






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。当哲学课上老师问你什么是科学,什么是电的时候,不要觉得这些问题搞笑。哲学是科学之母,哲学就是追究终极问题,寻找那些不言自明只有小孩子会问的但是你却回答不出来的问题。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能让人胸中升起一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它居然给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
文献来源yyds:

聚类分析是数据挖掘的主流技术之一,它在人工智能领域有着广泛应用。簇的定义和聚类方法的双重多样性致使数据科学发展过程中聚类算法拥有“数量庞大”“类型多样”等特点。一般而言,能将无标签的样本点聚为若干个簇的算法都可以称为聚类算法,人们常根据这些算法的基本思想或基本假设将其分为几个常见的类型:分割聚类法、层次聚类法、密度聚类法、网格聚类法、模型聚类法等。该文提出了一类基于局部中心量度的聚类算法,其创造性成果主要体现在:
- 首创性地提出了局部中心量度的概念。局部中心量度是衡量空间中任意点的局部中心程度的量,聚类过程中区分中心区域的点和边缘区域的点有赖于正确估计出样本点的局部中心程度。该文认为,密度聚类算法中选用的样本点密度起着局部中心量度的作用:密度高于预先设定的阈值的样本点被划分为核心区域的点,而密度低于阈值的样本点被划分为边缘区域的点,它们之间相互连接形成最终的聚类结果。经验上,样本点密度较大的区域通常是簇中心区域,而样本点密度较小的区域通常是簇边缘区域。因而,有着完善的数学理论基础的样本点密度最先成为局部中心量度被广泛应用。然而,样本点密度作为局部中心量度存在着缺陷:密度阈值难以先于经验给出,这将导致以样本点密度为局部中心量度的聚类算法对参数敏感;不同的簇可能有着相差较大的最佳阈值,这将导致以样本点密度为局部中心量度的聚类算法难以处理不平衡问题。因此,人们需要设计新的局部中心量度。
- 设计了多个局部中心量度。局部中心量度的准确性直接影响到聚类结果的正确性,一个良好的局部中心量度除了能够正确反映样本点的真实局部中心程度外还需要考虑:局部中心量度的稳定性,即不论应用于何种分布的数据,区分中心区域和边缘区域的样本点的阈值相对稳定,易于算法参数的选取,降低算法对参数的敏感度;局部中心量度的健壮性,即计算结果不易受数据分布的不平衡性影响。该文分别从mean shift和局部引力模型出发,设计了稳定性和健壮性更强的局部中心量度。
- 提出了局部引力模型和新的聚类算法。基于局部引力模型,该文借助不同的局部中心量度间的多样性,同时使用多个局部中心量度,提出了LGC算法和CLA算法。新提出的聚类算法具有易于调参,结果准确等特点。
- 设计了适用于多性能指标体系下的非参数检验方法。衡量聚类算法性能的指标较多,常见的有RI、ARI、NMI等。多种指标之间的数值相互直接比较是没有意义的,如就算法甲的RI值和算法乙的NMI值进行直接比较是没有意义的。该文采用秩转化的方法,提出了三种不同的计算秩的方法,将不同的性能指标对应的具体数值转化为秩值,通过对秩值进行统计检验完成多性能指标的融合。
关键词:局部引力模型;密度聚类算法;局部中心量度;LCM聚类算法;LGC聚类算法;CLA聚类算法
结论:
本文提出的基于局部中心量度的聚类算法是聚类技术的新分支。尽管基于局部中心量度的聚类算法与密度聚类算法在思想方法上有诸多相似之处,但它们之间依旧存在着较大的区别。局部中心量度是一个更为一般化的概念,局部密度可能是聚类技术在发展过程中最早使用的局部中心量度。局部密度作为当前使用最广泛的局部中心量度有着一定的必然性:核密度估计法有着较完善的数学基础因而较容易推广到模式识别领域;聚类中高密度区域在大多数情况下是簇的中心区域。本文的主要结论如下:
- 基于mean shift的局部中心量度//和基于局部引力模型的局部中心量度CE/CO在恰当的参数下可以很好地表征样本点的局部中心程度;
- 相比局部密度,和CE更适合处理不平衡问题,同时更容易找到合适的阈值以区分簇中心区域和簇边缘区域的点;
- LGC算法和CLA算法能发现任意形状的簇,且相对容易寻找到合适的参数以获得理想的结果;
- LGC算法和CLA算法在人工数据集和真实世界数据集中都取得了较好的聚类结果,既适用于二维数据集,也适用于高维数据集;
- GRA-FT和WGRA-FT可以应用于多性能指标体系中的评价问题。
局部中心量度和基于局部中心量度的聚类算法还有诸多有待发展和完善之处,本文作如下展望:
- 未来的工作中我们还需要设计新的局部中心量度,它们会朝着更低的时间复杂度、更低的参数敏感性、更好的局部中心程度表征能力的方向发展;
- 类似于核密度估计法,局部中心量度在尝试更广泛地应用于求解模式识别问题的过程中也需要更为深入的数学理论研究作支撑,更为一般化的局部中心量度估计方法也是我们后续工作的一个方向;
- 设计新的基于局部中心量度的聚类算法,这些算法需要有更低的时间开销、更好的聚类效果、更少的人工设置;
- 设计更适用于特定问题的局部中心量度及相应的聚类算法,如专用于特定类型的数据集的局部中心量度。

