






# 第一章绪论
## 1.1引言
机器学习所研究的主要内容,是关于在计算机上从数据中产生"模型"(model)的算法,即"学习算法"(learning algorithm).在面对新的情况时(例如看到一个没剖开的西瓜),模型会给我们提供相应的判断(例如好瓜).如果说计算机科学是研究关于"算法"的学问,那么类似的,可以说机器学习是研究关于"学习算法"的学问.
## 1.2基本术语
- 数据集:包含多条记录,每条记录描述一个事件或对象(如西瓜)。
- 示例/样本:每条记录称为一个示例,反映对象的性质。
- 属性/特征:描述对象表现的事项,如"色泽"、"根蒂"、"敲声"。
- 属性值:属性上的具体取值,如"青绿"、"乌黑"等。
- 属性空间:由属性构成的空间,用于描述对象。
- 特征向量:每个示例在属性空间中的坐标表示。
- 维数:样本的特征数量,决定了样本空间的维度。
- 学习/训练:从数据中得出模型的过程,通常通过执行某种学习算法。
- 训练数据:用于训练模型的数据,每个样本称为“训练样本”。
- 训练集:由多个训练样本组成的集合。
- 假设:学得的模型反映的数据潜在规律。
- 真相/真实:数据中存在的实际规律,学习过程的目标是找出或逼近这个真相。
- 学习器:可视为学习算法在给定数据和参数上的实例化。
- 预测:模型的目的之一是判断未剖开的西瓜是否为“好瓜”。
- 标记:关于示例结果的信息,如“好瓜”或“坏瓜”。
- 样例:拥有标记信息的示例,通常用 (Xi, Yi) 表示,其中 Yi 是示例 Xi 的标记。
- 标记空间:所有可能标记的集合,也称为输出空间。
-
分类 (Classification):用于预测离散值,例如将样本分为“好瓜”或“坏瓜”。根据类别数量,可以分为:
- 二分类 (Binary Classification):只有两个类别,通常称一个为“正类”(Positive Class),另一个为“负类”(Negative Class)。
- 多分类 (Multi-class Classification):涉及多个类别,类别数目大于2。
-
回归 (Regression):用于预测连续值,例如西瓜的成熟度(如0.95、0.37)。
-
映射关系:通过训练集 ({(X_1, Y_1), (X_2, Y_2), \ldots, (X_m, Y_m)}) 学习一个从输入空间 (X) 到输出空间 (Y) 的映射 (f: X \rightarrow Y)。
-
测试 (Testing):使用已学得的模型对新的样本进行预测,称为“测试样本”。得到的预测标记为 (ν = f(x))。
-
聚类 (Clustering):将数据自动分组为多个“簇”,如“浅色瓜”和“深色瓜”。聚类不需要标记信息,主要用于发现数据中的潜在结构和规律。
-
监督学习 (Supervised Learning):
- 定义:利用带标签的训练数据来学习模型。目标是根据输入特征预测输出标签。
- 代表性任务:分类(如识别图像中的物体)和回归(如预测房价)。
- 泛化能力:良好的模型应能够对未见过的新样本进行准确预测。
-
无监督学习 (Unsupervised Learning):
- 定义:使用没有标签的数据进行学习,主要用于发现数据的内在结构。
- 代表性任务:聚类(如将客户分群)和降维(如主成分分析)。
- 适用性:虽然没有标签,但希望学习出的模式能适用于新样本。
-
泛化能力 (Generalization):
- 强泛化能力的模型不仅在训练集上表现良好,还能在未见过的数据上保持较高的表现。
- 泛化能力依赖于模型的复杂程度、训练数据的质量及数量等因素。
-
独立同分布 (i.i.d.):
- 样本假设为独立同分布的前提,有助于理论分析和模型构建。
- 这意味着每个样本都是从同一概率分布中独立抽取的,相互之间没有关联。
-
样本数量的重要性:
- 通常,训练样本越多,模型学习到的数据特征越全面,从而提升泛化能力。
- 然而,质量优于数量,数据的多样性和代表性对模型效果也至关重要。
## 1.3假设空间
归纳(induction)与横绎(deductio丑)是科学推理的两大基本手段.前者是从特殊到一般的"泛化"(generalization)过程,即从具体的事实归结出一般性规律;后者则是从一般到特殊的"特化"(specializatio叫过程,即从基础原理推演出具体状况.
