







目录
1.基本术语
1.1算法
算法就是从数据当中学得或者得出的模型的具体方法。例如在书中例子提到的线性回归,多项式回归,决策树等等这些就是所谓的算法。
1.2模型
模型就是通过算法对数据进行处理后所得出的结果就是模型。通常是一些具体的函数或者抽象成函数的形式。例如线性回归当中的一元一次线性回归算法产出的结果例如:y = ax+b。
1.3样本
样本在我看来就是书中所描述的那一大堆西瓜当中的一个具体西瓜,而在计算机当中通常把这些样本的特征或者属性用向量来进行表示,这样计算机才能理解并计算。那么这些向量或者叫做样本的实例的每一个属性或者特征,在向量的角度下也就叫做维度。补充向量的元素用 ” ;“表示列向量,” ,“表示行向量。当然这些数据
1.4标记
标记就是机器学习本质就是通过数据加算法得出的模型来得到样本中在某个方面是否存在潜在的规律。

上例当中的y即是所谓的标记。
1.5样本空间
样本空间就是指这些特征向量所要存放的地方。
1.6标记空间
标记空间就是指所得出的标记的所在空间。
1.7机器学习分类:
-
1.7.1标记取值为离散:
-
分为”分类“,即y = 好瓜,坏瓜,就只有两种类别。
-
-
1.7.2标记取值为连续:
-
分为”回归“,比如瓜的成熟度:0.42,0.99等,它不能是一个将其所有的结果直接罗列,通常只有一个取值范围。
-
-
1.7.3是否用到标记信息:
-
监督学习:在模型训练阶段有用到标记信息的,例如线性模型。
-
无监督学习:即没有用到标记信息,例如聚类。
-
1.8数据集
数据集就是这些样本的一个集合。比如我上面说的那一个具体的西瓜是样本,那么这一堆西瓜在这里就叫做数据集。
表示。那么在这个数据集当中所有的样本都必须含有相同个数的特征。
1.9泛化
我们通过机器学习将我们已知的进行消化后,从而对我们未知的进行一个较为精确的判断,对未知事物的判断的准确与否才是衡量这个模型的好坏的标准。这种能力我们称为泛化能力。
1.10分布
-
此处的分布即为高数当中的概率分布,就是样本空间服从某个分布“D”,就是说这些样本都能在分布当中独立的采样到,如果我们的样本越多那么我们就能在服从某个分布“D”时,反推这个分布D的规律,最终得到真相。
-
举个例子就是上面我们所谈的到的那堆西瓜,一筐篮子装着,这个篮子就是样本空间,每个西瓜就是一个个样本,当这些西瓜身上的每个特征或者我们所需的特征所反映出来的这是个好瓜还是坏瓜的规律,它服从一个分布,如果我的西瓜足够多,那么特征信息足够丰富,最终这个分布便会更加清晰而接近所谓的真相。
1.11监督学习与非监督学习
-
监督学习就是指我已知结果的分析。例如:这堆西瓜告诉了我好坏,我可以进行分析。
-
非监督学习就是指我不知结果的分析。例如:不告诉我这堆西瓜的好坏,但是我可以对这些西瓜进行聚类,按照产地,大小,颜色等进行分析。
2.假设空间
即书中提到的例子中我们用来预测房价时的不同的模型(函数),有线性回归和多项式回归等模型来预测。
那么这里的两个回归即是两个不同的假设空间。
即是指所有能够拟合训练集的模型的集合即为版本空间。
3.归纳偏好
-
就是指不同的机器学习有不同的偏好,例如:在房价预测项目当中,选用一元线性回归算法,得到一元一次函数模型,那选用多项式回归算法,得到了二元一次函数的模型,那么要是说谁好谁坏,也遵循“奥卡姆剃刀”原则,当多个假设与观察一致,就选择最简单的那个。但是具体上需要模型在基于数据集的最终表现上来判断其模型的好坏。你的偏好更取决于你的实际问题。
4.NFL定理(没有免费的午餐)
-
重要前提:所有问题出现的机会都相同,或者所有问题同等重要。
-
即一个算法a若在某些问题上比b好,那么就必然b在某些问题比a要好。
-
故在没有任何前提或者背景的条件下去谈算法是没有意义的。
5.过拟合与欠拟合
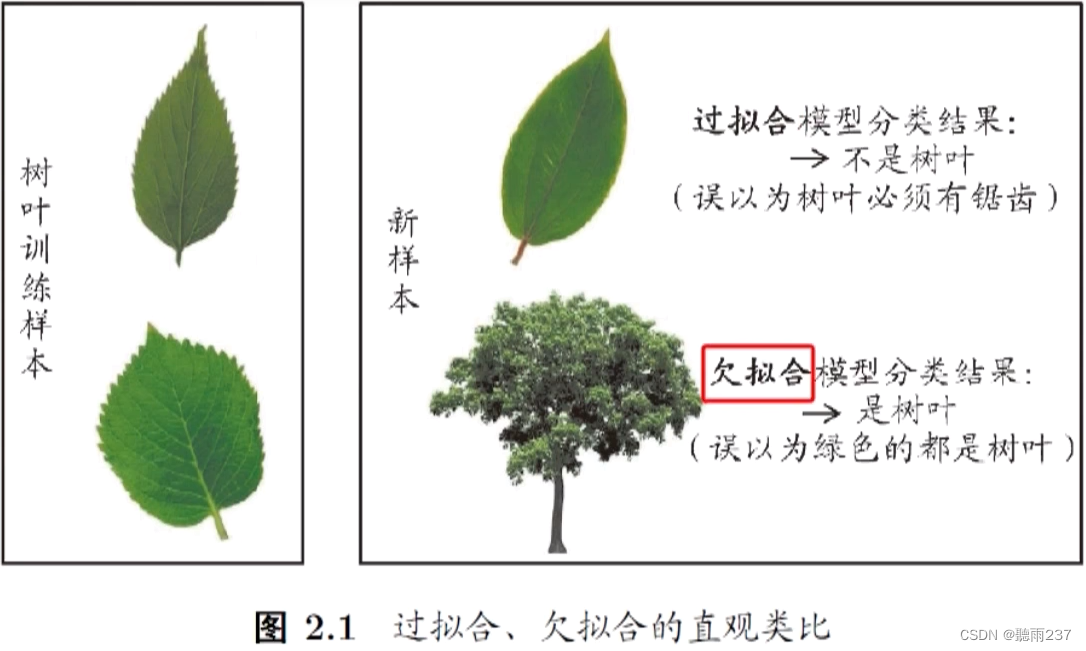
-
过拟合:错误的把某些特征当成了一般规律,学得太多,例如上面错误地把树叶都要有锯齿才叫树叶。这就是一种过拟合。
-
欠拟合:与过拟合相反,学的太少,例如上面的把只要是绿色的都看作树叶。这种情况就是欠拟合。
6.调参与最终模型

