







我已经做了什么
到目前为止,我已经使用了
两种计算相似度的方式(皮尔逊和Jaccard系数)计算了歌曲相似度:
结果也存储在了相应的表:
- simmusic
- simmusicjaccard
而且能够有一种策略产生推荐列表,也设计了一种验证推荐列表的准确度的方式(
离线计算,验证推荐的准确性(失败)),具体如下所示(这是旧版本,下面会提出新版本):
- 对某一个用户收藏的歌曲
- 随机删除10%的歌曲,至少10首
- 产生推荐列表:歌曲10首
- 比对删除的歌曲和推荐的歌曲,记录推荐的歌曲内有多少首是原本被用户收藏的。
- 重复2-4过程N次。将3中N次记录的歌曲数相加再除以N。得到平均值
- 该平均值就表明了对这个用户推荐的准确度,是一个0到10的数。(后来发现再除以10,使结果在0-1之间,与第一首歌命中概率(意思见下)在一样的区间)
我也对几个用户进行按照上面的策略使用了由皮尔逊方式计算的歌曲相似度产生推荐列表,验证了准确性,产生了虽然不能说优秀,但是也算客观的结果,具体请看下篇博客。
我这次想做什么
上次之前验算了几个结果,可以用列表的方式,如下表所示(
2014年2月18日12:11:42发现代码bug,表格数据是错误的):
然而,用表格看起来非常累、不易发现规律。所以这次我想计算所有用户:
使用pylab画图:
precision是sql语句的关键字:
| 用户收藏的歌曲数 | 前5首有几首是用户收藏却被删除的歌 | 第一首是用户收藏却被删除的歌出现的概率 |
| 71 | 0.3 | 0 |
| 201 | 1.3 | 0.3 |
| 301 | 4 | 0.7 |
| 501 | 0.8 | 0 |
| 601 | 1.1 | 0.3 |
- 前10首有几首是用户收藏却被删除的歌,插入数据库,用图展示
- 第一首是用户收藏却被删除的歌出现的概率,插入数据库,用图展示
图展示的方式就用x坐标表示用户收藏歌曲的数量,用Y坐标表示有几首和概率,最后就会形成一幅二维图。
数据保存
插入数据库,我打算新建一张表,resultonlypearson:该推荐结果仅仅由pearson计算的歌曲相似度产生。该表的字段如下:
- id:自增长的id
- userid:int型 就是在user表中的id
- musiccount: int 型 用户收藏歌曲的数量
- accuracy:float型 前10首歌里面是用户收藏的歌曲的概率是多少(0-1之间)。由前10首有几首是用户收藏却被删除的歌,这个几首再除以10产生。也就是用户收藏的歌曲数处以10。
- firstRecom:float型 第一首是用户收藏却被删除的歌出现的概率(0-1之间)
建表的sql:
CREATE TABLE resultonlypearson(
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY ,
userid INT,
musiccount INT,
accuracy FLOAT,
firstRecom FLOAT
)执行计算
流程
这是新版本:
- 用户范围确定为收藏歌曲数大于或者等于50以上的所有用户(共3311位用户)
- 对每一个用户收藏的歌曲
- 随机删除10%的歌曲,至少10首
- 产生推荐列表:歌曲10首
- 比对删除的歌曲和推荐的歌曲,记录推荐的歌曲内有多少首是原本被用户收藏的,记录第一首歌是否所用户删除的,是就加一(称为第一首个命中)。
- 重复2-4过程N次。将3中N次记录的歌曲数相加再除以N,得到平均值。记录的第一首个命中个数处以N。
- 平均值就表明了对这个用户推荐的准确度,是一个0到10的数,我再将该数除以10,使结果在0-1之间,与第一首歌命中概率(意思见下)在一样的区间。
- 将准确度平均值和第一首歌命中概率加入插入数据库
缺陷:
- 由于我是用收藏歌曲数量在80-500的用户去计算的歌曲相似度,导致这部用户得到的准确率和第一首命中的概率应该会很高。我需要再去找一堆收藏歌曲数在80-500之间的用户,来计算准确度和第一首歌命中,我认为更有说服力。
N值的确定
代码
代码在另一份博客:
python:线程池的实现有完整的,在这里我只是贴出来计算部分:
def countaccuracy(favorites):
try:
repeatCount=100#定义对每一个用户重复多少次,每一次都会重新选择出测试集和训练集,然后产生推荐列表,比对结果之类的
#用数组列表,每一个装一个用户的。每个数组装一个字典。
users=[]
#下一句是连好数据库
conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='musicrecomsys',port=3306,unix_socket='/opt/lampp/var/mysql/mysql.sock')
#用拿到执行sql语句的对象
cur1=conn.cursor()
cur2=conn.cursor()
count1=cur1.execute('SELECT userid,COUNT( userid )FROM moresmallfavorites GROUP BY userid having COUNT( userid )=%s ORDER by COUNT( userid )',[favorites])
results1=cur1.fetchall()
for r1 in results1:
users.append({'userid':r1[0],'count':r1[1],'accuracy':0,'firstRecom':0})
for i in range(len(users)):
currentId=users[i]['userid']
firstRecom=0#推荐列表排名第一的是否是被我删除了的用户已经收藏的歌曲
accuracy=0#新的开始,使accuracy为0
musics=[]
#下句count1会记录返回了多少歌曲数
count1=cur1.execute('SELECT musicid FROM moresmallfavorites where userid= %s',[currentId])
results1=cur1.fetchall()
for r1 in results1:
musics.append(r1[0])#就拿到了该用户收藏的歌
#将收藏的歌曲集分为两部分:trainset和testSet,但先确定testSet的数量:testSetCount
testSetCount=int(count1*0.1)
if testSetCount<10:testSetCount=10
print '正在计算用户id为',users[i]['userid'],'收藏了:',users[i]['count']
for k in range(repeatCount):
simMusics={}#出现在这里非常重要,相当于将其每一个循环都要清空上一个循环的内容
testSet=[]#和上句的含义一样,之前我把这个写在最开头就导致了一个bug的出现,检查了很久才查出来
trainset=copy.deepcopy(musics)#这样,也相当于把清空了上一个循环的内容
for j in range(testSetCount):
deleteCount=randint(0,len(trainset)-1)#生成的随机数n:0<=n<=len(musics)
testSet.append(trainset[deleteCount])
trainset.pop(deleteCount)#删除指定位置的元素,那么trainset就变成了训练集
#取出musics里面所有的相似的歌,去重,排序,取出前10个
for j in range(len(trainset)):
count1=cur1.execute(' SELECT simmusicid,similarity FROM simmusic where musicid=%s',[musics[j]])
results1=cur1.fetchall()
for r1 in results1:
sim=simMusics.setdefault(r1[0],r1[1])#就拿到了该用户收藏的歌,但是用户收藏的两首歌的相似度歌重复的话,那么就相加。
if sim!=r1[1]:
#simMusics['r1[0]']=r1[1]+sim#这句错误,不要这样写,因为会产生一个key为'r1[0]'的键值对
simMusics[r1[0]]=r1[1]+sim#键是r1[0]所引用的值,而不是'r1[0]'