归纳学习有狭义与广义之分?广义的归纳学习大体相当于从样例中学习,而狭义的归纳学习则要求从训练数据中学得概念(concept),因此亦称为"概念学习"或"概念形成"
## 1.4归纳偏好
在机器学习中,归纳偏好(inductive bias)是指学习算法在面对多个可能的假设时,倾向于选择某种类型的假设的倾向。这种偏好会影响最终模型的选择和性能。
通过引入归纳偏好,比如假设相似样本的输出也应该相似,算法可以更加倾向于选择那些平滑、简单的模型(如你提到的曲线A),而不是过于复杂或噪声较大的模型(曲线B)。这种偏好不仅提高了模型的稳健性,还能提升其在未知数据上的泛化能力。
在学习算法中,归纳偏好是指算法在庞大的假设空间中选择适合的模型时所依据的原则或倾向。虽然奥卡姆剃刀原则(即选择最简单的假设)是一个常用的指导思想,但并不是唯一的标准。不同的情况可能需要不同的偏好策略。
1. 奥卡姆剃刀的局限性
奥卡姆剃刀强调简单性,但“简单”在不同上下文中可能有不同的解释。例如,在处理西瓜问题时,两个假设的复杂性并不容易量化。简单性不仅仅涉及数学表达式的复杂度,还包括特征的数量、模型的可解释性等。
2. 泛化能力的考量
学习算法的最终目标是提升泛化能力,即在未见过的数据上表现良好。即使某个算法在特定数据集上表现优秀,也不能保证其在其他数据集上同样有效。因此,在选择模型时,不仅要关注训练集上的拟合情况,还要通过交叉验证等方法评估模型的泛化能力。
“没有免费的午餐”定理(No Free Lunch Theorem, NFL)是机器学习领域中的一个重要概念。它强调了在所有可能的问题上,不同的学习算法在期望性能上是相同的,也就是说,没有一种算法能够在所有问题中都优于其他算法。这一理论揭示了机器学习的一个核心挑战:算法的效果往往与具体问题的特性密切相关。
理解NFL定理
-
均匀分布假设: NFL定理的前提是所有可能的问题出现的机会是相同的。在这种情况下,无论是复杂的算法还是简单的随机猜测,它们的表现都趋于一致。这意味着,若没有对特定问题的先验知识,任何学习算法都无法获得显著的优势。
-
实际应用中的重要性: 尽管NFL定理表明在理论上所有算法的期望性能是相同的,但在实际应用中,我们通常只关注特定的问题和场景。例如,在某个特定的分类任务中,针对特定数据集的特征、分布和噪声,某些算法可能表现得比其他算法好得多。这就引出了一个重要的观点:选择合适的算法需要考虑具体问题的性质。
-
问题的特定性: 在现实世界中,问题通常不是均匀分布的。我们常常面对的是特定类型的数据和任务,比如图像识别、自然语言处理等,这些问题具有各自的特征和挑战。因此,尽管NFL定理在理论上成立,但我们可以通过深入理解问题领域和数据特性来选择和优化算法,从而获得更好的性能.
