







引言
增强学习这几篇博客在于学习增强学习中所获得知识的理解与回顾,如果想要深入学习增强学习,请参考后文所列出的资料和书籍。本文只用于复习与理解。
Introduction to Reinforcement Learning
1.领域交叉
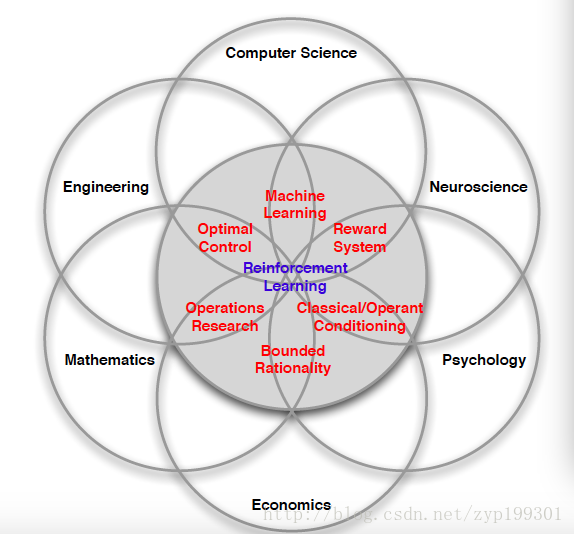
这张图详尽的描述了增强学习与各个领域的交集,可以很多领域都涉及增强学习过程,自认为RL可能是科学这个空间里最接近强人工智能的一项,看到训练出的AI完成游戏的过程,就像是训练一个新生儿。
2.RL与ML
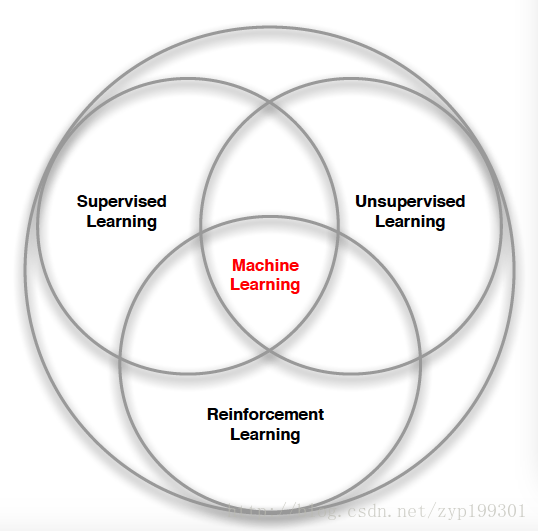
- RL中没有supervisor,只有一个reward signal
- Feedback is delay,not instantaneous
- Time really matter(在于agent做决策的过程其实是一个时序的决策序列)
- Agent’s actions affect the subsequent data it receives(这个一个动态的系统,agent不断的与外部进行着交互)
增强学习的过程在于优化决策序列
3.RL中的奖励机制
- A reward Rt is a scalar feedback signal
- Indicates how well agent is doing at step t
- the agent’s job is to maximize cumulative reward
最终目标都在于最大化累计回报
这里有两个问题值得深思,第一,如果奖励不及时,那么怎么计算评估每一个动作造成的奖励呢,这个问题在于需要分割出一个阶段,即定义阶段的开始与结束,然后为这个阶段定义奖励。第二,如果目标的奖励基于时间,也就是时间也是评价奖励的标准。这种情况下,每经历一个时间步长,都会有一个-1的奖励信号。这里的reward第一是最大化累计奖励,第二是最短时间。
4.决策序列制订
目标:选择合适的动作去最大化未来全部收益
这里同样为了理解。
- 这里的actions是一个长期的决策序列
- 奖励有delay
有可能要牺牲immediate reward来换取长期的高额收益。(这里很好理解,假设股票涨跌,短期跌无所谓,只在意投资组合一个阶段的累计收益,游戏也是一样)
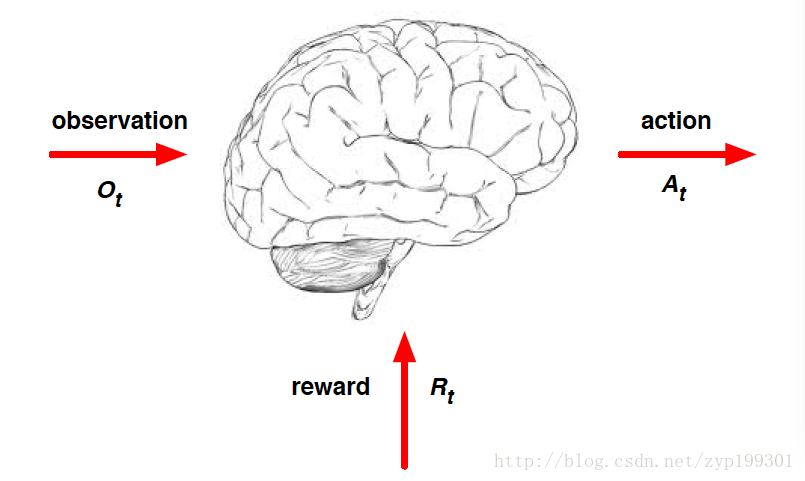
这张图描述的是Agent这个大脑的工作,接收O依赖R,做决策A
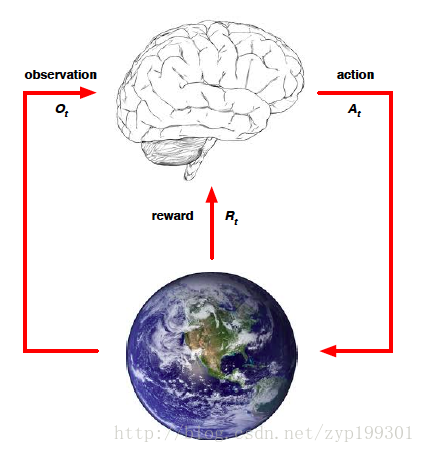
这张图描绘了Agent 与 当前Environment的交互
History and State
下面回顾一下重要的概念history和state
History
意味着观测,动作,奖励的一连串序列
数学表达为
Ht=A1,O1,R1,...At,Ot,Rt
他就意味着整个历史(说了等于没说),假设说是在游戏中的话,他意味着我们根据游戏画面的观测,做过的所有操作,产生的所有奖励。这个历史是有些用的,但是用处,主要是数据量太大了,对于即时的状态可能帮助不大。
State
状态是历史函数,used to determine what happens next
St=f(Ht)
- environment state
- agent state
- information state
An information state (a.k.a. Markov state) contains all useful
information from the history。
给出markov state的定义

