







前言
在爬取某些网页时,登陆界面时经常遇到的一个坎,而现在大多数的网站在登陆时都会要求用户填写验证码。当然,我们可以设计一套机器学习的算法去破解验证码,然而,验证码的形式多种多样,稍微变一下(有些甚至是手机短信验证),整套算法可能就完全无效了,所以去强行破解验证码是一个吃力不讨好的活。本文会以知乎网站为例,利用python中的request模块进行的一个模拟登陆,其中用到了reqeust.session下的cookies来跳过登陆这一环节。
方案详述
下面以模拟登陆知乎为例,利用python3.6进行详细的过程叙述,建议使用pycharm作为IDE。
首先,我们要将headers给设置好
agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
headers = {
"HOST": "www.zhihu.com",
"Referer": "http://www.zhihu.com",
"User-Agent": agent
}接着,用账号成功登陆一次知乎,并按下“F12”(Chrome浏览器),找到Resources下的Cookies,将显示的Cookies全都复制下来,即下图红框中的”Name”和”Value”。
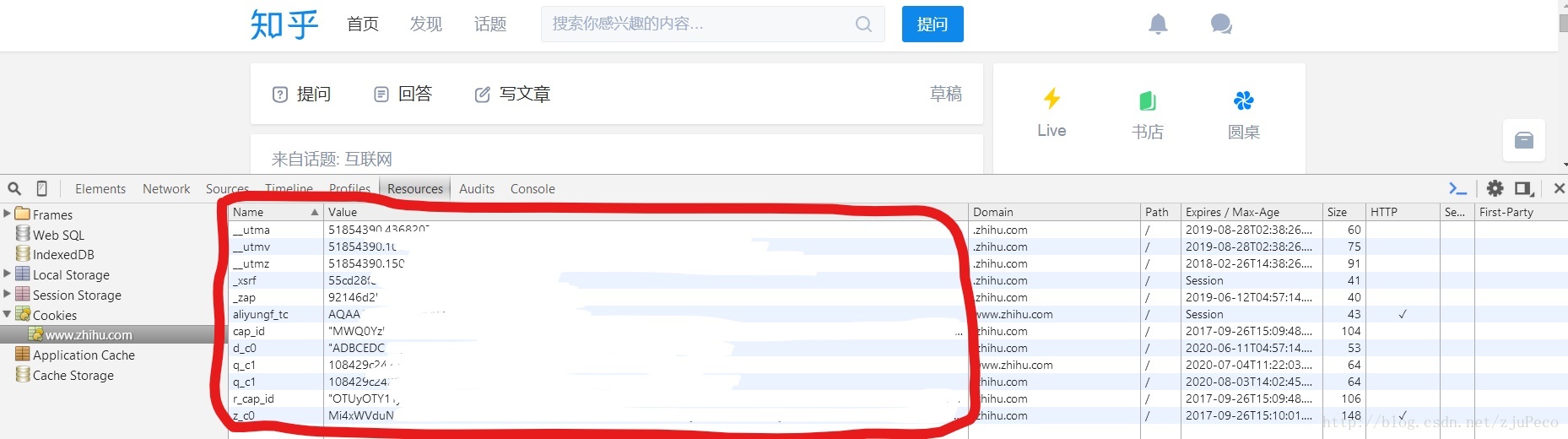
图中一些个人隐私信息已经擦去,图可能有点看不清,但应该能看明白,凑合一下吧~
将复制下来的Cookies写成字典的形式由于隐私问题,下面是不完整的Cookies。
cookies = {
"cap_id" : "MWQ0Yzk4NGI1Y2M4NG*********",
"r_cap_id" : "OTUyOTY1YjFjMDQ5NGEx*********",
"z_c0" : "Mi4xWVduN0FRQUFB**********",
"q_c1" : "108429c2422245a0********",
"d_c0" : "ADBCEDC-5guPTr*********",
"aliyungf_tc" : "AQAAAAaQE*************",
"_zap" : "92146d2b-**********",
"_xsrf" : "01124268-4638-***************",
"__utmz" : "51854390.15038440***********",
"__utmv" : "51854390.000**************",
"__utma" : "51854390.4***********"
}然后创建一个session对象,将headers和cookies赋给session
import Requests
session = Requests.session()
session.headers = headers
requests.utils.add_dict_to_cookiejar(session.cookies, cookies)其中,值得注意的是,session.headers可以是dict,所以直接赋值没问题,而session.cookies必须是<class ‘requests.cookies.RequestsCookieJar’>,所以要利用requests.utils.add_dict_to_cookiejar进行赋值。
好了,现在我们已经完事具备了,可以直接访问知乎了,就是这么简单。
url = "https://www.zhihu.com/"
response = session.get(url)比如这个时候,我们想把访问到的页面给保存下来,我们就可以这么干。
with open("test.html", "wb") as f:
f.write(response.text.encode('utf-8'))登陆进去了之后,就是想怎么来,就怎么来了~
这里还要补充一点就是,我们如果觉得把cookies写在源代码中不太雅观的话,可以将其保存到本地文件当中
import json
def save_cookies(cookies):
cookies_file = 'export.json'
with open(cookies_file, 'w') as f:
json.dump(cookies, f)保存成Json格式之后,可以在cookies过期之后,直接在文件当中修改cookies,要读取cookies也很方便
def load_cookies():
cookie_json = {}
try:
with open('export.json', 'r') as cookies_file:
cookie_json = json.load(cookies_file)
except:
print ("Json load failed")
finally:
return cookie_json值得注意的是,这个时候出来的cookies也是dict类型的,别忘了转换成cookiejar。
完整代码
我们可以把上面的代码整理一下,写成下面这样
文件1:用来存储cookies
import json
def save_cookies(cookies):
cookies_file = 'export.json'
with open(cookies_file, 'w') as f:
json.dump(cookies, f)
def main():
cookies = {
"cap_id" : "MWQ0Yzk4NGI1Y2M4NG*********",
"r_cap_id" : "OTUyOTY1YjFjMDQ5NGEx*********",
"z_c0" : "Mi4xWVduN0FRQUFB**********",
"q_c1" : "108429c2422245a0********",
"d_c0" : "ADBCEDC-5guPTr*********",
"aliyungf_tc" : "AQAAAAaQE*************",
"_zap" : "92146d2b-**********",
"_xsrf" : "01124268-4638-***************",
"__utmz" : "51854390.15038440***********",
"__utmv" : "51854390.000**************",
"__utma" : "51854390.4***********"
}
save_cookies(cookies)
if __name__ == '__main__':
main()文件2:用来模拟登陆
import requests
def load_cookies():
cookie_json = {}
try:
with open('export.json', 'r') as cookies_file:
cookie_json = json.load(cookies_file)
except:
print ("Json load failed")
finally:
return cookie_json
def main():
agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
headers = {
"HOST": "www.zhihu.com",
"Referer": "http://www.zhihu.com",
"User-Agent": agent
}
session = requests.session()
session.headers = headers
requests.utils.add_dict_to_cookiejar(session.cookies, load_cookies())
url = "https://www.zhihu.com/"
response = session.get(url)
with open("test.html", "wb") as f:
f.write(response.text.encode('utf-8'))
print ("Done")
if __name__ == '__main__':
main()注意本文创作时间,如果阅读时已经过了很久,代码可能不起效。
如有不足,还请指正~















 3999
3999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