## 1.5 发展历程
机器学习是人工智能(artificialintelligence)研究发展到一定阶段的必然产物.二十世纪五十年代到七十年代初,人工智能研究处于"推理期",那时人们以为只要能赋予机器逻辑推理能力,机器就能具有智能.这一阶段的代表性工作主要有A.Newell和H.Simon的"逻辑理论家"(Logic Theorist)程序以及此后的"通用问题求解"(General Problem Solving)程序等,这些工作在当时取得了令人振奋的结果.例如"逻辑理论家"程序在1952年证明了著名数学家罗素和怀特海的名著《数学原理》中的38条定理7在1963年证明了全部52条定理,特别值得一提的是,定理2.85甚至比罗素和怀特海证明得更巧妙.A. Newell和H.Simon因为这方面的工作获得了1975年圈灵奖.然而?随着研究向前发展,人们逐渐认识到,仅具有逻辑推理能力是远远实现不了人工智能的-E. A. Feigenbau日1等人认为,要使机器具有智能?就必须设法使机器拥有知识.在他们的倡导下,从二十世纪七十年代中期开始,人工智能研究进入了"知识期"在这一时期,大量专家系统问世,在很多应用领域取得了大量成果.E.A.Feigenbaum作为"知识工程"之父在1994年获得图灵奖.但是,人们逐渐认识到,专家系统面临"知识工程瓶颈",简单地说,就是由人来把知识总结出来再教给计算机是相当困难的.于是?一些学者想到,如果机器自己能够学斗知识该多好!
事实上,图灵在1950年关于图灵测试的文章中?就曾提到了机器学习的可能;二十世纪五十年代初已有机器学习的相关研究,例如A.Samucl著名的跳棋程序.五十年代中后期7基于神经网络的"连接主义"(conncctionism)学习
开始出现?代表性工作有F.Rosenblatt的感知机(Perceptron)、B.Widrow的Adaline等.在六七十年代,基于逻辑表示的"符号主义"(symbolism)学习技术建勃发展,代表性王作有P.Winston的"结构学习系统"、R.S. Michalski 等人的"基于逻辑的归纳学习系统'人E.B. Hunt等人的"概念学习系统"等;以决策理论为基础的学习技术以及强化学习技术等也得到发展,代表性份工作有N.J. Nilson的"学习机器"等·二十多年后红极一时的统计学习理论的
一些奠基性结果也是在这个时期取得的.
1980年夏,在美国卡耐基梅隆大学举行了第一届机器学习研讨会(IWML);同年,((策略分析与信息系统》连出三期机器学习专辑;1983年,Tioga山版社出版了R.S. Michalski、J.G. Carbonell和T.Mitchell主编的《机器学习:一种人工智能途径))[Michalski et al., 1983],对当时的机器学习研究工作进行了总结;1986年7第→本机器学习专业期刊MachineLeαTηing创刊;1989年,人工智能领域的权威期刊ArtificialIntelligence出版机器学习专辑,刊发了当时一些比较活跃的研究工作?其内容后来出现在J.G. Carbonell主编、MIT出版社1990年的《机器学习:范型与方法>>[Carbonell, 1990]一书中.总的来看,二十世纪八十年代是机器学习成为一个独立的学科领域、各种机器学习技术
百花初绽的时期.
R. S. Michalski等人[Michalskiet al., 1983]把机器学习研究划分为"从样例中学习""在问题求解和规划中学习""通过观察和发现学习""从指令中学习"等种类;E. A. Feigenbaum等人在著名的《人工智能手册>>(第二卷)[Cohen and Feigenbau日1,1983]中,则把机器学习划分为"机械学习""示教学习""类比学习"和"归纳学习"机械学习亦称"死记硬背式学习",即把外界输入的信息全部记录下来,在需要时原封不动地取出来使用?这实际上没有进行真正的学习?仅是在进行信息存储与检索;示教学习和类比学习类似于R.S. Michalski等人所说的"从指令中学习"和"通过观察和发现学习"归纳学习相当于"从样例中学习",即从训练样例中归纳出学习结果.二十世纪八十年代以来,被研究最多、应用最广的是"从样例中学习"(也就是广义的归纳学习),它涵盖了监督学习、无监督学习等,本书大部分内容均属此范畴.下面我们对这方面主流技术的演进做一个简单回顾.