这里有几个点我认为要关注一下。第一Once the state is known, the history may be thrown away。说明state对于当前任务的重要,历史已经当前做出判断没这么重要。The environment state Set is Markov.同样,The history Ht is Markov.
Fully Observable Environments
全观测环境,意义如其名。agent directly observes environment state。
在这里,很重要的一点,观测到的O等于Agent的状态,等于Envir的状态。这里我不是太理解这个过程,为什么这里具有马尔可夫性?这个全观测环境是一个MDP(Markov decision process).下个笔记重点关注一下这里。
Partially Observable Environments
agent indirectly observes environment。这里的agent state不等于environment state。这是一个POMDP(partially observable Markov decision process)。这时候,代理人必须建立自己的状态。通过他的历史,或者所处的环境状态,或者RNN.
Major Components of an RL Agent
- Policy: agent’s behaviour function(动作函数)
- Value function: how good is each state and/or action(价值函数)
- Model: agent’s representation of the environment
policy是state到action的映射。
- 确定性的政策: a=π(s)
- 随机性的政策:
π(a∣s)=P[At=a∣St=s]
价值函数value function是对于未来价值的预测,评估当前状态的好坏。其中,未来的收益是根据时间递减的,r为折现因子。
model 预测环境将会发生什么
P预测下一个state,R预测接下来的奖励。
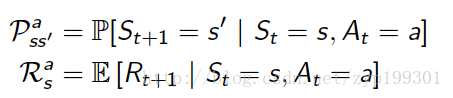
Categorizing RL agents
- value based
- no policy
- value funtion
- policy based
- policy
- no value function
- actor critic
- policy
- value function
- model-free
- policy and/or value function
- no model
- model-based
- policy and/or value function
- model
RL与动态规划的不同
RL的环境是未知的,agent与环境交互,并且不断change policy
planning 的环境是已知的,只计算利用他的model,通过计算改变自己的policy
Exploration and Exploitation
探索和利用困境。在于是利用当年的信息直接利用,还是不断探索获得更多信息。It is usually important to explore as well as exploit。
prediction and control
- prediction problem 问题在于给定policy,评估在政策下的未来情况。
- 而control problem 在于在所有的policy中找到最优的find the best.
这里也有一些不理解。后面的博客多关注些这里吧。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