#sortedSimMusics是一个以值降序排列的含二元元组的列表
sortedSimMusics=sorted(simMusics.iteritems(), key=operator.itemgetter(1),reverse=True)#这时候是降序的
for j in range(10):#我们只验证推荐列表里面的前10首歌是否属于测试集testSet
if sortedSimMusics[j][0] in testSet:
accuracy+=1
if j==0:firstRecom+=1
accuracy/=float(repeatCount*10)#除以重复的次数,由于repeatCount是int类,转换为float(有小数).乘以10表示转为概率:从10首里面有几首是,转换为 10首里面百分之几的概率是
firstRecom/=float(repeatCount)
users[i]['accuracy']=accuracy
users[i]['firstRecom']=firstRecom
count2=cur1.execute("INSERT INTO resultonlypearson(userid,musiccount,accuracy,firstRecom) VALUES (%s,%s,%s,%s)",\
[users[i]['userid'],users[i]['count'],users[i]['accuracy'],users[i]['firstRecom']])
#print i,users[i]['userid'],users[i]['count'],users[i]['accuracy'],users[i]['firstRecom']
conn.commit()#必须要有这个提交事务,否则不能正确插入
del users
cur1.close()
conn.close()
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1]) 结果
全部计算完使用了时间:大约40个小时。结束时间是2月20日 16时16分49秒。如下图:

随便看看了结果,基本上非常糟糕,才0.026/0.05,想想也正常,一个推荐系统不可能那么简单。
随便看看了结果,基本上非常糟糕,才0.026/0.05,想想也正常,一个推荐系统不可能那么简单。
使用pylab画图:
test
先做一个简单的测试,代码如下:
from pylab import *
def test1():
x,y1,y2=[1,2],[0.4,0.33],[0.1,0.2]
plot(x,y1,'ro')#红色的圆点
plot(x,y2,'go')#绿色的圆点
show()
test1()
结果展示:

注意有刚好在左上方和左下方。
注意有刚好在左上方和左下方。
从此,我知道,只需要将我像画的数据装在列表数组内即可,注意一一对应。
x,y1,y2=[1,2],[0.4,0.33],[0.1,0.2]
比如如上,收藏歌曲在1首的用户,前10首有出现是用户原本收藏又被我删除的歌曲的概率是0.4,而排名第一首歌曲是用户收藏的歌曲的概率为0.1。
绘制推荐准确度和第一首歌曲命中的图像
x,y1,y2=[1,2],[0.4,0.33],[0.1,0.2]
比如如上,收藏歌曲在1首的用户,前10首有出现是用户原本收藏又被我删除的歌曲的概率是0.4,而排名第一首歌曲是用户收藏的歌曲的概率为0.1。
绘制推荐准确度和第一首歌曲命中的图像
代码如下,根据代码,我稍作为修改打印了三副图:
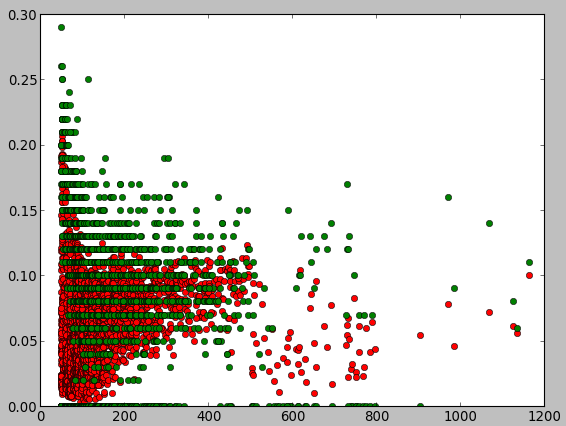
总得来说:
#-*- coding: utf-8 -*-
from pylab import *
import MySQLdb
def showDiagram():
conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='musicrecomsys',port=3306,unix_socket='/opt/lampp/var/mysql/mysql.sock')
cur1=conn.cursor()
count1=cur1.execute('SELECT musiccount,accuracy,firstRecom FROM resultonlypearson')