在二十世纪八十年代,"从样例中学习"的一大主流是符号主义学习,其代表包括决策树(decisiontree)和基于逻辑的学习.典型的决策树学习以信息论为基础,以信息娟的最小化为目标,直接模拟了人类对概念进行判定的树形流程.基于逻辑的学习的著名代表是归纳逻辑程序设计(InductiveLogic Programming,简称ILP),可看作机器学习与逻辑程序设计的交叉,它使用一阶逻辑(即谓词逻辑)来进行知识表示,通过修改和扩充逻辑表达式(例如Prolog表达式)来完成对数据的归纳.符号主义学习占据主流地位与整个人工智能领域的发展历程是分不开的.前面说过,人工智能在二十世纪五十到八十年代经历了"推理期"和"知识期",在"推理期"人们基于符号知识表示、通过演绎推理技术取得了很大成就,而在"知识期"人们基于符号知识表示、通过获取和利用领域知识来建立专家系统取得了大量成果,因此,在"学习期"的开始?符号知识表示很自然地受到青睐.事实上7机器学习在二十世纪八十年代正是被视为"解决知识工程瓶颈问题的关键"而走上人工智能主舞台的.决策树学习技术由于简单易用,到今天仍是最常用的机器学习技术之一.ILP具有很强的知识表示能力,可以较容易地表达出复杂数据关系,而且领域知识通常可方便地通过逻辑表达式进行描述,因此,ILP不仅可利用领域知识辅助学习,还可通过学习对领域知识进行精化和增强;然而,成也萧何、败也萧何,由于表示能力太强,直接导致学习过程面临的假设宅间太大、复杂度极高?因此,问题规模稍大就难以有效进行学习,九十年代中期后这方面的研究相对陷入低潮.
二十世纪九十年代中期之前,"从样例中学习"的另一主流技术是基于神经网络的连接主义学习.连接主义学习在二十世纪五十年代取得了大发展,但因为早期的很多人工智能研究者对符号表示有特别偏爱?例如图灵奖得主ESimon曾断言人工智能是研究"对智能行为的符号化建模",所以当时连接主义的研究未被纳入主流人工智能研究范畴.尤其是连接主义自身也遇到了很大的障碍?正如图灵奖得主M.Minsky丰11S. Papert在1969年指出,(当时的)神经网络只能处理线性分类7甚至对"异或"这么简单的问题都处理小了.1983年,
J. J. Hopfield利用神经网络求解"流动推销员问题"这个著名的NP难题取得重大进展,使得连接主义重新受到人们关注.1986年,D. E. Rumelhart等人重新发明了著名的BP算法,产生了深远影响.与符号主义学习能产生明确的概念表示不同,连接主义学习产生的是"黑箱"模型,因此从知识获取的角度来看?连接主义学习技术有明显弱点;然而,由于有BP这样有效的算法,使得它可以在很多现实问题上发挥作用.事实上,BP一直是被应用得最广泛的机器学习算法之一.连接主义学习的最大局限是其"试错性'p;简单地说?其学习过程涉及大量参数,而参数的设置缺乏理论指导,主要靠于工"调参"夸张一点说,参数调节上失之毫厘,学习结果可能谬以千里.
二十世纪九十年代中期"统计学习"(statistical learning)闪亮登场并迅速占据主流舞台,代表性技术是支持向量机(SupportVector Machine,简称SVM)以及更一般的"核方法"(kernel methods).这方面的研究早在二十世纪六七十年代就已开始,统计学习理论[Vapnik,1998]在那个时期也已打下
了基础?例如V.N. Vapnik在1963年提出了"支持向量"概念,他和A.J. Chervonenkis在1968年提出VC维,在1974年提出了结构风险最小化原则等.但直到九十年代中期统计学习才开始成为机器学习的主流,一方面是由于有效的支持向量机算法在九十年代初才被提出,其优越性能到九十年代中期在文本分类应用中才得以显现;坤一方面,正是在连接主义学习技术的局限性凸显之后,人们才把目光转向了以统计学习理论为直接支撑的统计学习技术.事实上,统计学习与连接主义学习有密切的联系.在支持向量机被普遍接受后,核技巧(kerneltrick)被人们用到了机器学习的几乎每一个角落,核方法也逐渐成为机器学习的基本内容之一.