7.模型选择的三个关键问题


-
评估方法:
留出法:
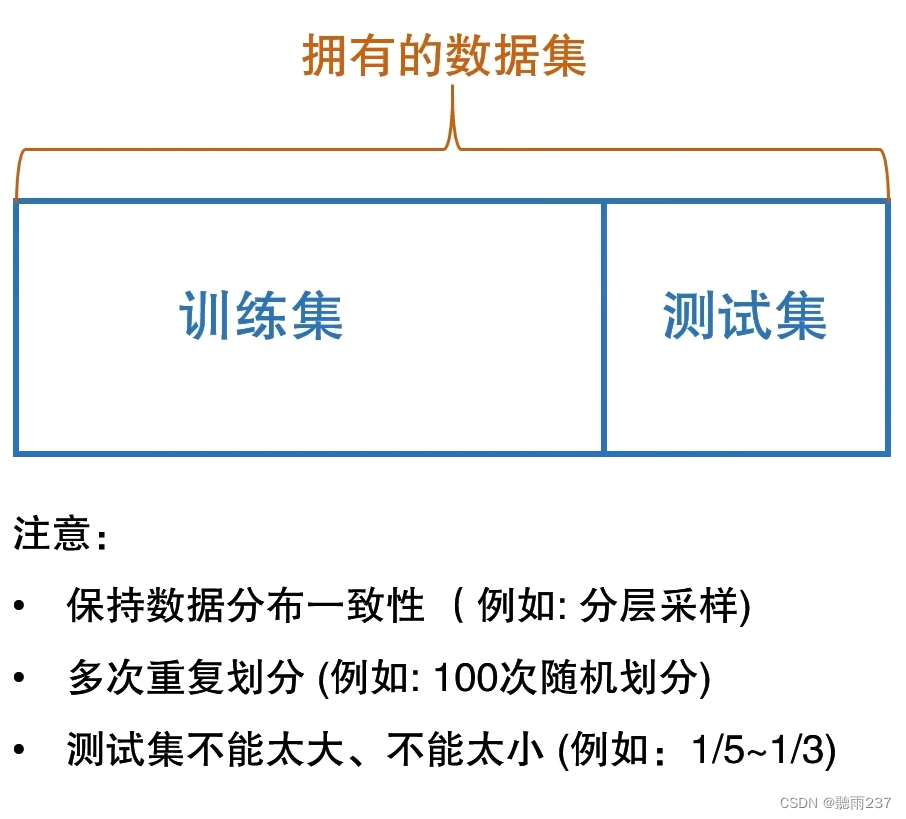
交叉验证法:

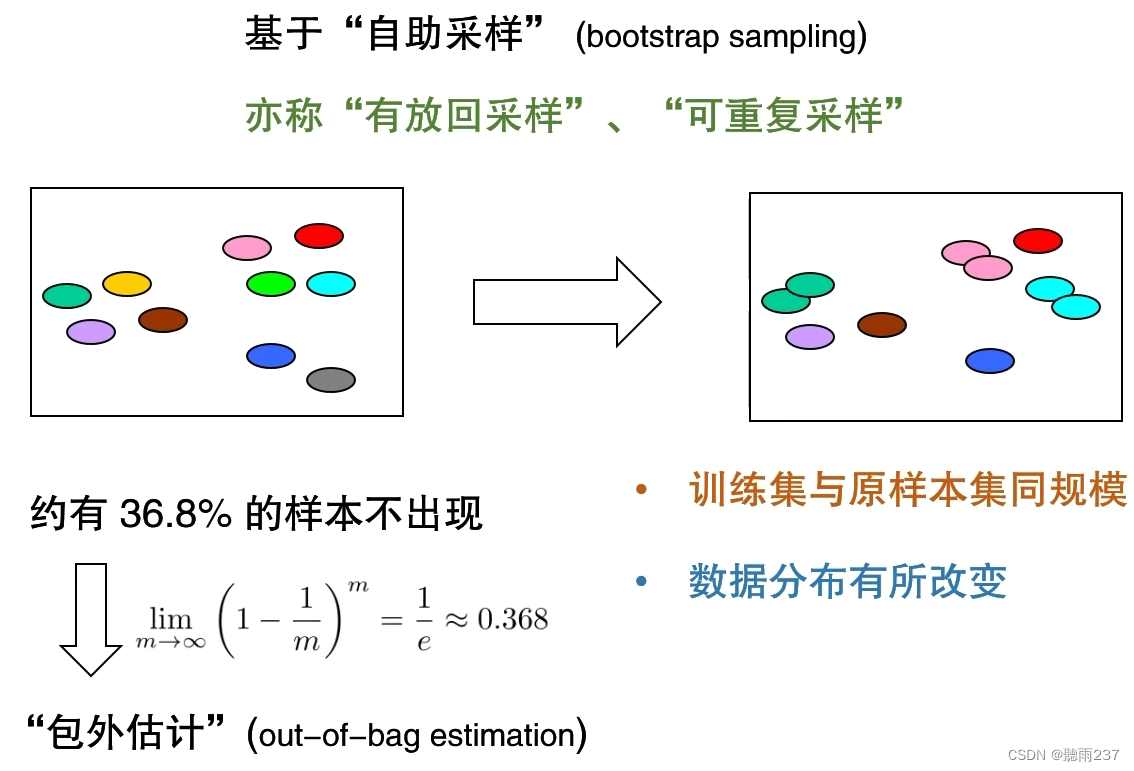
自助法:
2.性能度量

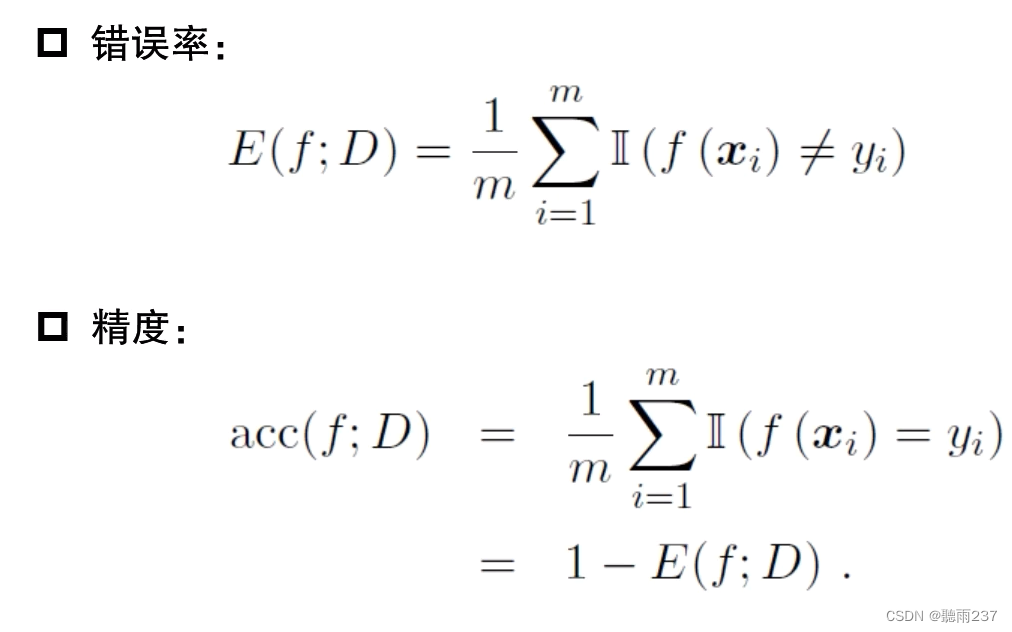
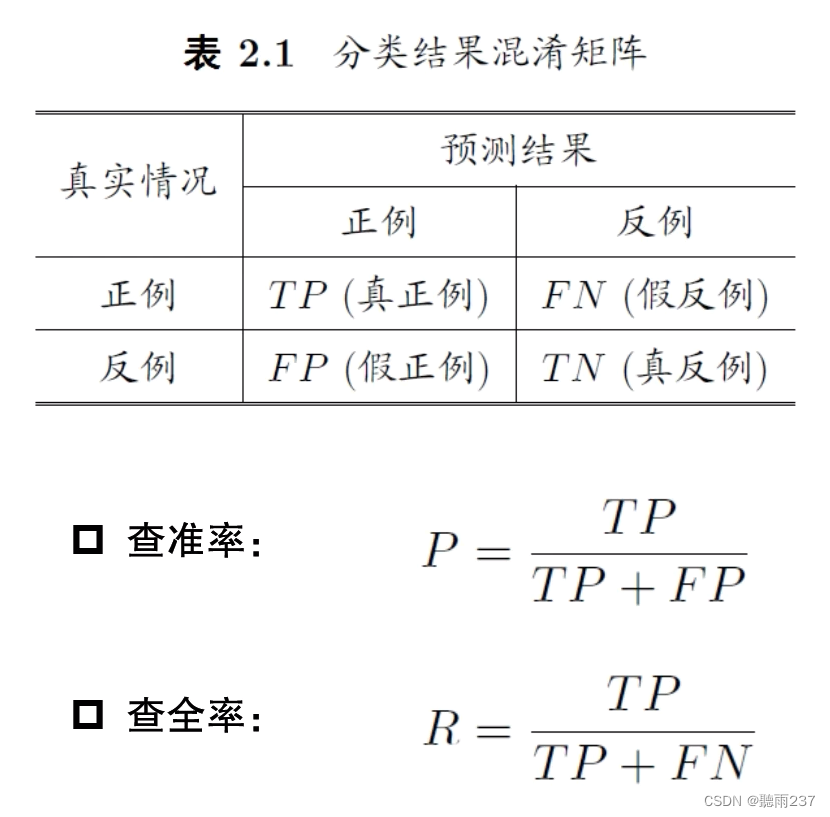
注意:上面的表中解释:就是给我预测的是正确的,但实际也是正确的,同理,预测是错误的,但实际正确的。这样理解。
还有就是查准与查全,举个例子:100个西瓜预测了10个是好的给我,那么实际上有几个是好的,这就是查准率,查全讲的就是这里面有20个是好的,但是你只给我10个。这是查全。

3.比较检验:


此内容是本人第一次通过看书和相关视频学习周志华《机器学习》,在此发表的一些个人的看法与见解,如有错误在里面必然是本人见识低陋,望读者朋友务必指出,我好加紧改正。本内容仅仅是本人学习的记录。想要深入了解《机器学习》的朋友务必下去看看书。谢谢。
参考说明:
相关截图:来自b站 周志华老师亲讲-西瓜书全网最详尽讲解-1080p高清原版《机器学习初步》BV1gG411f7zX
【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集 BV1Mh411e7VU















 8981
8981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