x,y1,y2=[],[],[]
results1=cur1.fetchall()
for r1 in results1:
x.append(r1[0])
y1.append(r1[1])
y2.append(r1[2])
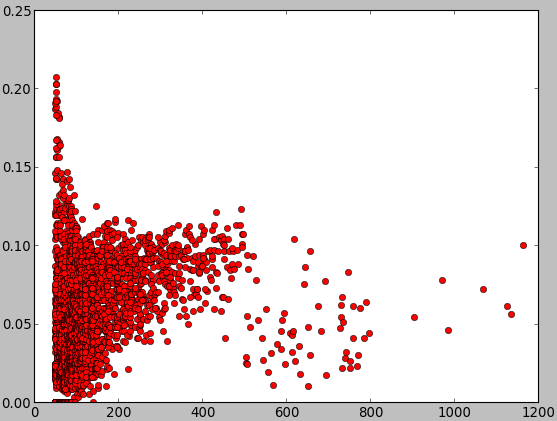
plot(x,y1,'ro')#红色为accuracy
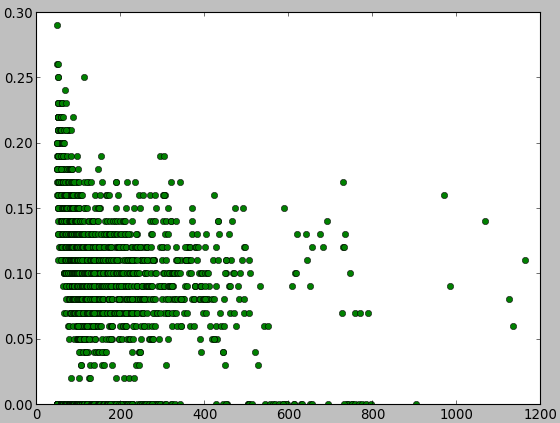
plot(x,y2,'go')#绿色是firstRecom
show()
cur1.close()
conn.close()
showDiagram()- 红色为accuracy
- 绿色是firstRecom
总得来说:
- 注意x轴那里,还有很多都是概率为0的情况
- 结果非常差,最高的一个才0.3
改进措施
结果非常差,果然还是我太天真了。改进从下面几个方式入手:
- 离线计算方案改进:产生推荐列表时的歌曲相似度计算应累加,而非替换:我已经叙述了一些方法了
- 相似度的计算到底用哪个公式,请参考论文/书籍再决定
- 核心还是学好机器算法,请参阅书籍:Pattern Recognition And Machine Learning(已经上传至网盘)
其他问题总结
linux查看进程的命令
比如我知道我运行的程序的关键字test(可以是一部分),那么我可以在终端输入:
类似的还有:
而grep是一种文本检索工具,能够使用正则表达式来检索文本,将匹配的内容找出来。
ps aux|grep test类似的还有:
ps ef|grep test而grep是一种文本检索工具,能够使用正则表达式来检索文本,将匹配的内容找出来。
precision是sql语句的关键字:
用法如下:
123.45:precision = 5 ,scale = 2
precision 数据长度
scale 小数长度
precision 数据长度
scale 小数长度
sql大于号必须在前面
错误语句:
SELECT userid,COUNT( userid )FROM moresmallfavorites GROUP BY userid having COUNT( userid )=>50 ORDER by COUNT( userid )SELECT userid, COUNT( userid )
FROM moresmallfavorites
GROUP BY userid
HAVING COUNT( userid ) >=50
ORDER BY COUNT( userid )
LIMIT 0 , 30引入pylab失败
非常奇怪,下段代码:
# -*- coding: cp936 -*-
from pylab import *
def test():
#读出配对成功的x坐标和y坐标
xdm,ydm=[1],[2]
#画绿点
plot(xdm,ydm,'go')
show()
test()
Traceback (most recent call last):
File "C:\Users\Administrator\Desktop\pylab.py", line 2, in <module>
from pylab import *
File "C:\Users\Administrator\Desktop\pylab.py", line 9, in <module>
plotagematches()
File "C:\Users\Administrator\Desktop\pylab.py", line 7, in plotagematches
plot(xdm,ydm,'go')
NameError: global name 'plot' is not defined后来我还是使用pycharm才能成功执行,如果我在控制台一句一句的写代码也没有问题,感觉好像上一段代码的pylab 就是没有引入。
源代码
计算代码二份是
- 计算代码和python:线程池的实现一样的,已经上传至网盘了
- 画图代码,很简单,没有上传到网盘















 2117
2117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