有趣的是?二十一世纪初,连接主义学习又卷土重来,掀起了以"深度学习"为名的热潮.所谓深度学习?狭义地说就是"很多层"的神经网络.在若干测试和竞赛上,尤其是涉及语音、图像等复杂对象的应用中,深度学习技术取得了优越性能.以往机器学习技术在应用中要取得好性能,对使用者的要求较高;而深度学习技术涉及的模型复杂度非常高,以至于只要下工夫"调参把参数调节好?性能往往就好.因此,深度学习虽缺乏严格的理论基础,但它显著降低了机器学习应用者的门槛,为机器学习技术走向工程实践带来了便利.那么?它为什么此时才热起来呢?有两个基本原因:数据大了、计算能力强了深度学习模型拥有大量参数?若数据样本少,则很容易"过拟合".如此复杂的模型、如此大的数据样本7若缺乏强力计算设备,根本无法求解.恰由于人类进入了"大数据时代习技术焕发又一春.有趣的是,神经网络在二十世纪八十年代中期走红,与当时Intel x86系列微处理器与内存条技术的广泛应用所造成的计算能力、数据访存效率比七十年代有显著提高不无关联.深度学习此时的状况,与彼时的神经网络何其相似.
需说明的是?机器学习现在已经发展成为一个相当大的学科领域,本节仅是管中窥豹,很多重要技术都没有谈及,耐心的读者在读完本书后会有更全面的了解.
## 1.6应用现状
在大数据时代,数据的获取和存储变得更加容易,但如何有效地分析和利用这些数据则成为一个重大挑战。机器学习作为一种能够从数据中学习和提取模式的技术,正好满足了这一需求。它不仅在计算机视觉和自然语言处理等领域展现出卓越的性能,还深刻影响着生物信息学、金融分析、智能交通等多个交叉学科。
随着研究手段的演变,从传统的理论与实验结合,逐步向重视计算和数据分析转变,机器学习的重要性愈发突出。各国政府和科研机构也纷纷加大对机器学习的研究投入,以推动科技进步与国家安全。
未来,随着技术的不断进步和应用场景的不断扩展,机器学习将继续在数据科学领域发挥关键作用,帮助我们更好地理解和利用数据,从而实现更深层次的科学发现和技术突破。
# 第二章 模型评估与选择
## 2.1经验误差与过拟合
过拟合与欠拟合
-
过拟合 (Overfitting): 当模型在训练集上表现极好(例如训练误差几乎为零),但在新样本上表现不佳时,我们称该模型发生了过拟合。这通常是因为模型复杂度过高,学习到了训练数据中的噪声和特定特征,而不是普遍规律。过拟合会导致泛化性能下降,即在未知数据上的预测准确性降低。
-
欠拟合 (Underfitting): 与过拟合相对,欠拟合指的是模型未能捕捉到训练数据中的重要结构或模式,导致训练误差和测试误差都很高。这通常发生在模型过于简单,无法充分表达数据的真实分布时。
模型选择与调优
为了避免过拟合和欠拟合,通常会采取以下措施:
-
交叉验证: 使用交叉验证技术来评估模型的泛化能力,通过将数据分成多个子集进行训练和验证,以获得更稳健的模型性能评估。
-
正则化: 在损失函数中加入正则化项,限制模型参数的大小,从而降低模型复杂度,帮助防止过拟合。
-
选择合适的模型复杂度: 根据数据的特点选择合适的模型,比如决策树的深度、神经网络的层数等,避免模型过于复杂或简单。
-
早停法: 在训练过程中监控验证集的性能,当发现模型在验证集上的性能开始下降时,停止训练。
## 2.2评估方法
为什么测试集要与训练集互斥?
