






#该内容是本人在系统学习机器学习过程中的所思所感#
#如有问题请多多指出哦#
在机器学习和数据分析中,评估模型性能的标准有很多,而均方误差(Mean Squared Error,简称MSE)是最常用的评估回归模型好坏的指标之一。MSE反映了模型预测值与真实值之间的差异,广泛应用于回归分析(拟合)、神经网络训练以及其他需要最小化误差的任务。本文将全面解读均方误差的概念、公式、优缺点以及实际应用。
什么是均方误差(MSE)?
均方误差(MSE)是指预测值与真实值之间差异的平方和的平均值。它是回归问题中常用的损失函数,用于衡量模型预测值和真实值之间的误差大小。MSE的核心思想是计算预测值与实际值之间差异的平方,然后求平均,得到一个数值,反映模型的预测准确性。
均方误差的公式
均方误差的公式如下:
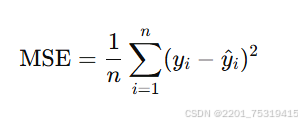
其中:
- n是样本数,表示数据集中的总样本量。
- yi是第 i个样本的真实值。
- y^i 是第 i个样本的预测值。
简而言之,MSE就是所有样本的预测误差平方的平均值。它在计算时首先会对每个预测值和真实值的差进行平方,然后求和并求出平均数。
为什么选择平方差?
为什么MSE使用平方而不是直接使用误差的绝对值或其他形式?这背后有几个原因:
-
惩罚较大的误差:平方项会让大的误差得到更强的惩罚,而小的误差则不会被过度放大。通过平方,模型会更加注重减小那些较大的预测误差,从而提高整体的预测准确性。
-
数学推导简洁性:平方差函数具有连续性和可导性,便于进行优化算法的推导与实现。特别是在梯度下降法等优化算法中,MSE是一个非常合适的损失函数。
-
便于计算和理解:MSE的单位是原始数据单位的平方,这样使得误差的量化变得明确且易于理解。虽然单位是平方的,但平方差能够给出更加稳定且有规律的优化方向。
MSE的优缺点
优点:
- 数学简洁性:MSE非常简洁,易于计算,且与许多优化算法(如梯度下降)兼容。
- 强惩罚性:MSE对较大的误差有很强的惩罚性,使得模型更专注于减小大的误差,有助于提升模型的准确度。
- 连续可导性:MSE是一个连续的二次函数,这使得它在优化时更容易进行梯度计算,便于模型训练和参数优化。
缺点:
- 对离群点敏感:MSE对于离群点(Outliers)非常敏感。由于平方项的存在,异常值会导致损失值迅速增大,影响模型的稳定性和准确性。
- 不适合处理非正态分布数据:如果数据不符合正态分布,MSE可能不太适合,因为它假设误差的分布是对称的且遵循正态分布。当误差分布偏斜时,MSE可能不能很好地捕捉模型性能的真实情况。
MSE与其他误差度量的比较
除了MSE,回归问题中常用的误差度量方法还包括均方根误差(RMSE)、**平均绝对误差(MAE)**等。我们可以将它们进行比较:
-
均方根误差(RMSE):RMSE是MSE的平方根,因此与原始数据单位一致,具有更直观的物理意义。如果MSE过大,RMSE的单位与数据一致,便于对误差的解释。
-
平均绝对误差(MAE):MAE是误差的绝对值的平均。与MSE相比,MAE对于离群点不那么敏感。虽然MAE对异常值的鲁棒性较强,但它在优化过程中没有平方误差的强惩罚性,因此可能不如MSE更有效地提高模型的准确性。
实际应用中的MSE
-
模型评估:在回归问题中,MSE被广泛用于评估模型的性能。在模型训练时,MSE通常作为损失函数进行优化,通过最小化MSE来让模型更接近真实的输出。
-
算法优化:在机器学习中的梯度下降法和其他优化算法中,MSE是一个常见的目标函数。由于其可导性,MSE使得优化过程更加稳定且可计算。
-
神经网络训练:在深度学习中,MSE常用于回归任务的神经网络训练。例如,预测数值型目标(如股价、温度等)时,MSE作为损失函数来评估和优化模型。
-
模型对比:MSE有助于不同回归模型(如线性回归、决策树回归、随机森林回归等)的比较。在训练多个模型时,可以使用MSE作为标准来比较各个模型的表现。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









