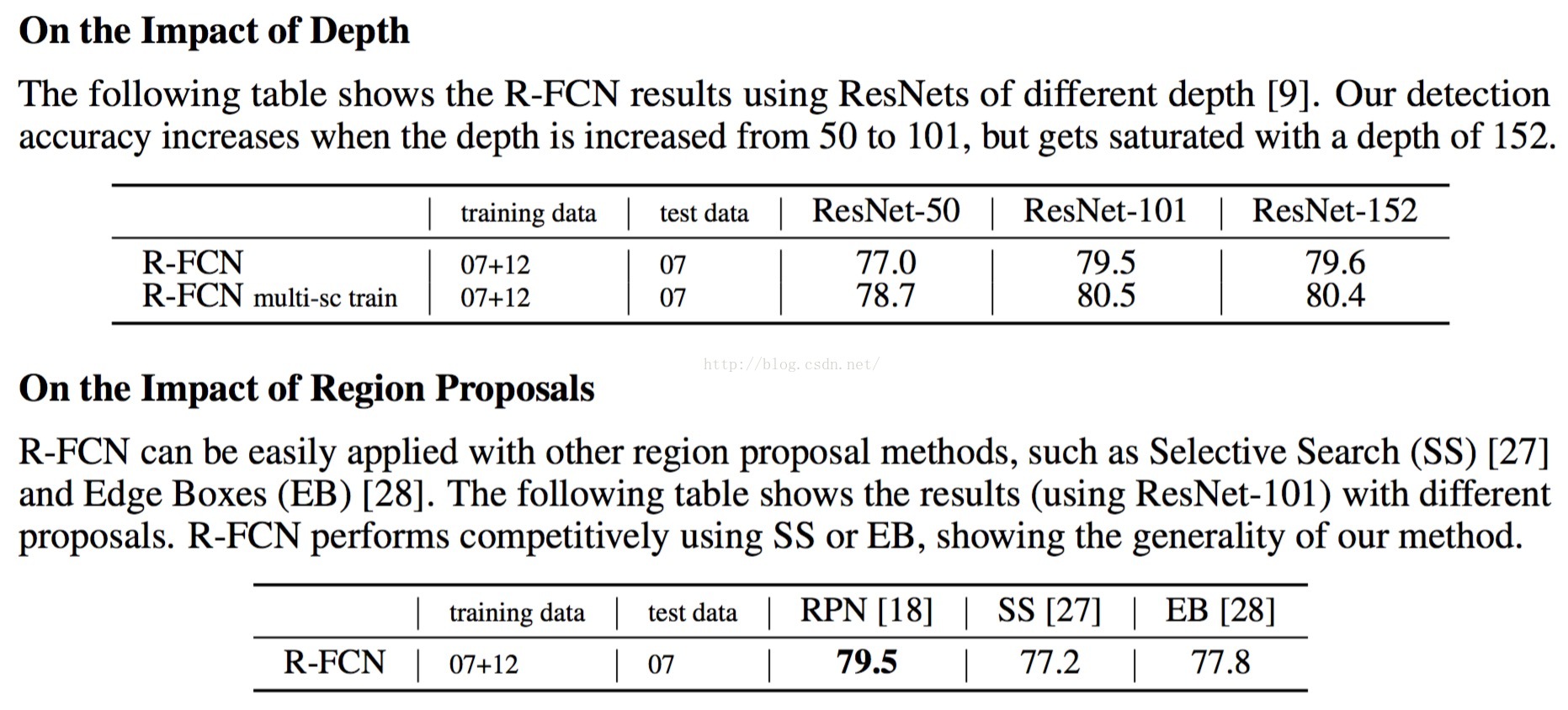
=====
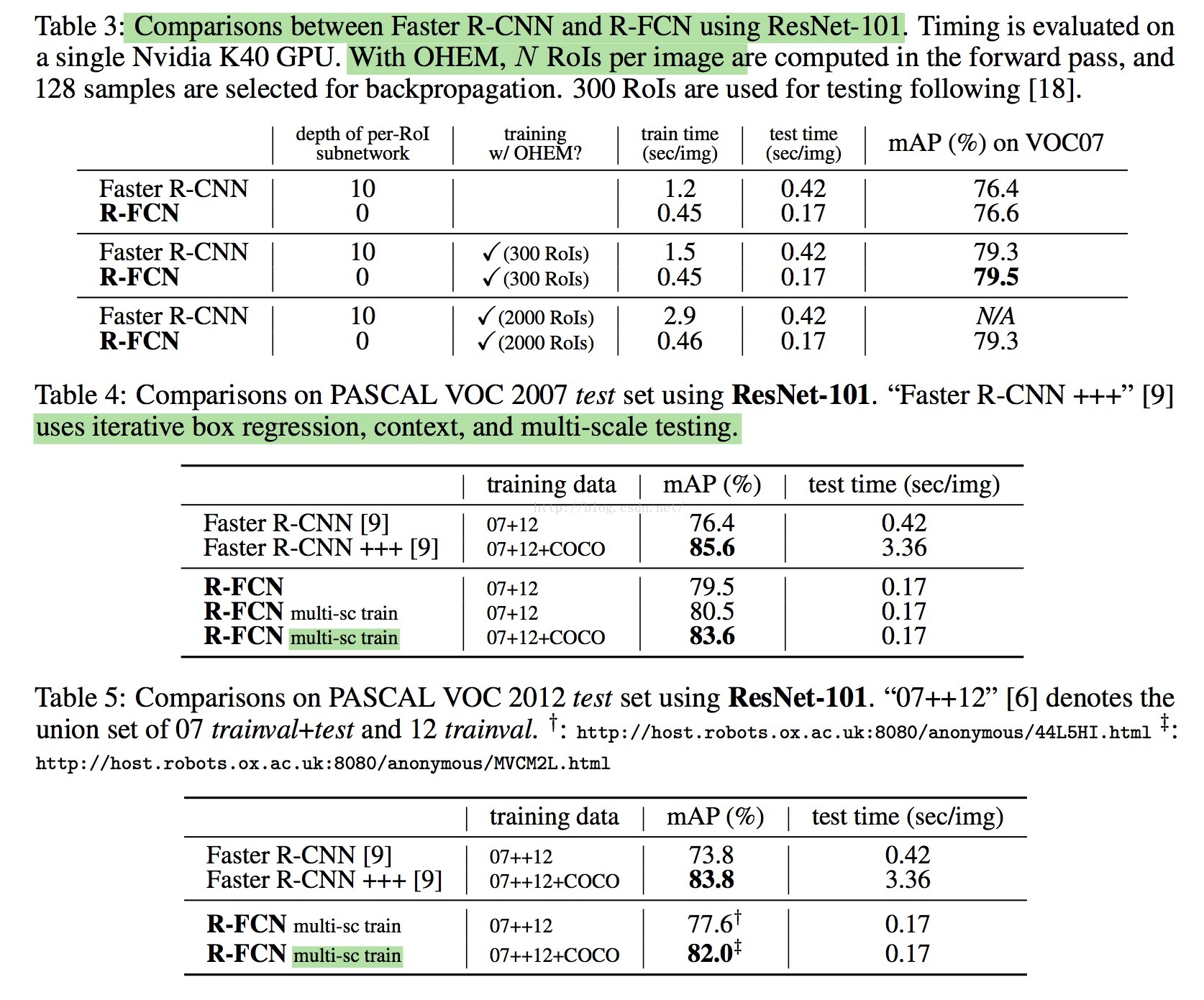
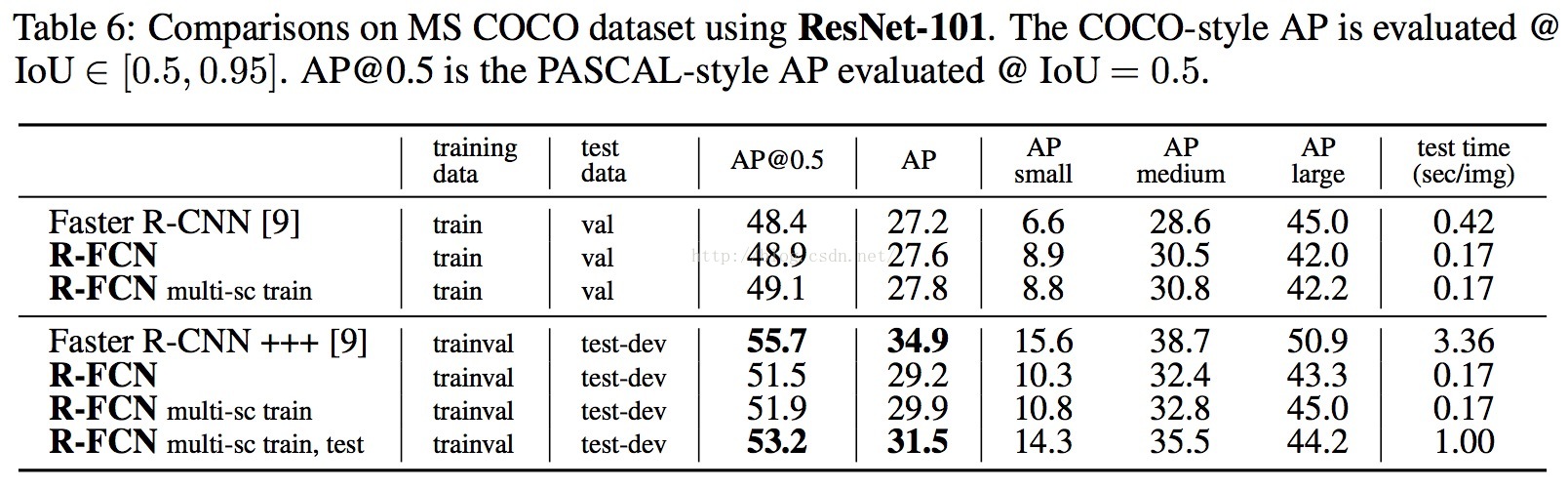
Results
论文中并没有用到引用论文[9](resnet)的global context,bounding box的iterative regession等技巧,
而最多只用到了multi-scale的training和single-scale的testing(coco dataset除外)。
由于舍弃了full-connected layers,以及加入了OHEM,使得论文不管在精度上还是速度上,都取得很好的效果。
Pascal Voc 07/12
COCO
=====
如果这篇博文对你有帮助,可否赏笔者喝杯奶茶?
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









