








笔者最近在关注fine-grained方面的paper,发现有以下的方面去做:
1 part-based
2 weakly-supervised的,如second-orderless pooling(Compact Bilinear Pooling)等
3 还是weakly-supervised的,但用上了proposals/grids/regions(如selective search)等,在网络中同时做classification和detection。
该论文Improving Facial Attribute Prediction using Semantic Segmentation, In arXiv, 2017.04.同样是怎么利用image-level的labels,如人脸属性来做人脸属性分类的。
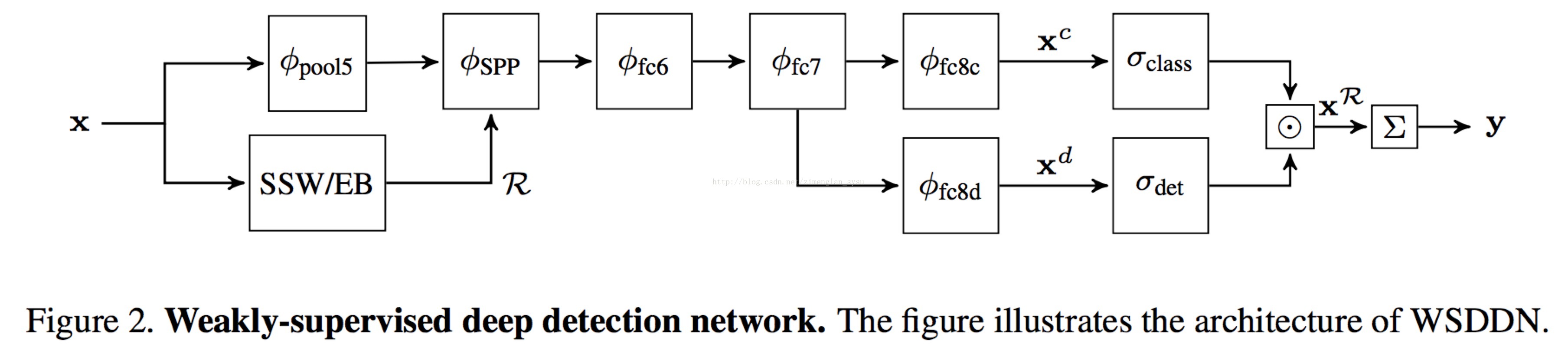
本博文除了该论文,还会涉及到另外一篇论文Weakly Supervised Deep Detection Networks. In CVPR, 2016.
废话少说,当然细节的东西还是各自看论文去。

由于这次的重点不是说论文里面的face parsing。至于怎么做face parsing的,还是看论文去。上面的图1的一个前提条件是,已经训练好face parsing net的了,而且由这个net来提供face的parsing maps。在做face attr分类时,parsing maps直接resize到对应conv feature maps的大小。
图1的b)和c)挺有意思的,但是从论文上看SSG的作用不大。不管怎样,SSG和SSP的目的是,利用parsing的结果来refine分类模型学到的feature map,使得模型能够充分利用spatial information(一般的做法是在最后一层做global pooling,这显然是spatial orderless的):即每个feature map只响应一个对应part region(这里用parsing来表示)。
笔者比较感兴趣的是SSP,所以在这里就说下Weakly Supervised Deep Detection Networks. In CVPR, 2016.

















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