-
避免过拟合的影响:如果测试集中的样本曾经在训练过程中出现,模型可能会记忆这些样本的特征而非真正学习其背后的规律。这会导致在评估时表现得很好,但实际泛化能力较弱。
-
真实反映泛化能力:测试集应该能够代表未见数据的分布,确保评估结果能够反映模型在真实世界中的表现。就像学生考试,如果出题与练习题相同,学生的高分并不能真实反映他们对知识的掌握程度。
数据集的划分方法
-
留出法 (Hold-Out):
- 将数据集划分为训练集和测试集,一般比例为70%/30%或80%/20%。
- 保持类别比例的一致性,避免引入偏差。
-
分层采样 (Stratified Sampling):
- 特别适用于分类任务,可以确保训练集和测试集中的每个类别的样本比例与整体数据集一致。
-
重复多次划分:
- 为了获得更稳定的评估结果,可以进行多次随机划分,平均多个实验的结果以减少偶然性带来的影响。
- 交叉验证法
-
k折交叉验证
- 将数据集 ( D ) 划分为 ( k ) 个大小相似的互斥子集 ( D_1, D_2, \ldots, D_k )。
- 每次选择 ( k-1 ) 个子集作为训练集,剩下的一个子集作为测试集。
- 这种过程重复 ( k ) 次,每个子集都至少作为一次测试集。
- 最终的评估结果通常是这 ( k ) 次测试结果的均值。
-
常用的 k 值
- 常用的 ( k ) 值有 5、10 和 20。其中,10 折交叉验证较为普遍。
-
留一法 (Leave-One-Out, LOO)
- 当 ( k ) 等于样本总数 ( m ) 时,得到留一法。
- 这种方法每次使用 ( m-1 ) 个样本进行训练,1 个样本进行测试。
- 虽然留一法的评估结果通常较为准确,但在大规模数据集上计算开销很大。
-
随机化和重复
- 为了减小因样本划分带来的不稳定性,通常会随机划分数据集并重复 ( p ) 次交叉验证。
- 最终评估结果是多次重复的均值。
-
缺点
- 留一法虽然准确,但对于大数据集的训练时间开销很高。
- 并非所有情况下,留一法的结果都比其他方法更优,存在“没有免费的午餐”定理的影响。
-
-
自助法(Bootstrap Method)
自助法是一种通过重复抽样来评估模型性能的统计方法,它特别适用于样本量较小的情况。以下是自助法的主要特点和步骤:
1. 自助采样
- 从原始数据集 ( D ) 中随机抽取 ( m ) 次,每次抽取时将样本放回,这样同一个样本可以被多次抽到。
- 经过 ( m ) 次抽样后,形成新的数据集 ( D' ),这个数据集可能包含重复的样本。
- 在自助法中,由于样本可以重复抽取,因此在 ( D ) 中的一部分样本可能不会出现在 ( D' ) 中。
- 通过计算,可以得出约 36.8% 的样本在 ( D' ) 中不会出现,这些样本可以用作测试集,即 ( D \setminus D' )。
- 使用未出现在 ( D' ) 中的样本对模型进行评估,这种方式称为“包外估计”(out-of-bag estimate)。
- 这种估计方式有效地利用了所有可用样本,避免了因训练集和测试集规模不同带来的偏差。
调参与最终模型
常用的调参方法