摘要:
聚类分析的目标是根据适当的距离度量将一组数据点分成几个群组。我们首先提出了一个称为数据点之间的局部引力的模型。在这个模型中,每个数据点被看作具有质量的对象,并与其邻居产生的局部结果力(LRF)相关联。本文的动机是因为靠近聚类中心和在聚类边界处的数据点的LRF之间存在明显差异(包括大小和方向)。为了有效捕获这些差异,进一步研究了两个名为中心性和协调性的新局部度量。基于经验观察,设计了两种新的聚类方法,分别称为局部引力聚类和与本地代理通信,并进行了几个测试案例以验证它们的有效性。对合成数据集和真实世界数据集的实验表明,这两种聚类方法在大多数数据集上表现良好。
聚类是数据挖掘领域的主要技术之一,具有广泛的应用[1]–[10], [69], [70],例如人脸识别[1], [2]、基于癌症基因表达谱的肿瘤聚类[3], [4]、亚像素图像分割[5]、文档聚类[6], [7]、僵尸网络入侵检测[8]、软件环境丰富化[9]、声源定位[10]等。聚类分析的主要任务是根据适当的距离度量将一组数据点划分为紧密组织的群组[11]。已经提出了各种算法来处理聚类任务,可以按连通性、分布性、质心、密度等方式分类。然而,通常很难对聚类算法进行分类。例如,均值漂移聚类方法[12]基于密度梯度分析,其中每个数据点迭代地朝向其局部密度峰值(DP)移动,而一些类似于K均值的聚类算法通常可以看作是均值漂移算法的特例。此外,最大熵聚类算法[13]也是一种基于统计物理的聚类方法,同时也是一种基于特殊核的均值漂移算法。这些算法在群组定义和聚类策略上有显著差异,在实际应用中各自有其局限性。基于连通性的聚类算法通过连接数据点来构建群组,通常需要高计算成本并且容易受到异常值的影响[14]。基于模型的方法,如高斯混合模型需要预先指定混合成分的参数概率密度函数形式[15]。K均值[16]和K中心点[17]算法可能是最知名的基于质心的聚类算法,在这些算法中,一个群组被定义为一组数据点,这些点位于与群组中心相关联的区域内。具体而言,这类算法首先初始化一组随机选择的群组中心,然后优化数据点到中心的平方距离[16]–[19],直到识别出最佳的群组中心候选者。然而,由于分区聚类算法未能考虑数据点及其邻居之间的局部关系,因此通常无法检测具有任意形状的群组[20]。作为密度算法的代表,基于密度的空间聚类应用及噪声(DBSCAN)[21]利用数据点的局部密度信息进行聚类,使其能够检测具有任意形状的群组。密度聚类算法的一个缺点是对所有数据样本的密度估计通常是耗时的,因此提出了一些混合聚类算法[22], [23]来解决这个问题。
📚2 运行结果
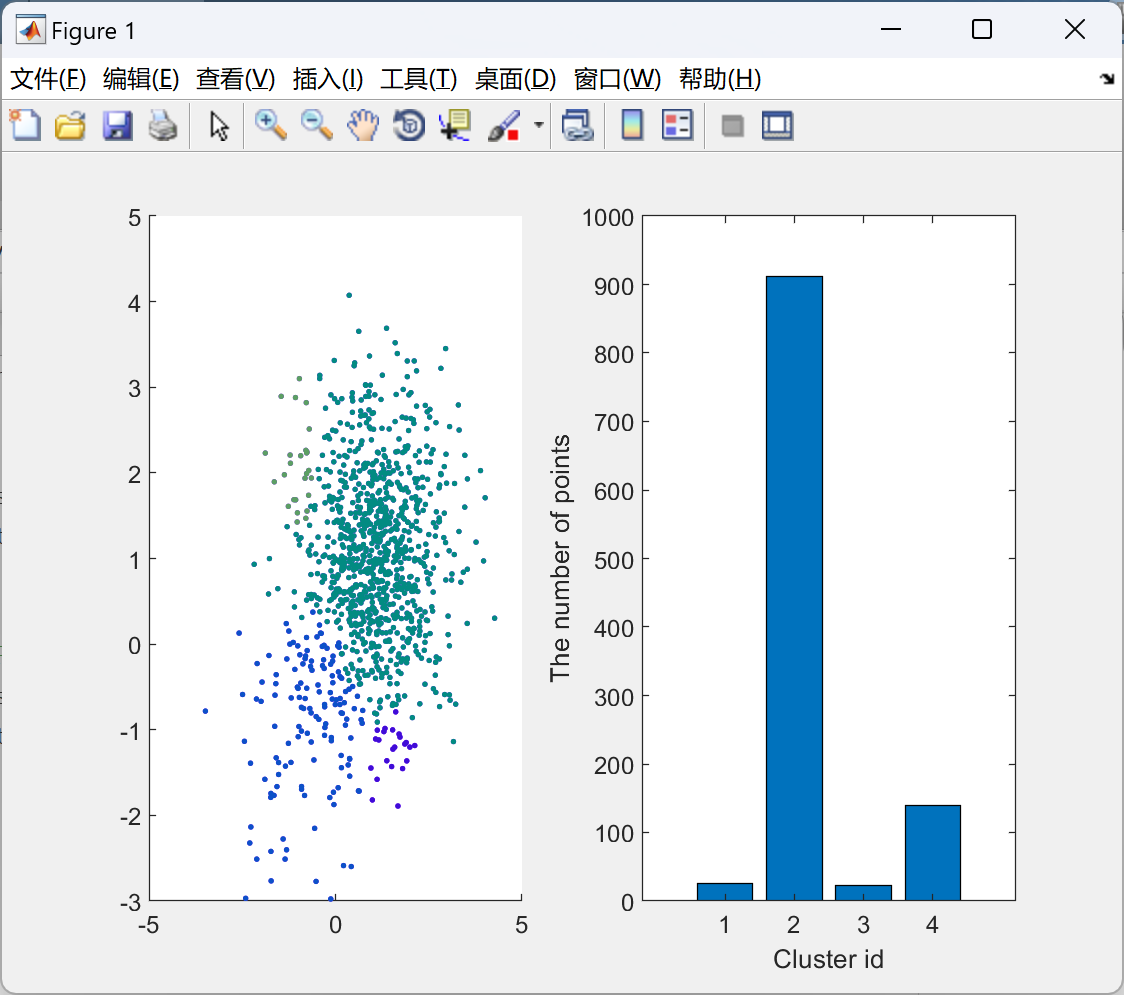

