







我们用四期的时间,优化了最初的神经网络,代码量也层最初的一百四十行(包括注释)到了三百四十行。实际上在针对于某些特定的情况,还有一些优化的技术,这里做一个简单的介绍,以后不一定会用到,但是我自己觉得在看的过程中会加深对神经网络的理解。
Softmax神经网络
在介绍softmax之前,我先对第二期介绍的S曲线神经元系统时犯的错误做一个更正。我在第二期介绍S曲线神经元时,说S曲线函数σ的定义域是(-∞,+∞),值域是(0,1),我就以为输出值可以代表概率。实际上概率得保证几个输出值的和为1,而对于S曲线神经元系统是无法证明的。当然有了我以为的假冒伪劣产品,当然也就有真的用概率来做归一化的神经元系统了,这就是softmax神经元系统。
Softmax曲线神经元系统是这样的,对于:
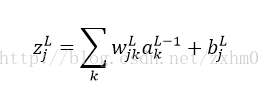
前馈算法为:
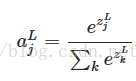
很明显有:
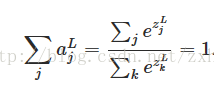
这在物理意义上就可以表示概率了。作者在书的第六章有用到Softmax神经网络。
双曲正切函数(Tanh)神经网络
跟上面的softmax神经网络一样,tanh神经网络相对于S曲线神经网络,也是改变了前馈算法:
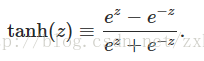
也就是:
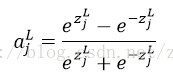
他的曲线如图:
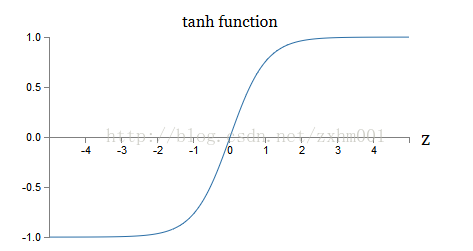
可以看到,tanh的输出值在(-1,1)之间,这是与S曲线最大的不同,其他的属性非常类似。
以此为启发,我们是不是可以造出这样一个前馈函数呢:
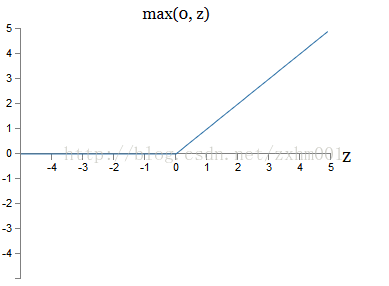
想一想这么一个前馈函数,是不是就可以避免我们在第五期说的训练变慢的问题,发散思维就是这一篇文章的目的了。
Hessian梯度下降算法
一直看下来的同学一定会有印象,成本函数C是根据w和b的变化而变化的,因为w和b都是多个值,为了讨论方便,我们只选取w。那就会有C=C(w)。根据多元函数的泰勒定理就有:
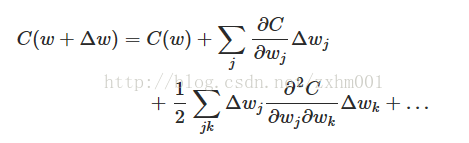
因为在梯度下降的过程中,只需要下降,对每次下降多少的精确程度要求并不严格,所以我们可以把这个泰勒展开的2项以后的部分省略掉,然后改写成矩阵形式:
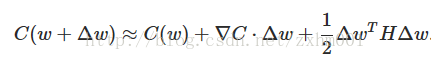
▽C是第三期里说过的梯度矩阵,H叫做Hessian矩阵,为了C变小,就是要使得C(w+Δw)<C(w)。我们可以取:
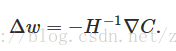
在实际使用过程中,一般还会配一个训练速率参数η,就成了:
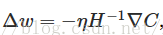
根据理论研究发现,Hessian算法比传统的梯度下降算法会更快的收敛。不过实际上挺少直接用的,因为Hessian矩阵相当大。比如一个神经网络中,w和b又10^7个,那么H就会有10^14个要素,计算量就会非常大了。不过,之后的各种针对梯度下降算法的改进,都是由Hessian算法启发的。
Momentum-based 梯度下降算法
这个算法是将梯度下降模拟成一个物理过程,如图:
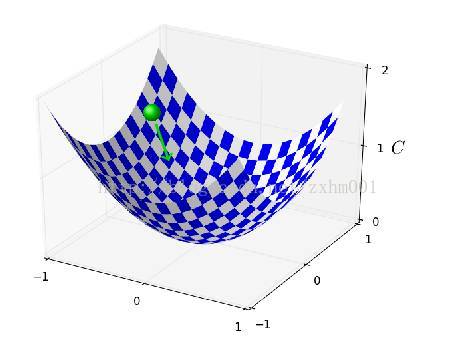
曲面就是成本函数C的曲面,Z坐标是C值,横纵坐标都是w(这里只表示了2个w,因为三位以上的空间实在是不好画出来),上面有个小球,我们的希望是小球滚动到谷底。现在引入一个速度v。
单位时间内,Δw=v。不过v是变化的,这次定义Δv=-η▽C。可以看到,在到谷底的过程中,速度是越来越快的,也就是训练速度会越来越大。不过到了最大速度的时候,就会迅速的远离谷底,所以还需要模拟现实情况,给一定的摩擦系数。所以Δv的定义就成了Δv=(u-1)v0 -η▽C。这里的u是一个0到1之间的数字。
这只是一个简单的启发性文章,就简单介绍到这里,其实可以看出来,神经网络的改进,并不是特别高大上的事情,原理上也不是很难,连我写第二期的时候都歪打正着碰着一个。
欢迎关注我的微信公众号获取最新文章:















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