-
网格搜索(Grid Search):
- 在每个参数的预设范围内,建立一个网格,计算所有参数组合的模型性能。这种方法简单直观,但计算量大,尤其是参数较多时。
-
随机搜索(Random Search):
- 与网格搜索不同,随机搜索在指定的范围内随机选择参数组合进行评估。这种方法在时间和资源有限的情况下能够有效找到较优的参数配置。
-
贝叶斯优化(Bayesian Optimization):
- 利用概率模型来优化超参数,通过构建目标函数的代理模型来进行智能选择,从而减少评估次数并提高效率。
-
交叉验证(Cross-Validation):
- 将训练集划分为多个子集,轮流使用其中一部分作为验证集,其余部分作为训练集。这种方法可以更好地评估模型的泛化能力。
模型评估过程
-
数据划分:
- 通常将数据集分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调参和模型选择,而测试集用于最终评估模型的泛化能力。
-
模型选择与调参:
- 根据验证集上的表现来选择最佳的模型和参数配置,确保选择的模型在未见过的数据上也能有良好的表现。
-
最终训练:
- 一旦确定了模型和参数配置,使用整个数据集(即所有样本)重新训练模型,以充分利用可用数据,输出最终的模型。
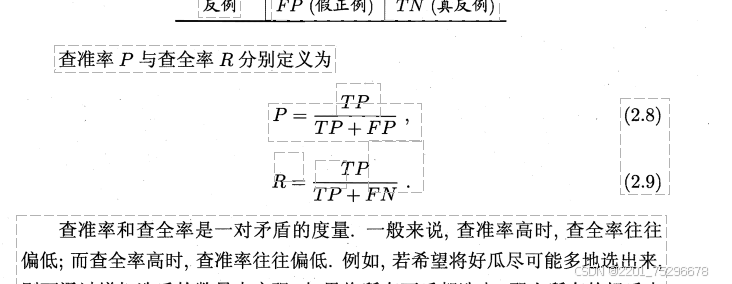
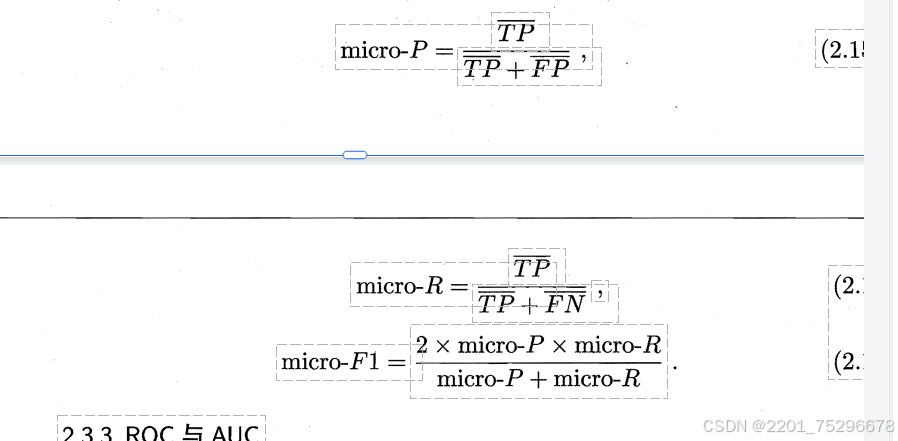
## 2.3性能度量








## 2.4比较检验
2.4.1假设检验



2.4 .2交叉验证t检验
-
k 折交叉验证:
- 将数据集分为 k 个相同大小的折叠。
- 每次选择一个折叠作为测试集,其余 k-1 个折叠作为训练集进行模型训练。
- 重复 k 次,记录每次的测试错误率 (E_A) 和 (E_B) 。
-
成对 t 检验:
- 对于每一对折叠,计算其测试错误率的差值 (d_i = E_{A,i} - E_{B,i})。
- 计算这些差值的均值 (\mu_d) 和方差 (\sigma^2_d)。
- 使用 t 检验来判断是否可以拒绝“两个学习器的性能相同”这一假设。
-
5x2 交叉验证:
- 进行 5 次 2 折交叉验证,每次都对数据集进行随机打乱,以减少不同折叠之间的重叠。
- 从每次的 2 折交叉验证中获取两对测试错误率,计算其平均值和方差。
- 结果将遵循自由度为 5 的 t 分布。
2.4.3 McNemar检验

2.4.4 Friedman检验与N凹nenyl后续检验
使用Friedman检验来判断这些算法是否性能都相同.若相同,则它们的平均序值应当相同.假定我们在N个数据集上比较k个算法,令?飞表示第4个算法的平均序值,为简化讨论,暂不考虑平分序值的情况,则η服从正态分布?其均值和方差分别为(k+ 1)/2和(k2-1)/12.变量


## 2.5偏差与方差



















 3280
3280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