部分代码:
function []=plot_cluster(Xlabel,cNums,dataset)
cla;
fprintf('%d clusters find: \n', cNums);
clusterNums=zeros(cNums,1);
if size(dataset,2)==2
cla
subplot(1,2,1);
hold on
for k=1:cNums
plot(dataset(Xlabel==k,1),dataset(Xlabel==k,2),'.','color',[rand(),rand(),rand()]);
clusterNums(k)=sum(Xlabel==k);
disp(['Cluster ',num2str(k), ': ', num2str(clusterNums(k)),' data points.']);
end
plot(dataset(Xlabel==0,1),dataset(Xlabel==0,2),'kx');
nulCluster=sum(Xlabel==0);
disp(['Noise points: ', num2str(nulCluster),' data points.']);
subplot(1,2,2);
bar(clusterNums);
xlabel('Cluster id');
ylabel('The number of points');
else
for k=1:cNums
clusterNums(k)=sum(Xlabel==k);
disp(['Cluster ',num2str(k), ': ', num2str(clusterNums(k)),' data points.']);
end
nulCluster=sum(Xlabel==0);
disp(['Noise points: ', num2str(nulCluster),' data points.']);
bar(clusterNums);
end
end
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]王志强.基于局部中心量度的聚类算法研究[D].华南理工大学,2018.
[2]Z. Wang et al., "Clustering by Local Gravitation," in IEEE Transactions on Cybernetics, vol. 48, no. 5, pp. 1383-1396, May 2018, doi: 10.1109/TCYB.2017.2695218.
🌈4 Matlab代码、Word论文、Pdf论文
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取
















 3899
3899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









