







转载于:http://blog.csdn.net/mzpmzk/article/details/52026843
作者:man_world
一、参数说明

W(l)ij :表示第 l−1 层的第 j 个特征到第 l 层第 i 个神经元的权值
b(l)ij :表示第 l−1 层的第 j 个特征到第 l 层第 i 个神经元的偏置(其中 j 恒为0,输入特征值 a(l)0 恒为1)
二、公式定义
- 激活函数(这里采用sigmoid函数来做分类): f(z)=11+e−z
- l 层神经元的状态值: z(l)=w(l)a(l−1)+b(l) ,表示一个神经元所获得的输入信号的加权和(即:特征的线性组合)
- l 层神经元的激活值: a(l)=f(z(l)) ,特征的非线性映射,可把 a(l) 看作更高级的特征。
- 损失函数(MSE):
J(W,b;x,y)=12∥∥a(l)−y(l)∥∥2=12∑nli=1[a(l)i−y(l)i]2


三、结合实例分析推导过程
-
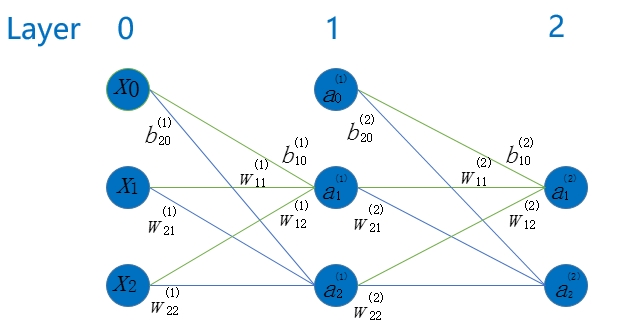
我们以一个两层神经元为例对推导过程详细分析
- 输入特征和输出类标值分别为: [x0,x1,x2]′=[1,0.05,0.1]′;y(2)=[0,1]′
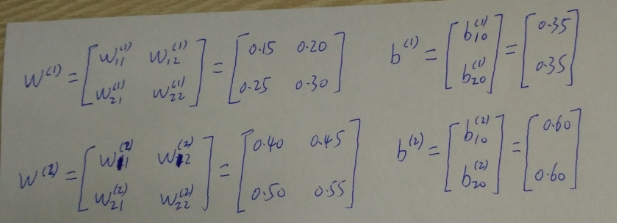
- 各参数初始化值分别为:
-
梯度值的推导



第一个公式的中间部分 (Θ(L−1))Tδ(L) 样式很熟悉吧,就是线性回归算法的预测函数的样式。
四、梯度检验、梯度消失和梯度爆炸问题
参考NNDL第五章:神经网络为什么难训练?
五、权重的更新
权重是同时更新的!
UFLDL—-Backpropagation Algorithm
六、QA
- 为什么算个偏导数就能说损失函数沿着梯度方向下降得最快?
- 引入反向传播算法的原因?
答:这是为了方便计算损失函数的偏导数,也就是首先计算最后一层的残差,然后再一层一层的反向求出各层的误差,直到倒数第二层。 - How to predict?
- softmax 回归的损失函数,以及它是怎么做预测的?
- 神经网络的决策函数,损失函数,参数学习算法?
- 搭建网络的大体框架—结合超参数的选择p98
-
几层神经网络可以学出其高级特征???















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









